Архитектурсистем планирования и метапланирования
15.2. Архитектура систем планирования и метапланирования
Экспертная система MOLGEN, предназначенная для планирования экспериментов в исследованиях по молекулярной генетике, имеет многоуровневую организацию, в которой каждый более верхний уровень управляет расположенными ниже. Такой вид организации экспертной системы получил в литературе название метауровневой архитектуры (meta-level architecture). Идея состоит в том, что в дополнение к представлению "первого уровня" проблемы в предметной области добавить еще более высокие уровни, представляющие такие понятия, как возможные действия с объектами предметной области, критерии выбора и комбинирования таких действий.
В терминологии системы MOLGEN уровни управления называются пространствами планирования (planning space). Программа использует три таких пространства, каждое из которых имеет собственные объекты и операторы, которые взаимодействуют друг с другом с помощью протоколов передачи сообщений (см. главу 7). Схематически организация уровней управления в системе MOLGEN представлена на рис. 15.1. На этой схеме в левой части прямоугольников, представляющих каждое пространство планирования, приведен список некоторых операторов этого пространства. Интерпретатор организует внешний цикл управления системой. Фактически он формирует и следит за соблюдением определенной стратегии поведения системы. Как будет показано ниже, в этих стратегиях реализуется логический вывод суждений на метауровне, которые управляют способом решения проблемы планирования эксперимента.
Мы начнем анализ архитектуры системы MOLGEN с самого нижнего уровня — пространства лабораторных экспериментов (laboratory space). В этом пространстве содержатся знания об объектах и операциях, выполняемых в лаборатории в процессе проведения экспериментов. Объектами этого пространства являются те сущности, которыми манипулируют лаборанты, а операторы — это те действия, которые с этими сущностями могут выполняться, например сортировка, слияние и т.д. Мы не будем подробно останавливаться на этом уровне.
Читатели, которых интересуют подробности его организации, могут обратиться к статьям Стефика [Stefik, 1981, а] и [Stefik, I981, b].
Пространство разработки (design space) содержит знания о планах проведения экспериментов в форме классов операторов для выполнения следующих действий:
проверки прогнозируемых характеристик и выявления необычных характеристик объектов — операторы сравнения (comparison-operators),
формирования предложений относительно целей, операций и прогнозируемых результатов — операторы временного расширения (temporal-extension operators);
уточнения этапов плана в соответствии с имеющимися ограничениями — операторы специализации (specialization operators).
Например, оператор Propose-Goal (предложение цели) относится к группе операторов временного расширения и устанавливает для лабораторного пространства цели проведения экспериментов. Оператор Check-Prediction (проверка прогнозируемых результатов) относится к группе операторов сравнения и выполняет сравнение прогнозируемых результатов экспериментов с текущей целью. Оператор Refine-Operator (уточнение) входит в группу операторов специализации. Он заменяет в форме уточняемого плана абстрактные этапы в операциях пространства лабораторных экспериментов на более конкретные.

Рис. 15.1. Организация пространств планирования в системе MOLGEN ([Stefik, 1981,b])
Каждому оператору назначается определенный уровень приоритета. Как правило, операторы сравнения имеют более высокий приоритет, чем операторы временного расширения, а последние имеют приоритет перед операторами специализации. Такое ранжирование операторов является, по существу, одним из отражений стратегии наименьшего принуждения, поскольку операции с более высоким приоритетом, как правило, оставляют большую свободу действий на будущее, чем операторы с более низким приоритетом. В той предметной области, для которой предназначена система MOLGEN, с помощью этих операторов моделируется экспертность специалистов, разрабатывающих эксперименты, но общие принципы организации этой системы вполне применимы и в других областях проектирования и планирования.
Большую роль в системе MOLGEN (как, впрочем, и в других приложениях, предназначенных для решения проблем конструирования) играют следующие три операции с ограничениями.
Формулирование ограничений. Эта операция формирует ограничения для пространства решений. Если воспользоваться примером из области планирования компоновки помещений, то такой операцией будет принятие решения, что кухня и столовая должны быть расположены рядом.
Распространение ограничений. Эта операция организует передачу информации между подзадачами, которые являются в определенной мере независимыми. Например, компоновка помещений на верхнем и нижнем этажах коттеджа является почти независимыми задачами, но они связаны друг с другом наличием одних и тех же ограничений в виде расположения лестниц и элементов водопроводной системы.
Удовлетворение ограничений. Эта операция собирает информацию об ограничениях, извлекая ее из деталей реализации отдельных подзадач проектирования. Например, при планировке помещений можно попробовать подгонять планировку верхнего и нижнего этажей таким образом, чтобы облегчить выполнение подзадачи планирования системы водоснабжения.
Полезно попытаться охарактеризовать отдельные операции в терминах тех ограничений, которые на них накладываются. Например, если проблема состоит в том, чтобы выяснить, что делать сегодня вечером, а текущая операция — это "пойти в кино", то можно сказать, что эта операция недоопределена (underconstrained), если в городке есть более одного кинотеатра. В более общем смысле операция является недоопределенной, если отсутствует вся необходимая информация для того, чтобы эта операция могла быть однозначно реализована в терминах более детальных этапов. Но операция "пойти посмотреть фильм-ужастик" является переопределенной (overconstrained), если в городке нет ни одного кинотеатра, в котором бы шел такой фильм. В более общем смысле операция является переопределенной в том случае, если любая попытка выполнить ее приводит к нарушению наложенных ограничений.
Назначение пространства стратегий (strategy space) — выработка суждений об этапах плана в пространстве разработки. Основным инструментом для этого являются эвристики стратегии наименьшего принуждения. Если операторы пространства разработки отвечают за формирование последовательности этапов выполнения в предметной области, то операторы пространства стратегий отвечают за формирование последовательности выполнения операторов пространства разработки. Таким образом, можно утверждать, что операторы этого пространства выполняют метапланирование.
Пространство стратегий системы MOLGEN состоит из следующих операторов, которые мы будем описывать в терминах сообщений, передаваемых сущностям управляемого пространства разработки.
Оператор Focus посылает сообщение "find task" каждому оператору пространства разработки, побуждающее его найти такую задачу, которую этот оператор мог бы выполнить в развитии текущего плана. Затем предлагаемые операции включаются в список и сортируются в порядке приоритетов соответствующих операторов. Не все из этих операций могут быть действительно выполнены. Некоторые из них недоопределены, а другие— переопределены. Оператор Focus просматривает сформированный список и выполняет те задачи, которые могут быть выполнены, отсылая после каждого успешного выполнения сообщение "find task". Если обнаруживается недоопределенная задача, ее выполнение приостанавливается. Когда же будет обнаружена переопределенная задача, управление передается оператору Undo.
Оператор Resume во многом похож на оператор Focus. Отличие состоит в том, что он не формирует новые задачи, а старается выявить ранее приостановленные и повторно запустить их на выполнение.
Оператор Guess активизируется в том случае, когда оказывается, что все предлагаемые для дальнейших действий задачи являются недоопределенными. Возникает ситуация, когда обычный "регулярный" подход на основе стратегии наименьшего принуждения не позволяет определить следующее действие и нужно привлекать на помощь эвристики.
Оператор Guess посылает каждой приостановленной задаче сообщение, предлагая оценить степень "полезности" опций, которыми располагает эта задача, а затем выбирает ту из них, у которой самый высокий рейтинг.
Оператор Undo активизируется, когда обнаруживается, что в план включена переопределенная задача. В этом случае складывается ситуация, в которой нельзя применить стратегию наименьшего принуждения. В том виде, в каком он реализован в системе MOLGEN, оператор Undo выглядит довольно примитивным. Он отыскивает тот этап, который привел к включению в план переопределенной задачи, и предлагает изъять его из плана.
В системе MOLGEN список актуальных операторов используется более гибко, чем в системах INTERNIST и CENTAUR, описанных в главе 13. Хотя во всех трех системах разделяется предложение задач к выполнению и их реальное выполнение, только архитектура MOLGEN позволяет задачам взаимодействовать нетривиальным способом. Как отметил Стефик (Stefik), если такое взаимодействие не организуется явным образом на более, высоких уровнях, оно может привести к весьма неожиданным результатам на более низких. Естественно, многоуровневая архитектура должна существенно упростить решение проблемы, если в ней правильно выполнено распределение нагрузки по уровням. По мере перехода на более высокие уровни решаемые задачи должны упрощаться. На самом высоком уровне, уровне интерпретатора, решается единственная тривиальная задача запуска на выполнение той подзадачи, которая стоит первой в списке актуальных.
Как уже отмечалось, основной "слабостью" системы MOLGEN является то, что в ней отсутствует достаточно совершенный механизм обратного прослеживания. Другими словами, если вспомнить о наименовании стратегии предложение и пересмотр, то эта система сильна в выработке предложений, но слаба в их пересмотре, а потому ей не всегда удается "выкарабкаться" из ситуации, которая складывается после неудачного предложения.
В следующем разделе будет описана экспертная система, в которой используется та же парадигма предложение и пересмотр, но процесс пересмотра реализован более удачно.
15.1. Программа планирования мероприятий
Ниже приведена программа планирования мероприятий, написанная на языке CLIPS. При сформировании расписания программа сначала старается как можно раньше назначить для каждого отдельного мероприятия начальный момент выполнения, а затем назначает конечный момент, если в расписании найдено место для мероприятия. Программа расставляет задачи в соответствии с их приоритетами и старается сохранять себе свободу действий как можно дольше. Однако эта программа не способна справиться с ситуацией, которая складывается после неудачно принятого решения, ни с помощью обратного прослеживания, ни с помощью коррекции частичного расписания, из которого развился тупиковый вариант.
;; ШАБЛОНЫ
;; Объект мероприятий.
(deftemplate errand
(field name (type SYMBOL)) ; имя
;; интервал времени, в течение которого нужно
;; приступить к выполнению мероприятия
;; не раньше (field earliest (type INTEGER) (default 0))
;; не позже
(field latest (type INTEGER) (default 0))
;; продолжительность
(field duration (type INTEGER) (default 0))
;; приоритет
(field priority (type INTEGER) (default 0))
;; включено в расписание (field done (type SYMBOL)
(default no));
)
; ; Объект расписания (def template schedule
(field task (type SYMBOL))
;; задача
;; интервал времени, в течение которого нужно
;; выполнить задачу
;; начало
(field start (type INTEGER) (default 0))
;; конец
(field finish (type INTEGER) (default 0))
;; приоритет
(field priority (type INTEGER) (default 0))
;; полностью заполнено
(field status (type SYMBOL) (default no))
)
;; Объект цели. Используется для управления поведением
;; программы, принуждая ее к определенному порядку
;; достижения целей. (def template goal
(field subgoal (type SYMBOL)))
;; ФАКТЫ
(deffacts the-facts (goal (subgoal start))
(errand (name hospital) (earliest 1030)
(latest 1030)
(duration 200) (priority 1)) (errand
(namе doctor) (earliest 1430) (latest 1530)
(duration 200) (priority 1))
(errand (name lunch) (earliest 1130) (latest 1430)
(duration 100) (priority 2))
(errand (name guitar-shop)
(earliest 1000)
(latest 1700) (duration 100)
(priority 3)) (errand (name haircut)
(earliest 900) (latest 1700)
(duration 30) (priority 4))
(errand (name groceries)
(earliest 900) (latest 1800)
(duration 130) (priority 5))
(errand (name dentist)
(earliest 900) (latest 1600)
(duration 100) (priority 2))
;; Попадает ли время начала S в интервал [Т, T+D]?
;; Две задачи не могут начинаться в одно и то же время.
(deffunction overlapl (Is ?t ?d)
(and (<= ?t ?s) (< ?s (+ ?t ?d))))
;; Попадает ли время завершения S в интервал [Т, T+D]?
;; Для задачи А можно назначить время начала выполнения
;; равным времени завершения задачи В.
(deffunction overlap2 (?s ?t ?d)
(and (< ?t ?s) (< ?s (+ ?t ?d))))
;; Операция добавления к значению времени интервала,
;; выраженного в формате INTEGER,
(deffunction +t (?X ?Y) (bind ?T (+ ?X n))
(if(or (= (- ?T 60) ( (div (- ?T 60) 100) 100))
(= (- ?T 70) ( (div (- ?T 70) 100) 100))
(= (- ?T 80) ( (div (- ?T 80) 100) 100))
(= (- ?T 90) ( (div (- ?T 90) 100) 100)))
then (+ ?T 40)
telse ?T))
;; ПРАВИЛА
;; На выполнение некоторых задач отводится
;; фиксированное время, (defrule fixed
(declare (salience 80))
(goal (subgoal start))
?E <- (errand (name ?N)
(earliest ?T) (latest ?T) (duration ?D)
(priority ?P) (done no))
(not (schedule (start ?U1&:(overlapl ?U1 ?T ?D))))
(not (schedule (finish ?U2&:(overlap2 ?U2 ?T ?D))))
(printout t crlf "Fixing start and end of " ?N t crlf)
;; ( "Определение начала и завершения " ?N
(modify ?E (done finish)) (assert (schedule (task ?N)
(start ?T) (finish (+t ?T ?D)) (priority ?P)))
;; Следующей в расписание включается задача с наиболее
;; высоким приоритетом, причем ей задается самое раннее
;; время начала выполнения, (defrule priorityl
(declare (salience 50))
(goal (subgoal start))
: ?Е <- (errand (name ?N) (earliest ?T)
(duration ?D) (priority ?P)) (not (errand
(priority ?Q&:(< ?Q ?P)) (done no)))
(not (schedule (start ?01&:(overlapl ?Ul ?T ?D))))
(not (schedule (finish ?U2S:(overlap2 ?U2 ?T ?D))) =>
(printout t crlf "Fixing start of " ?N t crlf)
;;"Коррекция начала: " ?N
(modify ?E (done start)) (assert (schedule
(task ?N) (start ?T) (priority ?P)
)
;; Скорректировать значение параметра earliest задач
;; более низкого приоритета, если это время уне занято
;; теми задачами, которые включены в расписание,
(defrule priority2
(declare (salience 60))
(goal {subgoal start)) ?E <- (errand (name ?N)
(earliest ?T)(duration ?D) (priority ?P) (done no))
(not (errand (priority ?QS:(< ?Q ?P)') (done no)))
(schedule (task ?M) (start ?U&:(overlapl 7U ?T ?D)))
(errand (name ?M&~?N) (duration ?C)) =>
(printout t crlf ?N " overlaps with start of " ?M t crlf)
;; ?N " пересекается с началом " ?M
(modify ?E (earliest (+t ?U ?C))) )
;; Скорректировать значение параметра earliest задач
;; более низкого приоритета, если запуск задачи в
;; указанное этим параметром время приведет к тому,
;; что она не успеет завершиться до запуска другой
;; задачи более высокого приоритета,
;; ухе включенной в расписание,
(defrule priority3
(declare (salience 60))
(goal (subgoal start))
?E <- (errand (name ?N) (earliest ?T)
(priority ?P) (done no))
(errand (name ?M&"?N) (duration ?C))
(schedule (task ?M)
(start ?0&:(overlap1 ?T ?U ?C)))
(printout t crlf ?N " overlaps with end of " ?M t crlf)
;; ?N " пересекается с концом " ?M
(modify ?E (earliest (+t ?U ?C)))
)
;;Скорректировать значение параметра earliest
;; задач более низкого приоритета,
;;если запуск задачи в указанное этим
;;параметром время приведет к тому,
;; что ее начало перекроет одну
;;задачу, уже включенную
;; ранее в расписание, и она не успеет завершиться
;; до запуска другой задачи более высокого приоритета ,
;; уже включенной в расписание.
(defrule priority4
(declare (salience 60))
(goal (subgoal start))
?E <- (errand (name.?N) (earliest ?T)
(duration ?D) (priority ?P) (done no))
(errand (name ?M&~?N) (duration ?C))
(schedule (task ?M)
(start ?U&:(<= ?U ?T)) (finish ?F&:
(<= (+ ?T ?D) ?F)))
)
=>
(printout t crlf ?N " would
occur during " ?M t crlf)
?N " может появиться во время "
?М (modify ?E (earliest (+t ?U ?C)))
)
;; Изменение цели. Новая цель - установка конечного
;; времени выполнения задачи. (defrule change-goal
?G <- (goal (subgoal start)) =>
(modify ?G (subgoal finish))
)
;; Время завершения задачи - это время начала ее
;; выполнения плюс продолжительность . (defrule endpoint
(goal (subgoal finish))
(errand (name ?N) (latest ?L) (duration ?D))
?S <- (schedule (task ?N) (start
?!&:(<= ?T ?L)) (finish 0)) ... =>
(printout t crlf "Fixing end of" ?N t crlf)
;; "Определение завершения " ?N
(modify ?S (finish (+t ?T ?D)))
;; Новая цель - вывести отчет о плане.
(defrule unfinish
?G <- (goal (subgoal finish)) =>
(modify ?G (subgoal report))
)
;; Вывести задачи в хронологическом порядке.
(defrule scheduled
(declare (salience 10)) (goal (subgoal report))
?S <- (schedule (task ?N) (start ?T1) (finish ?T2S"0)
( status 0 ) ) . '(not (schedule (start ?T
3&:(<= ?T3 ?T1)) (status 0)))
)
=>
(printout t crlf ?N " from " ?T1 " till " ?T2t crlf)
;; ?N " от " ?T1 " до " ?T2
(modify ?S (status 1))
)
;; Для некоторых задач в расписании может не найтись
;; места.
(defrule unscheduled
(goal (subgoal report))
?S <- (schedule (task ?N) (finish 0) (status 0))
(printout t crlf ?N " not scheduled. " t crlf)
;; ?N " не включена в расписание. "
(modify ?S (status 1)) )
Эта программа успешно справляется с составлением расписания мероприятий, перечисленных после оператора deffact.В упр. 4 в конце главы будет показано, что существуют наборы мероприятий, с которыми программа не может справиться, хотя составить расписание для них с учетом оговоренных ограничений можно.
Итоги анализсистем решения проблем конструирования
Мы показали, что в ряде случаев методы решения проблем конструирования можно существенно упростить, используя специфические знания из предметной области. Например, система разработки компоновок вычислительных комплексов R1 организована таким образом, что она всегда располагает информацией, необходимой для выбора следующего шага, и не нуждается в механизме пересмотра принятых решений. В результате система не нуждается в дополнительных ресурсах для хранения предыстории принятых решений и взаимных связей между этими решениями.
Но в большинстве случаев не удается организовать такой однозначный выбор порядка выполнения проектирования, причиной чему является либо отсутствие достаточных знаний о данной предметной области, либо существование множества близких к оптимальному решений. Неполнота имеющихся знаний означает, что экспертная система должна следовать стратегии наименьшего принуждения и обладать способностью формировать предложения по наилучшему развитию текущего частичного варианта проекта. Поскольку такое предложение не всегда может быть правильным, программа должна иметь возможность обнаружить нарушение имеющихся ограничений в текущем незавершенном варианте проекта и либо вернуться и попробовать другой вариант продолжения, либо предложить способ устранения обнаруженного несоответствия. При реализации такой стратегии важную роль играет механизм записи и сохранения ранее принятых решений и отношений между ними. Мы еще вернемся к таким механизмам в главе 19.
Если задачи конструирования в определенной области могут иметь несколько вариантов решения, самая простая стратегия для экспертной системы — выбрать первое подходящее, ограничиваясь проверкой только жестких ограничений. Перебор нескольких вариантов и их последующее сравнение требует слишком больших вычислительных затрат. Это связано, в первую очередь, с тем, что проблемы конструирования или выбора компоновки многокомпонентной системы определены на довольно большом, а иногда и на бесконечно большом пространстве поиска вариантов, и этим они разительно отличаются от проблем классификации, рассмотренных в главах 11 и 12.
Совершенно очевидно, что размер пространства решений влияет на проблемы конструирования значительно сильнее, чем на проблемы классификации. Даже если обратиться к простейшим игровым задачам, вроде задачи о ферзях, которая рассматривалась в одном из упражнений главы 1, то и на их примере нетрудно убедиться, что метод, который позволит решить задачу о четырех или восьми ферзях, нельзя применить, когда речь пойдет о сотне или тысяче ферзей. Проблемы классификации относятся к числу тех, с которыми следует поступать по принципу "разделяй и властвуй", особенно если пространство категорий может быть организовано иерархически.
К слову сказать, существует множество реальных задач, типа планирования поведения роботов или составления расписания мероприятий, которые включают комбинаторику, не позволяющую использовать принцип "разделяй и властвуй". Частично это объясняется отсутствием подходящей метрики, которая позволила бы оценить, насколько близко конкретный фрагмент решения подходит к общему решению задачи. План можно оценить только целиком; нельзя сказать, насколько он будет хорош по характеристикам его отдельных этапов. Подход, основанный на "библиотеке заготовок" (он использовался в системе ONCOCIN; см. главу 10), также не годится для решения большинства проблем конструирования.
Методы, основанные на знаниях, являются реальной альтернативой алгоритмическому подходу в тех случаях, когда имеется достаточный объем знаний в конкретной предметной области, которые позволяют реализовать стратегию предложения и пересмотра или предложения и исправления. Но для реализации таких методов требуется довольно специфический механизм управления и обратного прослеживания решений, принимаемых программой. Мы еще вернемся к этой теме в последующих главах.
В главе 18 будет рассмотрена система, предназначенная для идентификации трехмерных структур протеинов в растворах. Комбинаторика, связанная с просмотром всех возможных вариантов компоновки молекул, совершенно очевидно не позволяет использовать исчерпывающий поиск или обратное прослеживание на сколько-нибудь значительную глубину.Поэтому программа организована таким образом, что в ней имеется несколько баз знаний, поддерживающих разные эвристики управления поиском в пространстве решений. Такая архитектура, получившая, название системы с доской объявлений (blackboard system), обеспечивает мощный механизм реализации таких стратегий, как последовательное уточнение частичных решений и восстановление после принятия неудачных решений.
В главе 19 мы рассмотрим системы обработки правдоподобия (truth maintenance) — усовершенствованный механизм фиксации решений, который существенно облегчает выполнение обратного прослеживания. В тех случаях, когда обратного прослеживания избежать невозможно, желательно, по крайней мере, быстро определить, в какую именно точку вычислений нужно вернуться, а не отменять по очереди все предыдущие операции, анализируя каждый раз последствия такой отмены.
Извлечение, представление и применение знаний о проектировании
15.3. Извлечение, представление и применение знаний о проектировании
В этой главе мы рассмотрим экспертную систему проектирования лифтовых систем VT [Marcus et al., 1988] и использованную в процессе ее разработки систему автоматизированного приобретения знаний SALT [Marcus et al, 1988]. В первом разделе основное внимание будет уделено самой программе VT, а в следующем будет описана методика приобретения знаний о проектировании, использованная в системе SALT.
Приобретение знаний с помощью системы SALT
Система автоматизированного приобретения знаний SALT разрабатывалась с ориентацией на использование в тех экспертных системах, в которых доминирующей при решении проблем является стратегия предложение и пересмотр. Это предположение было положено в основу организации процесса приобретения знаний. Один из используемых методов состоит в том, .что выявляются знания, позволяющие наполнить содержанием определенные роли в выбранной стратегии решения проблемы. При таком подходе решающее значение для успешной реализации задач системы имеет правильный выбор ролей и отношений между ними.
Полагается, что знания о предметной области должны распределяться между тремя ролями. Они перечислены ниже, причем в скобках приведено наименование каждой роли, присвоенное ей в документации системы SALT.
(1) Знания, которые касаются развития текущей промежуточной стадии проекта (PROPOSE-A-DESIGN-EXTENTION).
(2) Знания, относящиеся к определению ограничений, накладываемых на текущую промежуточную стадию проекта (IDENTIFY-A-CONSTRAINT).
(3) Знания, касающиеся устранения обнаруженных нарушений ограничений (PROPOSE-A-FIX).
Система SALT автоматически организует извлечение знаний каждой из указанных категорий в процессе интерактивного сеанса опроса эксперта, а затем преобразует полученные сведения в порождающие правила и формирует базу знаний о предметной области. После этого созданная база знаний объединяется с интерпретатором оболочки экспертной системы (см. главу 10). Система SALT сохраняет первичные сведения, полученные от эксперта, в декларативной форме и таким образом при необходимости позволяет их скорректировать и обновить ранее созданную базу знаний.
В качестве промежуточной формы представления знаний в SALT используется сеть зависимостей. Каждый узел этой сети представляет наименование какого-либо контрольного параметра (например, TYPE-OF-LOADING), параметра, характеризующего конструкцию (например, PLATFORM-WIDTH), или ограничения (например, MAXIMUM-MACHINE-GROOVE-PRESSURE).
Justification: CENTER-OPENING DOOR LOOK BEST WHEN
CENTERED ON THE PLATFORM
1.Имя: CAR-JAMB-RETURN
2. Предусловия: DOOR-OPENING=CENTER
3. Процедура: Вычисление
4. Формула: (PLATFORM-WIDTH - OPENING-WIDTH)/2
5. Уточнение: Двери, открывающиеся от середины, выглядят лучше,
если на платформе их разместить по центру
В правилах типа CONSTRAINT собирается информация о взаимных связях между значениями параметров, которая не вошла в правила типа PROCEDURE, но необходима для проверки качества созданного проекта. Правила типа FIX предлагают варианты корректирующих действий, которые можно предпринять при нарушении заданных ограничений. Ниже приведен заполненный формуляр для правила этого типа, которое относится к ликвидации нарушения ограничения MAXIMUM-MACHINE-GROOVE-PRESSURE.
Constraint name: MAXIMUM-MACHINE-GROOVE-PRESSURE
Value to Change HOIST_CABLE-QUANTITY
Change Type: INCREASE
Step Type: BY-STEP
Step Size: 1
Preference Rating: 4
Preference Reason: CHANGES MINOR EQUIPMENT SIZING
Имя ограничения: MAXIMUM-MACHINE-GROOVE-PRESSURE Изменить: HOIST_CABLE-QUANTITY
Тип изменения: INCREASE
Режим изменения: BY-STEP
Величина шага: 1
Приоритет: 4
Критерий выбора: Минимальные изменения размеров другого оборудования
Информация из таких стилизованных формуляров довольно просто преобразуется в порождающие правила. Но система SALT не только переводит полученную информацию в формат правил, но и анализирует соответствие между новым правилом и ранее введенными. Поэтому желательно сначала ввести информацию для всех правил типов PROCEDURE и CONSTRAINT, а уже затем вводить информацию для правил типа FIX. В этом случае правила последнего типа будут анализироваться с учетом всех знаний, касающихся проектирования и ограничений.
Информацию о связях в сети зависимостей программа SALT извлекает из тех элементов знаний, которые вводятся пользователем. Так, после ввода приведенного выше правила типа PROCEDURE программа сформирует содействующую связь между узлом, ассоциированным с параметром PLATFORM-WIDTH, и узлом, ассоциированным с параметром CAR-JAMB-RETURN.Точно так же после ввода правил типов CONSTRAINT и FIX будут сформированы ограничивающие и корректирующие связи.
Формируемая экспертная система должна присвоить значения каждому узлу сети и найти на графе сети такой путь, который обеспечивал бы проверку и удовлетворял всем заданным ограничениям. На компилятор возлагается задача сформировать процедуры в соответствии с найденным путем на графе и проверить, является ли он единственным и полным для набора входных данных.
Реализация обратного прослеживания в системе VT
Программа VT (название программы — аббревиатура от Vertical Transportation, транспортировка по вертикали) была использована фирмой Westinghouse Elevator для разработки лифтовых систем индивидуального исполнения. Исходные данные для программы VT представляют собой набор основных параметров проектируемой системы — скорость, грузоподъемность, размеры лифтовых шахт. На основе этих данных программа формирует список подходящего оборудования и компоновку всех шахт с учетом требований безопасности и производительности системы.
В процессе проектирования программа сначала формирует примерную компоновку, а затем уточняет ее на основе анализа оговоренных ограничений. На первом этапе используется прямая цепочка правил логического вывода. Программа выбирает в качестве исходных данных либо введенные параметры, либо значения, вычисленные другими процедурами. Типичное правило (в системе VT они почему-то названы PROCEDURE — процедура) представлено ниже.
ЕСЛИ: доступны значения параметров
DOOR-OPENING, PLATFORM-WIDTH и OPENING-WIDTH
и DOOR-OPENING=CENTER,
ТО: CAR-JAMBETURN=(PLATFORM-WIDTH - OPENING-WIDTH)/2.
На этом этапе весь процесс направляется данными. Допустима любая операция проектирования, если только для этого имеется достаточно исходной информации. Но поскольку на этом этапе некоторые из задач оказываются недоопределенными, то вполне возможна и такая ситуация, когда при отсутствии полностью определенных задач в списке актуальных очередное предложение будет сформировано такой недоопределенной задачей. В результате в дальнейшем будет развиваться частичная конфигурация проекта, созданная на базе неполной информации. Иными словами, в системе VT не всегда соблюдаются условия соответствия, сформулированные в предыдущей главе, но, тем не менее, процесс проектирования продолжается, поскольку предполагается, что в дальнейшем удастся скорректировать возможное нарушение ограничений.
По мере развития проекта система VT отслеживает на каждом шаге, от каких исходных или промежуточных данных зависят сформированные на этом шаге данные.
В процессе отслеживания формируется сеть зависимостей (dependency network). Структура сети зависимостей будет детально рассмотрена в главе 19, а пока считайте, что такая сеть представляет собой один из видов ориентированного графа без петель. Узлы графа представляют вычисленные значения важных параметров проектируемой системы, например CAR_JUMB_RETURN (пространство для маневрирования автомобилей при загрузке в лифт), а ребра — применяемые для их определения правила. Узлы и ребра графа формируются по мере активизации тех или иных правил в процессе развития проекта. В результате программа после завершения проектирования получит возможность выяснить, каким образом в процессе рассуждений было определено значение того или иного параметра, и найти, какое из принятых в процессе проектирования решений привело к нарушению ограничений. Найденное решение и послужит отправной точкой для пересмотра проекта.
Нарушение ограничений выявляется с помощью демонов (см. главу 6). Если имеется достаточно информации для того, чтобы определить, как связано значение некоторой величины со значениями ограничений, выполняется сравнение. Возможные способы устранения несоответствия ранжированы и активизируются в заданном порядке. Пример правила устранения несоответствия приведен ниже.
ЕСЛИ: нарушено ограничение MAXIMUM-MACHINE-GROOVE-PRESSURE,
ТО: попробовать понизить значение MACHINE-GROOVE-MODEL (1),
увеличить значение HOST-CABLE_QUANTITY (4).
После применения правила устранения несоответствия программа, пользуясь сформированной ранее сетью зависимостей, корректирует и остальные параметры проекта, зависящие от тех, которые были изменены в результате применения правила.
Приведенное выше правило устранения предлагает два варианта, причем указанный в скобках уровень приоритета означает, что предпочтение следует отдать первому варианту. Если же его реализовать по каким-либо причинам не удастся, следует попробовать второй вариант.
Говорят, что два ограничения являются антагонистическими, если удовлетворение одного из них приводит к нарушению другого.
Если вернуться к рассмотренному выше примеру с посещением кинотеатра, то можно интерпретировать антагонистические ограничения следующим образом. Два человека хотят вместе пойти в кино, но один не желает видеть ничего, кроме фильмов ужасов, а другой не выносит вида крови. Если удовлетворить вкусы одного, то желание другого будет проигнорировано.
Проблема пересмотра ранее принятых решений усложняется тем фактом, что коррекция параметров, необходимая для устранения одних ограничений, влияет на другие параметры, которые, в свою очередь, связаны с другими ограничениями. В правиле, приведенном выше, одна из рекомендаций предполагает изменение количества тросов подъемника, что приведет к изменению множества других параметров всей конструкции. Вполне возможно, что после этого придется заменить и модель лифта. База знаний программы VT включает 37 цепочек устранения несоответствия ограничениям, причем три из них имеют дело с антагонистическими ограничениями. Антагонистическими, например, являются ограничения MAXIMUM-MACHINE-GROOVE-PRESSURE (максимальная нагрузка на трос подъемника) и MAXIMUM-TRACTION_RATIO (максимальное отношение сцепления). Понижение нагрузки приведет к увеличению отношения сцепления и наоборот.
Если одновременно нарушаются оба антагонистических ограничения, то складывается ситуация, когда, скорректировав параметры, необходимые для устранения одного несоответствия, мы еще более усугубим другое. В системе VT проблема устранения антагонистических ограничений выделена в отдельный случай и решается следующим образом. Когда демон фрейма обнаруживает такую ситуацию, каждому параметру, имеющему отношение к выявленному нарушению ограничений, присваивается то значение, которое он имел до нарушения любого ограничения. Таким образом отменяются все предпринятые ранее меры по ликвидации нарушения всех ограничений. После этого программа предпринимает попытку выполнить какую-либо из корректирующих операций, весь набор которых разделен на три группы очередности:
(1) операции, которые помогают устранить нарушение обоих антагонистических ограничений;
(2) операции, которые помогают устранить нарушение одного из антагонистических ограничений и не усугубляют нарушение другого;
(3) операции, которые помогают устранить нарушение одного из антагонистических ограничений, но усугубляют нарушение другого.
Если дело доходит до выполнения операций третьей группы, то сначала программа пытается устранить нарушение наиболее существенного ограничения. Таким образом, одно из важнейших отличий программы VT от MOLGEN состоит в том, что хотя в обеих системах используется стратегия предложение и пересмотр, в программе VT гораздо большее внимание уделено фазе пересмотра ранее принятых решений, а программа MOLGEN концентрируется на реализации принципа наименьшего принуждения.
Программа VT реализована с помощью языка OPS5. База знаний этой программы насчитывает около 3000 правил. В литературе приводятся сведения о производительности системы. Для выполнения задания средней сложности программа активизирует от 2 500 до 11 500 правил, на что затрачивается от 7 до 20 минут машинного времени компьютера VAX 11/780, оснащенного оперативной памятью объемом 20 Мбайт. Интересно отметить, что около 2000 правил системы VT сформировано с помощью системы автоматизированного приобретения знаний SALT, а другие (их около 1000) отвечают за организацию ввода/вывода, управление порядком применения правил и формирование объяснений, помогающих пользователю уяснить, почему программа в процессе проектирования приняла определенные решения.
Рекомендуемая литература
Применение экспертных систем для выполнения планирования рассматривается во множестве статей, включенных в популярные сборники, среди которых рекомендуем обратить внимание на следующие: [Nilsson, 1980], [Genesereth and Nilsson, 1987] и [Charniak and McDermott, 1985]. Читателей, интересующихся ранними исследованиями в области использования стратегии наименьшего принуждения для планирования, мы отсылаем к работе [Sacerdoti, 1974], Описание других исследований, касающихся решения проблем конструирования, можно найти в работах [Brown and Chandrasekaran, 1989] и [Coyne, 1988].
Результаты более поздних исследований представлены в книге [Dean and Wellman, 1991] и публикуемых IEEE трудах ежегодных конференций AI Simulation and Planning in High Autonomy Systems (выпуски за 1991 и 1992 гг.).
С системой EXPECT, которая является одной из автоматизированных систем приобретения знаний, аналогичной по возможностям рассмотренной _в этой главе системе VT, можно ознакомиться в работе [Gil and Paris, 1984].
Решение проблем конструирования (II)
15.1. Стратегии конструирования
15.2. Архитектура систем планирования и метапланирования
15.3. Извлечение, представление и применение знаний о проектировании
15.4. Итоги анализа систем решения проблем конструирования Рекомендуемая литература
Упражнения
В предыдущей главе мы рассматривали экспертные системы для решения проблем конструирования, в которых по ходу процесса никогда не возникала необходимость отмены уже принятых решений. Однако такая стратегия подходит далеко не для всех задач конструирования, поскольку мы не всегда располагаем всеми необходимыми для этого знаниями о предметной области. В этой главе мы проанализируем применение двух стратегий — наименьшего принуждения (least commitment) и предложение и пересмотр (propose and revise). Завершит главу обзор некоторых инструментальных средств приобретения знаний, которые используются в системах решения проблем конструирования.
Стратегии конструирования
Предположим, у вас возникла необходимость расставить мебель в комнате. Цель решения этой задачи можно сформулировать следующим образом: найти такой вариант расстановки, который, во-первых, удовлетворял бы заданным геометрическим ограничениям (комната имеет конечные размеры, в ней, возможно, имеются какие-то специфические особенности, например альков, предметы обстановки также имеют свои размеры и т.п.), а во-вторых, учитывал бы определенные предпочтения, касающиеся взаимного расположения предметов обстановки (рабочий стол возле окна, диван против телевизора и т.д.). Скорее всего вы начнете с того, что выберете место для одного-двух главных предметов, которые зададут "точки привязки" для остальных. Далее выполняется расстановка остальных предметов и проверяется, насколько полученный вариант удовлетворяет сформулированным требованиям.
Если вам очень повезет, то первый же вариант может оказаться удачным, но рассчитывать на это вряд ли стоит. Скорее всего окажется, что на каком-то этапе расстановки нарушаются сформулированные ограничения. Когда такое случится, совсем не обязательно отменять все ранее сделанное и возвращаться в самое начало процесса. Как правило, вы найдете способ, как, сдвинув пару-другую предметов, "втиснуться" в ограничения. Лучшим из способов такой "подстройки" является тот, который сохранит самую большую часть ранее проделанной работы.
Как уже не раз подчеркивалось, основная сложность решения задач конструирования состоит именно в том, что чаще всего нельзя заранее сказать, подойдет ли данная частично выполненная конструкция для окончательного варианта, т.е. можно ли будет, развивая дальше это частичное решение, получить окончательный вариант, удовлетворяющий всем ограничениям. В применении к задачам конструирования восходящая стратегия (стратегия снизу вверх), которую мы использовали для решения задач малой размерности, выглядит примерно так.
(1) Если это возможно, начать с частичного варианта расстановки, который удовлетворяет заданным ограничениям.
В противном случае начать с размещения первого компонента.
(2) Если расставлены все компоненты, прекратить процесс. В противном случае выполнить "наиболее многообещающее" расширение текущего варианта — поместить в планировку новый компонент.
(3) Если новый вариант размещения "не вписывается" в ограничения, предложить такой способ корректировки этого варианта, который требует как можно меньших переделок выполненных этапов.
(4) Перейти на шаг 2.
Конечно, эта стратегия выглядит слишком уж обобщенной, но даже на этом уровне в ней можно отметить несколько интересных моментов. Во-первых, она рекомендует при малейшей на то возможности начинать с какого-нибудь удовлетворительного варианта, а не с чистого листа. Так, если речь идет о планировании операций, начинайте с какого-нибудь частичного варианта, развитие которого в предыдущих аналогичных задачах привело к успеху. Не так уж фантастично выглядит идея, что в голове у человека-проектировщика имеется что-то вроде библиотеки заготовок для тех классов задач, с которыми ему приходилось иметь дело. Во-вторых, "наиболее многообещающее" расширение текущего варианта— это то, которое оставляет вам как можно большую свободу действий в будущем. Например, при выполнении планирования очередное действие должно по возможности сохранять временной зазор для последующих этапов, еще не включенных в план. Такую стратегию принято называть стратегией наименьшего принуждения (least commitment). В-третьих, корректировка текущего варианта совсем не обязательно должна сводиться к отмене последней по времени операции. Например, установка рабочего стола может привести к тому, что он "закроет" телевизор. Но совсем не обязательно отменять последнее действие и удалять с плана стол, может быть, целесообразнее сдвинуть телевизор или диван.
При решении задачи расстановки множества предметов может оказаться, что пространство поиска будет очень большим и таким образом проблема может перейти в разряд нерешаемых.
Но, как правило, такие задачи можно упростить, рассматривая их на разном уровне представления деталей. Рассмотрим, например, задачу планировки дома на заданном участке земли. Пусть сейчас нас интересует компоновка помещений. Эту задачу можно сформулировать на разных уровнях абстракции (см. [Rosenman et al, 1987]):
в терминах взаимного положения, например "комната А рядом с комнатой Б";
в терминах ориентации, например "комната А на север от комнаты Б";
в терминах координат, которые точно указывают положение комнаты А по отношению к комнате Б.
На самом верхнем уровне абстракции принимается решение, какое помещение с каким должны соседствовать (например, кухня и столовая, ванная и спальня). Это решение уже сокращает возможность экспоненциального расширения пространства поиска. На следующем уровне принимается решение, например, что жилая комната должна выходить на юг, а кухня — на север, чтобы в ней было прохладнее. Это решение накладывает одновременно ограничения и на расположение столовой. После того как будет покончено с взаимным положением помещений и их ориентацией, нам потребуются какие-то эвристики, помогающие выделить место на планировке для всех помещений и разрешать возникающие при этом конфликты. Например, одна из эвристик предлагает сначала выбрать место для самых главных помещений, а оставшееся распределить между подсобными.
Такой иерархический подход хорошо знаком тем, кто часто имеет дело с проектированием планировок. Что касается экспертных систем, предназначенных для такого рода задач, то в таких системах, как NOAH [Sacerdoti, 1974] и NONLIN [Tate, 1977], которые явились развитием программы STRIPS, упрощение пространства поиска было достигнуто за счет следующего:
действия на более высоких уровнях абстракции рассматриваются как группы, объединяющие целую последовательность действий более низких уровней;
проблема планирования решается в терминах частичного упорядочения таких групп;
уточнение деталей выполняется на все более низких уровнях абстракции до тех пор, пока план не будет полностью завершен.
Описанный подход к решению проблемы можно отнести к типу нисходящих. В чем-то он напоминает организацию задача-подзадача, принятую в системе R1. Но существенное отличие от системы R1 состоит в том, что в данном случае иногда приходится пересматривать уже принятые решения в пределах одного и того же уровня абстракции, чего в программе R1 никогда не делается. Это и есть реализация той части стратегии, которая обозначена словом пересмотр в общем названии предложение и пересмотр (propose and revise). При решении очень сложных задач планирования иногда приходится выполнять пересмотр решений, принятых и на более верхних уровнях абстракции, а затем возвращаться на текущий уровень. Конечно, желательно по возможности избегать такого переноса, а потому серьезное внимание должно быть уделено выработке наиболее перспективных предложений и реализации стратегии наименьшего принуждения.
В следующем разделе мы рассмотрим систему MOLGEN [Stefik, 1981, a], [Stefik, 1981, b], которая предназначена для планирования экспериментов в исследованиях по молекулярной генетике. По ходу описания системы мы еще раз обратим ваше внимание на те моменты, о которых шла речь в этом разделе. Эта система является хорошим примером применения многоуровневого подхода на основе стратегии наименьшего принуждения для решения проблем конструирования. В разделе 15.3 будет рассмотрен метод восходящего решения проблем в системе VT [Marcus et al, 1988]. Эта система предказначена для проектирования лифтовых систем и использует стратегию предложение и пересмотр. В этом же разделе вы познакомитесь с методикой приобретения знаний, основанной на использовании инструментальной системы SALT [Marcus, 1988, b].
Поясните смысл стратегии наименьшего принуждения.
1. Поясните смысл стратегии наименьшего принуждения. В чем отличие этой стратегии и стратегии предложение и пересмотр!
2. Постарайтесь перечислить как можно больше задач, к которым, по вашему мнению, можно применить стратегию наименьшего принуждения; нельзя применить стратегию наименьшего принуждения, не подкрепив ее какой-нибудь другой.
Подумайте о тех задачах, с которыми вы достаточно часто сталкиваетесь в повседневной жизни, например планирование похода по магазинам. Чем отличаются эти два класса задач?
3. Объясните смысл терминов метауровневая архитектура и метапланирование.
4. Проанализируйте программу, представленную во врезке 15.1. Подумайте над тем, каким образом нужно модифицировать данные, приведенные в операторе deffacts, -чтобы программа прервала работу, поскольку не смогла сформировать расписание, хотя, в принципе, его можно составить. (Указание: попробуйте манипулировать только приоритетами задач.)
5. Программа планирования мероприятий, представленная во врезке 15,1, не сможет составить расписание для следующего набора исходных данных, несмотря на то, что такое расписание существует.
(deffacts the-facts
(goal (subgoal start))
(errand (name hospital)
(earliest 1030)
(latest 1030) (duration 200) (priority 1))
(errand (name doctor)
(earliest 1430) (latest 1530)
(duration 200) (priority 1))
(errand (name lunch)
(earliest 1130) (latest 1430)
(duration 100) (priority 2))
(errand (name guitar-shop)
(earliest 1000) (latest 1700)
(duration 100) (priority 2))
(errand (name haircut)
(earliest 900) (latest 1700)
(duration 30) (priority 2))
(errand (name groceries)
(earliest 900) (latest 1800)
(duration 130) (priority 2))
(errand (name bank)
(earliest 930) (latest 1530)
(duration 30) (priority 2))
(errand (name dentist)
(earliest 900) (latest 1600)
(duration 100) (priority 1)) )
Почему?
6. Ниже представлено дополнительное правило для программы составления расписания, которое позволит разрешить проблему, на которой программа споткнулась в предыдущем упражнении.
Инструментальные среды AGE и ОРМ
18.2.4. Инструментальные среды AGE и ОРМ
Инструментальная среда AGE представляет собой набор заранее сформированных модулей — компонентов, из которых пользователь может создавать прикладную экспертную систему [Nii and Aiello, 1979]. Компонент— это набор переменных и функций на языке LISP, которые описывают как реальные, так и концептуальные объекты. Из компонентов можно "собирать" и продукционную экспертную систему, использующую стратегию обратной цепочки логического вывода, как в MYC1N, и систему на основе доски объявлений. Источник знаний в структуре с доской объявлений представляет собой помеченный набор порождающих правил, с которым связаны предусловия для его активизации. Эти предусловия специфицируют ситуации, в которых применимы правила из данного источника. По отношению к каждому источнику может быть использована как стратегия активизации единственного правила, так и стратегия параллельной активизации нескольких правил.
Описания концептуальных и реальных объектов, а также связей между ними могут иметь объектно-ориентированное представление, как это сделано в пакете UNITS, созданном в среде AGE [Stefik, 1979]. (Пакет UNITS является прототипом системы КЕЕ, о которой упоминалось в главе 17.) Правила в источниках знаний имеют доступ к управляющей информации на доске объявлений. В результате одни источники знаний могут манипулировать другими и всю конструкцию можно считать частью управляющей структуры.
Правила в источниках знаний могут быть активизированы в разных режимах применимости — когда выполняются все условия, специфицированные в левой части правила или когда выполняется только часть этих условий. Среда предоставляет пользователю (разработчику экспертной системы) определить, какой именно режим применимости следует использовать в отношении того или иного правила. В состав среды входит набор простых функций оценки (например, функция "все-условия-должны-быть-истинными"), которые пользователь может встраивать в проектируемую систему.
В правой части правил специфицируются изменения, которые нужно внести в структуру гипотезы или в базу знаний. Возможные изменения разбиты на три группы (типа):
события— реальные изменения элементов гипотезы, связей или базы знаний; информация о таких изменениях немедленно помещается в список событий на доске объявлений и становится доступной другим источникам знаний;
предполагаемые изменения структуры гипотезы или базы знаний помещаются в список ожидаемых на доске объявлений; этот список также доступен другим источникам знаний как часть управляющей информации;
желательные изменения структуры гипотезы или базы знаний — цели; эти изменения помещаются в список целей.
Те изменения, которые вносятся правилами, можно связать с параметром, отражающим степень уверенности в импликации, которую необходимо вывести при условиях, указанных в левой части правила. Этот параметр конструктор экспертной системы должен выразить в тройках "атрибут-значение-вес" элемента гипотезы, задействованного при выполнении правила. Веса в правилах и значения параметров, присвоенные атрибуту гипотезы, должны быть каким-то образом объединены. В целях достижения максимальной гибкости среда AGE предлагает пользователю задать предпочтительный метод вычисления такой комбинированной оценки в виде функции, которая служит для корректировки весов. Пользователь может выбрать либо одну из встроенных в среду функций, либо разработать ее самостоятельно.
В работе [Aiello, 1983] описаны три варианта реализации экспертной системы PUFF с помощью среды AGE, в которых использованы разные модели структуры.
Экспертная система ОРМ [Hayes-Roth, 1985], предназначенная для планирования выполнения множества задач, представляет собой систему управления доской объявлений. В ней решение проблем из предметной области и управления объединены в едином цикле управления, причем не предусматривается использование какой-либо заранее запрограммированной стратегии управления. Выбор очередной операции выполняется на основании независимых суждений о том, какие операции желательны в текущей ситуации и какие возможны, причем при принятии решения используется комбинация множества управляющих эвристик.
Основное назначение системы — планирование мероприятий. Программа использует четыре глобальных структуры данных.
(1) Доска объявлений, которая разбита на пять "панелей":
метапланирование (цели планирования);
абстракции планирования (решения о планировании);
база знаний;
план (выбранные действия);
исполнение (выбранные для выполнения записи активизации источников знаний).
(2) Список событий для хранения изменений, вносимых на доску объявлений.
(3) Карта соответствия, указывающая пункты проведения мероприятий.
(4) Список актуальных записей источников знаний.
Источники знаний содержат в своем составе и пусковые образцы, с помощью которых определяется соответствие источника знаний текущему узлу на доске объявлений, и программы проверки, с помощью которой выясняется, возможно ли применение определенной записи активизации в текущей ситуации. При планировании работы с источниками знаний предпочтение отдается тем записям активизации, которые влияют на текущий узел доски объявлений.
Хотя при разработке системы ОРМ предполагалось использовать ее как инструмент моделирования процесса принятия решений человеком, у нее есть несомненные достоинства и с точки зрения системной организации. Возможность интегрировать управляющие знания в однородную среду знаний открывает довольно интересные перспективы для реализации метауровневой архитектуры.
Интеграция стратегий логического вывода
Джонсон и Хейес-Рот обратили внимание на то, что рассуждения, ведомые целью, можно объединить и с иерархическим планированием, и с выбором подходящего контекста в PROTEAN [Johnson and Hayes-Roth, 1986]. Стратегию формирования суждений на основе заданной цели нужно использовать в тех случаях, когда перед выполнением желаемой операции нужно выполнить некоторые подготовительные процедуры. Например, в записях активизации источников знаний, представляющих желаемые операции, могут быть специфицированы определенные предварительные условия, и эти предусловия можно трактовать как подцели, достижение которых будет способствовать активизации указанных источников знаний.
Знания о целях можно дифференцировать, различая причины, побуждающие нас сформировать ту или иную цель. Причинами могут быть стремление
(1) выполнить определенную операцию (например, активизировать определенный источник знаний, представленный в записи активизации);
(2) установить определенное состояние, которое будет способствовать удовлетворению предусловий активизации;
(3) вызвать определенное событие, которое поставит в очередь запись активизации источника знаний с желаемой операцией.
Цели первого типа представляют операции, которые приводят к удовлетворению предусловий. Цели второго типа имеют отношение к ситуации, когда текущий контекст не позволяет запустить на выполнение выбранную запись. В этом случае можно воспользоваться родовым источником знаний, который в ВВ1 имеет наименование ЕпаЫе-Priority-Action. Этот источник и активизируется в тех случаях, когда не удовлетворяются предусловия в выбранной записи. Цели третьего типа имеют отношение к ситуации, когда в списке выбора отсутствуют записи, которые могут привести к выполнению желаемой операции. В этом случае потребуется вмешательство специального источника управляющих знаний, способного отыскать среди прочих источников знаний такой, который содержит в себе желаемую операцию. Создать условия для его активизации — это и есть цель третьего типа.
Указанные две стратегии могут работать совместно, устраняя препятствия для выполнения желаемых операций.
Использование источников знаний в HEARSAY-II
Для генерации, комбинирования и развития гипотез интерпретации в системе HEARSAY-II используется несколько источников знаний. Созданные гипотезы (интерпретации) разного уровня абстракции сохраняются на доске объявлений.
Каждый источник знаний можно считать в первом приближении набором пар "условие-действие", хотя они могут быть реализованы и в форме, отличной от порождающих правил (например, условия и действия могут быть в действительности произвольными процедурами). Поток управления в этой системе также отличается от потока управления в продукционных системах. Вместо того чтобы в каждом цикле интерпретатор анализировал выполнение условий, специфицированных в источниках знаний, источники знаний загодя объявляют об активизированных в них условиях, извещая, какой вид модификации данных будет влиять на выполнение этих условий. В результате система управляется прерываниями, а этот режим управления значительно эффективнее, чем режим циклического просмотра состояния, который является основным для продукционных экспертных систем. Такой режим напоминает использование демонов во фреймовых системах, где поток управления регулируется обновлением данных.
Источники знаний связываются с уровнями доски объявлений следующим образом. Условия, специфицированные в источнике знаний, будут удовлетворяться в результате обновления данных на определенном уровне доски объявлений. Источник знаний также может записывать данные в определенный уровень, причем не обязательно в тот же, который влияет на выполнение условий. Большинство источников знаний в системе HEARSAY-II организовано так, что они распознают данные на определенном уровне лингвистического анализа, а выполняемые ими операции относятся к следующему по порядку уровню. Например, некоторый источник активизируется данными на силлабическом уровне и формирует лексическую гипотезу на уровне слов.
В несколько упрощенном виде архитектура системы HEARSAY-II представлена на рис. 18.1. Стрелки, направленные от уровней доски объявлений к источникам знаний, указывают, данные какого уровня изменяют выполнение условий, специфицированных в источнике знаний.
Эффективность и гибкость модели с доской объявлений
Широкие функциональные возможности и универсальность архитектуры на основе доски объявлений приводят к увеличению объема вычислений, необходимых для ее реализации. Ниже мы рассмотрим проблемы, возникающие при построении прикладных экспертных систем с такого рода архитектурой.
Компоновкдоски объявлений в среде ERASMUS
Практически все компоненты системы с доской объявлений имеют ярко выраженную модульную структуру. Это в равной мере относится и к структурам данных самой доски объявлений, и к источникам знаний, и к средствам управления режимом работы системы. Например, существует множество способов представления элементов данных доски объявлений, в источниках знаний можно использовать множество разных форматов представления знаний (порождающие правила, программный код на языке LISP и т.п.), по-разному можно настраивать процесс активизации источников знаний, планирования выполнения заявок.
Вслед за средами разработки ВВ1 и GBB мы рассмотрим в этом разделе еще одну систему — ERASMUS, которая разработана в компании Boeing на основе опыта, полученного при работе с ранее созданной системой с доской объявлений ВВВ (Boeing Blackboard System). Система ВВВ разрабатывалась в среде ВВ1, а элементы данных в ней представляли собой объекты языка КЕЕ (см. об этом языке в главе 17). Система была задумана как инструментальная среда, предоставляющая в распоряжение разработчика множество самых различных средств, которые можно использовать в прикладной системе в разных сочетаниях. Фактически ERASMUS является развитием ВВВ, причем при модернизации преследовались следующие цели [Байт et al., 1989].
(1) Конфигурация системы должна настраиваться пользователем.
(2) Должна обеспечиваться максимально высокая производительность, возможная при заданной конфигурации.
(3) Система должна допускать наращивание.
(4) Система должна поддерживать множество схем представления объектов доски объявлений.
Специалисты фирмы Boeing пришли к выводу, что многие приложения, с которыми им приходится иметь дело, достаточно хорошо вписываются в подход, который был использован в среде ВВ1. По образу и подобию ВВ1 в фирме была разработана среда ВВВ, но после нескольких лет ее эксплуатации сложилось мнение, что использованная в ней схема представления и управления накладывает чрезмерные ограничения. Поэтому, например, при создании на основе ВВВ системы планирования производства Phred пришлось дополнительно разрабатывать механизм поддержки некоторых фаз решения проблем, подобный описанному в главе 13.
Оказалось также, что на некоторых фазах процесса можно организовать более эффективное планирование активизации источников знаний, допустив исполнение нескольких заявок. При работе с другой экспертной системой, Cockpit Information Manager, оказалось, что нужно повысить скорость поиска объектов на доске объявлений. Реализация элементов данных доски объявлений в виде объектов языка КЕЕ не позволяет получить максимальную производительность системы, хотя в системе GBB этого удалось достичь за счет использования изощренного метода индексации при извлечении объектов из доски объявлений.
Разработчики системы ERASMUS охарактеризовали ее как "генератор систем с доской объявлений", хотя больше ей подходит характеристика "система с конфигурируемой архитектурой" (configurable architecture). Возможность по-разному компоновать структуру системы, создаваемой в этой среде, позволяет оптимально настроить ее архитектуру в соответствии с характеристиками конкретного приложения.
Среда ERASMUS поддерживает четыре опции конфигурации.
(1) Blackboard (доска объявлений). Пользователь может выбрать одну из четырех структур данных для доски объявлений в создаваемой системе, в том числе и формат, подобный GBB, или на основе объектов языка КЕЕ.
(2) KS structure (структура источника знаний). Источники знаний могут быть реализованы в формате языка FLAVOR (см. об этом языке в главе 7), а записи активизации источников знаний представляют собой экземпляры объектов этого языка. Пользователь может специфицировать предусловия активизации источников знаний, условия устранения, при выполнении которых запись активизации источника знаний удаляется из списка выбора, фазы процесса решения проблемы и т.п.
(3) Control (режим управления). Пользователь может выбрать режим управления, аналогичный используемому в системе ВВ1, либо режим, ведомый эвристиками, назначающими веса записям активизации источников знаний.
(4) Runtime (опции времени выполнения). Эти опции позволяют пользователю выбрать механизм формирования пояснений, трассировки и различные средства отладки, которые должны быть включены в состав компонуемой прикладной экспертной системы.
Таким образом, модульная организация систем с доской объявлений позволяет разработчикам гибко варьировать структуру конкретной системы с такой архитектурой, добиваясь оптимального соответствия между функциональными возможностями и производительностью системы.
Общая характеристикВВ
Архитектура ВВ, конечно, довольно сложная, но эта сложность оправдывается следующими ее преимуществами по сравнению с более простыми системами.
В этой архитектуре решена задача разделения управляющих знаний и знаний, специфичных для предметной области. Источники родовых управляющих знаний могут без всякой модификации использоваться в экспертных системах самого разнообразного назначения, хотя источники знаний о предметной области при этом будут совершенно различными.
Эта архитектура предполагает дифференциацию источников знаний каждого из указанных типов. Знания о предметной области в системе ACCORD разделены на знания о действиях, событиях, состояниях, объектах, их компоновках и роли объектов в компоновках. Управляющие знания также разделены на знания о стратегии, предусловиях, эвристиках и т.д.
Эта архитектура позволяет формировать пояснения поведения системы в терминах выполняемого плана.
Архитектура предполагает широкое использование языков высокого уровня, подобных ACCORD.
Модули, которые входят в состав среды, могут быть использованы повторно в множестве создаваемых на ее основе прикладных экспертных систем.
Как это случалось и с прежними разработками, выполненными в стенах Станфордского университета, предлагаемый подход интересен не только с точки зрения теории построения систем искусственного интеллекта, но имеет и большую практическую ценность.
Организация доски объявлений в системе GBB
В реальной экспертной системе доска объявлений представляет собой ассоциативную память для источников знаний. Вычислительные операции, связанные с манипуляцией данными в этой памяти, отнимают львиную долю ресурсов всей системы. Поэтому понятно, насколько важно использовать для работы с доской объявлений эффективные алгоритмы доступа к данным и добавления новых данных. Хотя мы и не располагаем конкретными данными об эффективности выполнения вычислений в современных системах с такой архитектурой, но в разработанной в 70-х годах системе HEARSAY-II до половины машинного времени уходило на организацию работы с доской объявлений, а уже оставшееся время тратилось на собственно обработку информации от источников знаний.
В ранних системах для повышения производительности операций с доской объявлений использовалось разбиение ее на уровни или "панели", что позволяло сократить пространство поиска, поскольку определенный источник знаний требовал просмотра только части всей структуры данных.
Ниже мы несколько подробнее рассмотрим современную систему, названную создателями GBB (Generic Blackboard Builder). Ее можно рассматривать как типичного представителя нового поколения систем с такой архитектурой.
Разделы доски объявлений в GBB называются пространствами (spaces), причем они, в свою очередь, разделены на размерности (dimensions), для доступа к которым используется специальный атрибут индексации. Элементы структуры данных доски объявлений "живут" в этих пространствах, причем оснащены собственными атрибутами индексации, позволяющими реализовать множество различных методов быстрого обращения к ним. Если пользоваться терминологией баз данных, то эти индексы являются, по существу, ключами, хотя и довольно сложными.
Размерности, используемые для дальнейшей структуризации пространств, могут быть упорядоченными (ordered) или перечислимыми (enumerated). Индексы могут быть скалярными, т.е. состоять из единственного элемента данных, или составными, состоящими из множества компонентов.
(4) Постфильтрация. К каждому отобранному элементу доски объявлений применяются дополнительные процедуры проверки. Этот этап необязателен, как, впрочем, и этап предварительной фильтрации. В результате множество элементов-претендентов еще более сужается.
Та схема обработки, которую мы здесь представили, отображает процесс только в самых общих чертах. В действительности все происходит значительно сложнее, но в этой книге мы не будем останавливаться на всех деталях его реализации. Но уже и из этого описания ясно, что уровень сложности обработки в системах с доской объявлений на порядок выше, чем в системах с другой архитектурой, использующих в чистом виде представление знаний в виде правил или объектов. Для того чтобы помочь пользователю справиться с возросшей сложностью системы, в состав оболочки включено множество заготовок типовых модулей, из которых пользователь может достаточно просто скомпоновать прикладную экспертную систему.
Организация параллельных вычислений в системах CAGE и POLIGON
При анализе работы систем с доской объявлений сам собой напрашивается вопрос, а нельзя ли, учитывая наличие нескольких независимых источников знаний, общающихся друг с другом через глобальную структуру данных, организовать их параллельную работу. Очевидно, что параллелизм можно внедрить на разных уровнях систем с такой архитектурой:
на уровне активизации источников знаний;
на уровне обработки пускового образца и предусловий в процессе работы с отдельным источником знаний;
на уровне выполнения действий, предусмотренных записью активизации источника знаний.
Хотя процессам первой группы параллелизм присущ по самой их природе, процессы двух других групп могут включать и последовательно выполняемые шаги. Например, предусловия разных правил могут использовать одни и те же переменные, а операции, специфицированные разными активизированными правилами, могут потребовать соблюдения определенной последовательности выполнения.
В Станфордском университете в рамках проекта Advanced Architectures Project созданы два прототипа систем с доской объявлений, в которых использованы разные методики организации параллельной работы компонентов системы. Ниже мы приведем краткое описание этих разработок. Более детально читатель может познакомиться с ними в работе [Nii et al., 1988].
Система CAGE [Aietlo, 1986] является модификацией описанной выше инструментальной среды AGE и представляет собой мультипроцессорную вычислительную систему с общей памятью. В язык программирования системы включены конструкции, позволяющие описать параллельное выполнение некоторых фрагментов кода на уровне прикладной программы. В проекте параллельное выполнение реализовано на трех уровнях системы.
Параллельная работа источников знаний. Источники знаний могут параллельно работать с разными сегментами структуры данных доски объявлений или может быть использован режим конвейерной обработки, когда разные операции выполняются с разными сегментами данных, которые по очереди извлекаются из конвейера.
Параллельная реализация правил. Условия, специфицированные в разных правилах, могут анализироваться параллельно. Действия, указанные в правых частях правил, могут быть реализованы затем либо параллельно, либо поочередно.
Параллельный анализ условий. Условия, специфицированные в одном и том же правиле, также могут анализироваться параллельно.
Параллельная обработка источников знаний может выполняться как в синхронном, так и в асинхронном режимах. В первом приближении синхронизация нужна в том случае, когда выходные данные множества параллельных этапов обработки буферизуются до тех пор, пока не закончится выполнение всех параллельных процессов. Таким образом, передача выходных данных на доску объявлений задерживается до тех пор, пока все активизированные источники знаний не завершат свои операции. Пользователь также может задать в программе, как должны быть реализованы действия, предусмотренные в активизированных правилах, — параллельно или поочередно.
Эксперименты с системой CAGE разочаровали ее создателей. В системе, насчитывающей восемь процессоров, было достигнуто только двукратное повышение скорости вычислений в режиме параллельной синхронной обработки источников знаний, а при использовании четырех процессоров вообще не наблюдалось никакого изменения производительности. В асинхронном режиме при использовании восьми процессоров удалось повысить быстродействие менее чем в четыре раза. Эксперименты с использованием параллельной обработки правил привели примерно к пятикратному повышению производительности системы, состоящей из 16 процессоров.
Другая система, POLIGON, была разработана "с чистого листа" на базе мультипроцессорного вычислительного комплекса с распределенной памятью. В ней используется распараллеливание задачи на множестве уровней. Эксперименты с этой системой дали значительно более обнадеживающие результаты. Оказалось, что эффективность распараллеливания существенно увеличивается по мере роста объема данных в источниках знаний и количества правил, претендующих на активизацию.
Из сравнительного анализа двух систем был сделан вывод, что попытка запаралле-лить обработку отдельных этапов при сохранении режима централизованного управления всей системой (вариант системы CAGE) не может привести к успеху, а использование децентрализованного управления снижает возможности программного управления процессом логического вывода. Таким образом, первые работы в направлении реализации параллельного режима в системах с доской объявлений показали, что это задача далеко не тривиальная. Параллелизм может оправдать себя только в тех областях применения, где возрастающая сложность системы и значительное увеличение объема вычислений оправдываются результатами работы экспертной системы.
Из всех возможных последовательностей операций
(1) Из всех возможных последовательностей операций (частных решений) хотя бы одна должна приводить к корректной интерпретации.
(2) Процедура анализа имеющихся вариантов интерпретации должна давать корректному варианту более высокую оценку, чем другим конкурирующим вариантам. Другими словами, правильная интерпретация с учетом произношения должна быть оценена выше, чем другие варианты интерпретации, не учитывающие особенностей индивидуальной дикции.
(3) Вычислительные ресурсы (память и время вычислений), необходимые для отыскания правильной интерпретации, не должны превышать определенный порог. Система распознавания, которая через пару дней выдаст результат, пусть и правильный, и потребует памяти объемом несколько гигабайт, вряд ли кому-нибудь будет нужна.
В приведенном списке первое и третье требования в определенной мере противоречат друг другу. Для того чтобы корректное решение изначально присутствовало в пространстве гипотез, на стадии формирования гипотез поневоле приходится быть довольно расточительным, что при большом словаре может привести к комбинаторному взрыву элементов решений. Выход может быть найден только при использовании чрезвычайно остроумных эвристик. Таким образом, важнейшей предпосылкой достижения успеха в создании такой системы является разработка подходящей процедуры оценки вариантов (второе из перечисленных выше требований).
Почему для HEARSAY-II выбрантакая архитектура
Приступая к разработке системы, ее создатели прекрасно понимали, что с каждым уровнем анализа связана отдельная отрасль знаний — анализ звуковых сигналов, фонетика, лексический анализ, грамматика, семантика, ораторское искусство. Ни одна из этих отраслей по отдельности не способна предоставить достаточно информации для того, чтобы решить проблему. Представим, например, что, пользуясь методами обработки акустических сигналов, мы смогли разложить исходный звук на фонемы. Но без дополнительной информации все равно не удастся выделить смысл выражений, подобных следующим: l scream (я восклицаю) и ice cream (мороженое) или please let us know (пожалуйста, дайте нам знать) и please lettuce no (пожалуйста,- без салата). Таким образом, хотя каждый отдельный вид (набор) знаний играет существенную роль в решении проблемы и каждый из них может быть представлен в программе более или менее независимо от остальных, автоматическое распознавание речи требует использования всех этих знаний совместно.
При распознавании речи исследователям приходится сталкиваться еще с одной проблемой, которую также можно отнести к числу ключевых, — проблемой неопределенности. Она проявляется на всех уровнях представления информации:
данные неполные и зашумлены;
отсутствует однозначное соответствие между данными на соседних уровнях; примером может служить соответствие между уровнями фонем и лексических единиц при анализе фраз / scream и ice cream;
важную роль играют лингвистический и смысловой контексты; интерпретация соседних элементов делает более или менее вероятными разные варианты интерпретации текущего сегмента.
Более традиционные подходы к распознаванию речи основаны на использовании статистических моделей из теории передачи информации для определения корреляционной связи между сегментами. Подход, базирующийся на знаниях, потребовал существенного пересмотра методов обработки неопределенности.
В работе [Erman et al., 1980] перечислены следующие требования, которым должна удовлетворять эффективно работающая система распознавания речи, основанная на знаниях.
Принципы организации систем с доской объявлений
В основу организации систем этого типа положена следующая идея [Corkill, 1991].
Представьте себе группу экспертов, которые сидят возле классной доски (или большой доски объявлений) и пытаются решить какую-либо проблему.
Каждый эксперт является специалистом в какой-то определенной области, имеющей отношение к решению проблемы.
Формулировка проблемы и исходные данные записаны на доске.
Эксперты пытливо вглядываются в то, что написано на доске, и каждый из них думает над тем, чем он может помочь в решении проблемы.
Если кто-либо из экспертов чувствует, что ему есть что сказать по этому поводу, он выполняет соответствующие вычисления и записывает результат все на той же доске.
Этот новый результат может позволить и другим экспертам внести определенный вклад в решение проблемы.
Процесс прекращается (а эксперты расходятся по домам), когда проблема будет решена.
Такая методика совместного решения проблем будет эффективна, если соблюдаются определенные соглашения, а именно:
все эксперты должны говорить на одном и том же языке, хотя при записи результатов на доске могут использоваться и разные схемы обозначений;
должен существовать какой-то протокол определения очередности "выступлений", который вступает в силу в ситуации, когда сразу несколько экспертов хватаются за мел и направляются к доске.
Эти соглашения есть не что иное, как уже знакомые нам по предыдущим главам схемы представления управления.
Если рассматривать работающую по такому принципу систему с точки зрения организации процесса вычислений, то в системе можно выделить следующие структурные компоненты. Знания о предметной области разделены между независимыми источниками знаний (KS— knowledge sources), которые работают под управлением планировщика (scheduler). Решение формируется в некоторой глобально доступной структуре, которую мы будем называть доской объявлений (blackboard). Таким образом, в этой системе все знания "как поступить" будут представлены не в виде единственного набора правил, а в виде набора программ.
Каждый из компонентов этого набора может располагать собственным набором правил либо смесью правил и процедур.
Функции доски объявлений во многом сходны с функциями рабочей памяти в продукционных системах, но ее организационная структура значительно сложнее. Как правило, доска объявлений разделяется на несколько уровней описания, причем каждый уровень соответствует определенной степени детализации. Данные в пределах отдельных уровней доски объявлений представляют иерархии объектов или графы, т.е. структуры более сложные, чем векторы, которые использовались в рабочей памяти продукционных систем. В самых современных системах может быть даже несколько досок объявлений.
Источники знаний формируют объекты на доске объявлений, но это выполняется посредством планировщика. Обычно записи активизации источников знаний (knowledge source activation records) помещаются в специальный список выбора (agenda), откуда их извлекает планировщик. Источники знаний общаются между собой только через доску объявлений и не могут непосредственно передавать данные друг другу или запускать выполнение каких-либо процедур. Здесь есть определенная аналогия с организацией работы продукционных систем, в которых правила также не могут непосредственно активизировать друг друга: все должно проходить через рабочую память.
В этой главе будет представлен обзор становления архитектуры систем с доской объявлений и рассказано о том, как в настоящее время эта модель используется в качестве базовой при создании инструментальных систем общего назначения для проектирования экспертных систем. Принципы работы модели будут проиллюстрированы примерами, но основное внимание мы сосредоточим на общей архитектуре систем такого типа, а не на детальном описании отдельных моделей. В заключительном разделе будет рассказано о попытках повысить производительность системы с помощью методов параллельного поиска.
Рекомендуемая литература
Для первого знакомства с принципами построения экспертных систем на основе доски объявлений я бы рекомендовал прочесть обзорные работы [Nil, 1986, а, b]. Подборка статей об исследованиях в этом направлении опубликована в сборнике [Englemore and Morgan, 1988]. С точки зрения технологии экспертных систем особый интерес представляют главы 5 и 6, в которых описаны некоторые ранние системы с такой архитектурой, не рассмотренные в данной книге, глава 12, содержащая достаточно подробное описание системы AGE, и глава 26, в которой кратко описана реализация системы GBB.
Тем, кто желает детальнее познакомиться с системами GBB и ERASMUS, я рекомендую работу [Jagannathan et al., 1989]. Информация о проекте Advanced Architectures Project и разработанных в его рамках системах CAGE и POLIGON опубликована в работе [Rice, 1989]. Прилагаемый к ней список публикаций результатов, полученных в ходе работы над этим проектом, послужит хорошим путеводителем тем, кто захочет глубже с ним познакомиться.
Среди прочих работ, касающихся проблематики систем с доской объявлений, я бы выделил книгу [Craig, 1995] и обзорную статью [Carver and Lesser, 1994].
СистемHEARSAY-III— оболочкдля создания систем с доской объявлений
Система HEARSAY-III — это оболочка системы с доской объявлений, созданная на базе HEARSAY-II точно так же, как оболочка продукционной системы EMYCIN была создана на базе MYCIN [Erman et al, 1983]. В структуру HEARSAY-III, помимо источников знаний и доски объявлений, включена еще и реляционная база данных, с помощью которой выполняется обслуживание объектов доски объявлений и планирование. Это позволило существенно упростить механизм выбора записей активизации источников знаний. Язык управления базой данных АРЗ основан на языке InterLISP и позволяет программировать выполнение ряда функций оболочки [Goldman, 1978].
Структурные компоненты доски объявлений— это объекты языка АРЗ. Такой объектно-ориентированный подход упрощает представление и операции с данными и частными решениями.
Активизация источников знаний реализуется с помощью управляемых образцами демонов АРЗ (о демонах рассказано в главе 6).
АРЗ поддерживает и операции с базой данных контекстов (о контекстах см. в главе 17), а условия превращения контекста в "отравленный" представлены в виде ограничений языка. Контексты можно использовать для организации набора альтернативных способов продолжения вычислений.
Источник знаний в экспертной системе, создаваемой на базе оболочки HEARSAY-I1I, должен состоять из пускового образца (trigger), первичной программы (immediate code) и тела (body). Обнаружив соответствие между текущим содержимым доски объявлений и пусковым образцом, оболочка создает узел записи активизации для этого источника знаний и запускает на выполнение первичную программу. Спустя некоторое время запись активизации источника знаний выбирается планировщиком и тогда запускается на выполнение тело источника знаний, которое представляет собой программу на языке LISP. В состав HEARSAY-III входит простейший планировщик, который выполняет базовые функции планирования в экспертной системе: выбор очередной записи в списке актуальных и запуск на выполнение программного кода соответствующего источника знаний.
Пусковой образец имеет вид шаблона на языке АРЗ и представляет собой предикат, примитивами которого являются шаблоны фактов и произвольные предикаты языка LISP. Всякий раз, когда база данных модифицируется и оказывается, что текущие данные в ней сопоставимы со всеми шаблонами в образце, создается узел записи активизации, который хранит название источника знаний, пусковой контекст и значения переменных, полученные в результате сопоставления. При создании записи активизации выполняется первичная программа источника знаний. Эта программа, написанная на языке LISP, может связывать с узлом записи активизации некоторую информацию, которая позже может быть использована при выполнении тела источника. Первичная программа выполняется в пусковом контексте и в ней могут использоваться конкретизированные в этом контексте переменные образца. Значение, возвращаемое первичной программой после завершения, — это имя какого-либо из классов узлов доски объявлений. Затем запись активизации помещается на доску объявлений в качестве узла этого класса.
Некоторое время спустя базовый планировщик системы, который входит в состав оболочки HEARSAY-III, инициирует выполнение какой-либо операции с записью активизации. Как правило, это выполнение тела источника знаний в пусковом контексте с означенными переменными. Каждый сеанс выполнения тела источника знаний неделим — это аналог транзакции в системах управления базами данных. Сеанс продолжается до полного завершения и не может быть прерван для активизации любого другого источника знаний.
При проектировании прикладной экспертной системы на базе оболочки HEARSAY-III нужно самостоятельно разработать процедуру базового планировщика, которая будет вызываться оболочкой после запуска. Эта процедура может быть достаточно простой, поскольку большая часть знаний о планировании может быть включена в планирующие источники знаний. Например, базовый планировщик может представлять собой простейшую циклическую процедуру, которая извлекает первый элемент из очереди, организованной планирующими источниками знаний, и запускает его выполнение.Если обнаруживается, что очередь пуста, базовый планировщик завершает работу системы.
Основные достоинства среды HEARSAY-III — это, во-первых, использованный в ней режим управления, который предоставляет разработчикам прикладных экспертных систем большую свободу в выборе способов представления и применения эвристик отбора активизируемых записей источников знаний, а во-вторых, структуризация множества объектов доски объявлений.
СистемPROTEAN
Система PROTEAN [Hayes-Roth et al., 1986] предназначалась для идентификации трехмерных структур протеинов. Комбинаторные свойства пространства решений не позволяют использовать методику исчерпывающего поиска, поэтому в программе реализована стратегия последовательного уточнения на основе определенного плана управления.
При формировании гипотез в системе PROTEAN локальные и глобальные ограничения используются в комбинации. Локальные ограничения дают информацию о близости атомов в молекуле, а глобальные — информацию о размерах молекулы и ее форме.
Вместо того чтобы пытаться применить все ограничения к анализируемой молекуле в целом, в системе PROTEAN успешно используется подход "разделяй и властвуй" при определении частных решений, которые могут включать разные подмножества элементов структуры протеина и разные подмножества ограничений.
Логический вывод в системе PROTEAN двунаправленный и базируется на использовании доски объявлений с четырьмя уровнями. Когда реализуется нисходящая стратегия (сверху вниз), система использует гипотезы на одном уровне для определения положения на другом, более низком; когда же реализуется восходящая стратегия (снизу вверх), гипотезы на одном уровне используются в качестве ограничений для другого, более верхнего.
Управляющие знания в системе PROTEAN также разделены на разные уровни абстракции. Самый верхний уровень определяет стратегию решения конкретной проблемы. На промежуточном уровне система фиксирует отдельные этапы, необходимые для реализации общей стратегии, а потому программа всегда может получить информацию о том, на какой стадии решения она находится. Нижний уровень управления отвечает за ранжирование записей активизации источников знаний.
Система PROTEAN представляет для нас особый интерес тем, что она демонстрирует, как в рамках архитектуры ВВ1 можно комбинировать независимые от предметной области механизмы логического вывода и зависимые от предметной области знания об ограничениях.
Системы HEARSAY, AGE и ОРМ
Архитектура на основе доски объявлений "выросла" из разработанной в конце 70-х годов системы распознавания речи HEARSAY [Erman et al., 1980]. Программирование компьютера с целью распознавания речи — это одна из наиболее сложных задач, за которые когда-либо брались специалисты в области искусственного интеллекта. Ее решение требует:
сложной обработки сигналов;
сопоставления физических характеристик звуковых сигналов с символическими элементами естественного языка;
выполнения поиска в большом пространстве возможных интерпретаций, в котором объединены эти разные по своей природе элементы.
Для решения этой проблемы была выбрана методика, основанная на выделении нескольких уровней абстракции описания анализируемых данных. Самым нижним является уровень физических акустических сигналов, на котором формируется звуковой спектр анализированных сигналов. На последующих уровнях информация проходит через напластование лингвистических абстракций со все более увеличивающимся уровнем общности понятий — фонемы, силлабы (созвучия), морфемы, слова, выражения и предложения.
Системы с доской объявлений
18.1. Принципы организации систем с доской объявлений
18.2. Системы HEARSAY, AGE и ОРМ
18.3. Среда с доской объявлений ВВ
18.4. Эффективность и гибкость модели с доской объявлений
18.5. Организация параллельных вычислений в системах CAGE и POLIGON
Рекомендуемая литература
Упражнения
В последние годы в разработке архитектуры экспертных систем появилось новое направление, которое получило название системы с доской объявлений (blackboard sys-tems)u. Системы с такой архитектурой могут эмулировать режим построения как прямой цепочки логического вывода, так и обратной, а также попеременно применять эти режимы в процессе работы. Кроме того, применение систем с доской объявлений побуждает инженеров по знаниям к иерархической организации и знаний относительно предметной области, и пространства частичных и полных решений. Таким образом, эта архитектура очень хорошо подходит для решения задач проектирования, для которых характерно большое, но факторизуемое многомерное пространство решений. Системы с подобной архитектурой уже успешно применяются для интерпретации данных (например, распознавания графических изображений и речи), анализа и синтеза многокомпонентных структур (например, структуры протеинов) и планирования.
Но следует отметить, что реализация и внедрение систем с доской объявления — довольно сложный процесс, а сами системы требуют значительных вычислительных ресурсов. В этой главе будут рассмотрены следующие вопросы:
структура систем с доской объявлений;
анализ существующих на сегодняшний день систем этого типа и областей их применения;
обсуждение проблем реализации систем с доской объявлений и их эффективности.
Будет показано, что в системах с доской объявлений применяется комбинация нескольких схем представления знаний, которые мы рассматривали в предыдущих главах, но при этом между отдельными схемами существует значительно более тесная связь, чем в многофункциональных инструментальных средах, о которых упоминалось в главе 17.
Системы ВВи ACCORD
Перечисленные выше особенности архитектуры среды ВВ можно проиллюстрировать на примере систем ВВ 1 и ACCORD.
Как и в других системах, использующих модель доски объявлений, в системе ВВ 1 источники знаний активизируются событиями на связанном с этими источниками уровне доски объявлений, в результате чего формируется запись активизации источника знаний [Johnson and Hayes-Roth, 1986]. Собственно активизация источника знаний откладывается. Запись активизации находится в списке заявок до тех пор, пока не будут выполнены все предусловия, которые, как правило, связаны со свойствами объектов доски объявлений. Но помимо доски объявлений и источников знаний предметной области, система ВВ1 управляет также и источниками знаний управляющей доски объявлений. Планировщик организует исполнение активизированных источников знаний обоих типов — и предметной области и управления — в соответствии с планом, который динамически корректируется компонентами управляющей доски объявлений. Результат активизации источника знаний сказывается на состоянии уровня доски объявлений, подключенного к его выходу, и таким образом активизируются другие источники знаний.
Основной цикл работы ВВ1 состоит из следующих операций.
(1) Интерпретация действия, предусмотренного очередной записью активизации источника знаний.
(2) Обновление списка заявок — добавление в него новых записей, порожденных изменением данных, вызванных предыдущей операцией, — и сортировка всех записей в списке заявок в соответствии с текущим планом.
(3) Выбор записи с наибольшим рейтингом.
ACCORD — это язык для представления знаний, касающихся выполнения задач сборки многокомпонентных объектов с соблюдением заданных ограничений. Метод сборки компонентов не предусматривает какого-либо наперед заданного режима управления, но требует принятия множества решений при конструировании отдельных узлов. Основной механизм представления предполагает использование иерархии понятий — типов, представителей и экземпляров.
Типы определяют родовые понятия и их роли, в отличие от того, как это делается в семантических сетях с помощью связей типа IS-A (это есть).
Представители — это конкретизированные типы, а экземпляры — объекты, созданные при означивании представителей в определенном контексте. Понятия могут иметь атрибуты и входить в определенные отношения с другими понятиями. Здесь имеется определенная аналогия со связями типа IS-A в семантических сетях.
Оболочка, таким образом, предоставляет в распоряжение пользователя скелетные ветви иерархической структуры объектов-компонентов, которые должны образовать единый ансамбль, контексты их компоновки и ограничения, в которые эта компоновка должна "вписываться". Например, ACCORD представляет следующие роли, независимые от предметной области: arrangement (сборка), partial-arrangement (узел) и included-object (компонент). Между ролями имеется отношение типа includes (включает). Среди ролей included-object важное место отводится роли anchor (якорь), представляющей объект, положение которого в общем ансамбле (сборке) должно быть фиксированно, и таким образом определяет локальный контекст для узла. Ролью anchoree представлен объект included-object, который имеет, как минимум, одно ограничение, связанное с его положением относительно объекта anchor.
Средс доской объявлений ВВ
В работе [Hayes-Roth et al, 1988] описана среда ВВ для построения экспертных систем, использующих модель доски объявлений с трехуровневой структурой. Система четко разделена на три уровня — прикладные программы, оболочки задач и архитектуры, — которые, несмотря на такое явное разделение, довольно тесно интегрированы. При разработке акцент сделан на те интеллектуальные системы, которые должны обладать способностью судить о собственном поведении, используя для этого знания о возникающих событиях, состояниях, действиях, которые можно предпринять, и отношениях, существующих между событиями, действиями и состояниями.
Сравните использование разных вариантов архитектуры
1. Что такое источник знаний в системе с доской объявлений?
2. Сравните использование разных вариантов архитектуры экспертных систем — продукционную систему и систему с доской объявлений. При каких условиях можно считать оправданным усложнение системы, использующей модель с доской объявлений.
3. В чем различие между системами с доской объявлений и многофункциональными инструментальными средами, описанными в главе 17.
4. Прочтите работу [Nil et al, 1988] и составьте краткий обзор характеристик систем CAGE и POLIGON. Особое внимание в этом обзоре уделите анализу отличий между методами принятия решений, использованными в каждой из систем, их достоинствам и недостаткам.
5. Подумайте над тем, как в рамках архитектуры систем с доской объявлений организовать систему планирования мероприятий, выполняющую те же функции, что и описанная в главе 15. Какие источники знаний целесообразно использовать в ней для формирования начального наброска плана, для его уточнения и для окончательной проверки совместимости всех этапов.
6. Придумайте задачу, при решении которой в полной мере могут проявиться достоинства структуры с доской объявлений. Какие источники знаний должны быть использованы в системе, предназначенной для решения этой задачи. Например, при расследовании происшествия, повлекшего за собой смерть пловца, пользовавшегося для плавания под водой дыхательным аппаратом, власти стараются рассмотреть множество аспектов происшествия, которые могут быть представлены в разных источниках знаний. Ниже приводится их примерный перечень.
Условия, связанные с внешней средой:
состояние воды;
неблагоприятные течения;
потенциальные ловушки;
опасности, связанные с судоходством;
опасности, исходящие от обитателей морских глубин.
Нарушения в работе технических средств:
пользование техническими средствами;
обслуживание технических средств. Характеристика потерпевшего:
опыт и тренировка;
психологические проблемы;
химические проблемы, например употребление наркотиков;
физическое состояние.
Подумайте над тем, как управлять применением знаний в приложении. Будут ли источники знаний функционировать независимо друг от друга, посылая в любое время сообщения доске объявлений, или будут активизироваться по очереди. Например, в описанной выше задаче расследования можно организовать режим поочередного использования источников знаний каждой из перечисленных категорий в заранее заданном порядке.
Уровни абстракции в среде ВВ
18.3.1. Уровни абстракции в среде ВВ
На верхнем уровне абстракции — уровне архитектуры — представлен набор базовых структур знаний (представляющих действия, события, состояния и т.п.) и механизм, который служит для отбора и реализации действий. Этот вид знаний обособлен не только от конкретной предметной области, но также независим и от метода решения отдельных задач и проблемы в целом. Идея состоит в том, что архитектура проектируемой системы должна обеспечивать поддержку решения разнообразных задач в множестве предметных областей (точно так же и способность человека мыслить не связана с какой-либо отдельной задачей или областью знаний). На этом же уровне представлены и способности рассуждать о поведении, обучаться и пояснять свои действия.
Оболочки задач — это следующий, более низкий уровень абстракции. На нем представлены промежуточные структуры знаний о действиях и событиях, касающихся определенной задачи, например о неисправностях в тестируемой системе или о конструкциях, удовлетворяющих определенным ограничениям. Методы, которые представлены на этом уровне, могут быть общими для нескольких родственных предметных областей. Здесь есть прямая аналогия с тем, как человек планирует свои действия в разных ситуациях, используя ограниченный набор опробованных стратегий. Примером такой оболочки может служить система ACCORD, которая решает задачу планирования сборки изделия из множества компонентов.
Наиболее специфический уровень — прикладной, на котором сконцентрированы структуры знаний о конкретных действиях в конкретных обстоятельствах и методы решения конкретных классов проблем. Примером системы, в которой используется этот уровень, являются PROTEAN — система вывода структуры протеинов при заданных ограничениях [Hayes-Roth et al, 1986] и SIGHTPLAN — система проектирования архитектурных планировок [Tommelein et al., 1988].
Использование систем отслеживания истинности предположений для диагностирования носнове моделей
Выше, в главах 11 и 12, были рассмотрены экспертные диагностические системы, в которых использовался метод эвристической классификации. Этот метод предполагает, что большая часть знаний представлена в виде эвристических правил, связывающих абстрактные категории данных (типичные симптомы) с абстрактными категориями решений (типичные неисправности). Такая форма представления знаний иногда называется "поверхностной", поскольку знания не содержат информации о причинных связях между симптомами и неисправностями (теорию функционирования диагностируемого объекта — машины или живого организма), а отражают только эмпирический опыт. Информация о причинно-следственных связях, определяющих поведение и свойства диагностируемого объекта, принято называть "глубинным" знанием.
Диагностирование, основанное на моделях анализируемых объектов, использует не столько эмпирический опыт эксперта, сколько более или менее полную и непротиворечивую теорию корректного поведения этих объектов. Идея состоит в том, чтобы, располагая на входе данными о наблюдаемых отклонениях в поведении, высказать предположение об одном или нескольких возмущениях в описании системы, которые могли бы объяснить эти отклонения.
Очевидные преимущества подхода, при котором сначала принимаются во внимание знания о принципах поведения объекта, а уже затем эмпирические знания, состоят в следующем.
Располагая информацией о принципах структурной организации объекта и причинно-следственных связях между свойствами его компонентов и наблюдаемыми проявлениями, разработчик программы может значительно сократить трудоемкий процесс извлечения эмпирических знаний эксперта.
Используемый метод анализа причинно-следственных связей не зависит от самого анализируемого объекта, а следовательно, отпадает необходимость в трудоемкой настройке механизма логического вывода для каждого отдельного приложения.
Поскольку требуется знание только о корректном поведении объекта, потенциально метод должен сработать и при диагностировании неисправностей, которые ранее не возникали и незнакомы эксперту-человеку.
Прототипом подобного рода диагностических экспертных систем можно считать программу DART [Genesereth, 1984]. Хотя предметной областью, для которой предназначалась эта программа, является анализ цифровых схем, но использованные в ней язык представления знаний и механизм логического вывода более или менее независимы от этой предметной области. Для представления описания конструкции диагностируемого устройства используются формализм исчисления предикатов и форма доказательства теорем, с помощью которых формируются множества "подозрительных" компонентов и тестов, призванных подтвердить или опровергнуть гипотезы о причинах неисправностей. Метод решения проблем, использованный в DART, опирается на три упрощающих допущения.
(1) Предполагается, что связи между компонентами функционируют правильно, и задача состоит в том, чтобы отыскать те компоненты, неисправность которых может объяснить наблюдаемые симптомы неправильной работы устройства.
(2) Отказы не носят случайного во времени характера, т.е. все компоненты в процессе выполнения диагностических тестов работают стабильно (правильно или неправильно — это уже другой вопрос).
(3) В устройстве имеется единственный отказ.
Каждое из этих предположений, конечно же, очень ограничивает возможность практического применения системы, но в работе [De Kleer and Williams, 1987] было показано, что использование систем отслеживания истинности предположений, основанных на анализе допущений, поможет снять третье из перечисленных ограничений. Это было продемонстрировано в программе GDE (General Diagnostic Engine — система диагностирования общего назначения).
В системе диагностирования, допускающей наличие нескольких неисправностей в устройстве, приходится иметь дело с экспоненциальным ростом пространства гипотез. Чтобы преодолеть возникающие при этом сложности, нужно формировать гипотезы в определенном порядке, принимая во внимание их "конструктивность", а затем выполнять такие процедуры тестирования, которые позволят выбрать из набора конкурирующих гипотез наиболее подходящую, проведя при этом минимальное количество дополнительных измерений.
Их можно определить, формируя дедуктивное замкнутое выражение для среды и данных, а затем выискивая в нем противоречие. Главная цель системы отслеживания истинности предположений состоит при этом в том, чтобы идентифицировать все минимальные конфликтующие множества. После этого можно определить минимальное множество отказавших компонентов, которое объяснит все наблюдаемые проявления ненормальной работы устройства.
В качестве простого примера рассмотрим решетку сред, представленную на рис. 19.6. В этой решетке C1, C2 и СЗ— компоненты анализируемого устройства. Пусть S — множество наблюдаемых проявлений ненормальной работы этого устройства. Предположим, нам известно, что если наблюдается множество проявлений S, то С1 и С2 не могут быть исправными одновременно, а также С1 и СЗ. Тогда можно выделить среды, помеченные на схеме решетки значками 0, С2 и СЗ (они выделены на схеме как несовместные). Каждая из этих сред имеет какое-либо запрещенное сочетание исправных компонентов. Все другие среды являются кандидатами в пространстве гипотез, но очевидно, что минимальные множества среди них — (С1} и {С2, СЗ}.
В системе отслеживания истинности предположений используется несколько стратегий управления обработкой пространства кандидатов, например:
стратегия, основанная на предоставлении преимущества тем гипотезам, которые поясняются проще всего; поиск решения начинается с минимальных по объему (количеству элементов) конфликтных множеств;
сохранение в системе просмотренной цепочки логического вывода, что позволяет исключить ее повторный просмотр.
В системе GDE также используется мера неопределенности, основанная на теоретико-информационном подходе, с помощью которой выясняется, какие измерения следует выполнить в анализируемой системе. Наилучшей полагается такая измерительная процедура, которая минимизирует энтропию (см. об этом в главе 20), т.е. та, которая вносит наибольшее разнообразие в набор значений вероятностей кандидатов. Предполагается, что априорная вероятность отказа отдельных компонентов известна и что отказы компонентов в вероятностном смысле независимы.Эти же вероятности используются при определении порядка формирования гипотез-кандидатов.

Рис. 19.6. Решетка сред, представляющая пространство кандидатов. Несовместные контексты выделены утолщенным контуром, а минимальные кандидаты заштрихованы
Реализуется такой процесс с помощью комбинации методов отслеживания истинности предположений, основанных на анализе допущений, и методов вероятностного логического вывода.
Как было показано ранее в этом же разделе, методы отслеживания истинности предположений, основанные на анализе допущений, имеют дело с решеткой сред — альтернативных состояний модели мира, которые согласуются с некоторой теорией, но используют при этом отличающиеся допущения. В диагностических приложениях такой неявной теорией является описание диагностируемого устройства, а альтернативные состояния модели мира характеризуются различными комбинациями отказавших компонентов устройства. Если устройство состоит из п компонентов, то теоретически может существовать 2" комбинаций отказов компонентов. Решетка вариантов сред является перечислимым множеством присоединений: элемент с наименьшим номером соответствует отсутствию отказов в компонентах, а элемент с наибольшим номером — отказу всех компонентов устройства. Каждая такая среда называется кандидатом, т.е. гипотезой о том, что именно произошло в неисправном устройстве. Вся решетка сред при такой постановке проблемы будет представлять собой пространство кандидатов.
Если устройство работает нормально, то гипотеза, соответствующая кандидату' с наименьшим номером, прекрасно "объясняет" наблюдаемую ситуацию. Если наблюдаются какие-либо отклонения от нормального функционирования устройства, то наблюдаемые проявления можно считать свидетельствами в пользу той или иной гипотезы в пространстве кандидатов. Поскольку объем этого пространства связан с количеством компонентов в анализируемых устройствах экспоненциальной зависимостью, необходимо использовать в нем какой-либо метод эффективного поиска кандидатов.
Ключевым понятием для такого метода должно быть конфликтующее множество — множество таких компонентов, которые в данной ситуации (т.е. при данных симптомах) не могут одновременно быть исправными. Конфликтующее множество, таким образом, это именно то множество допущений, которое в системе отслеживания истинности предположений, основанной на анализе допущений, формирует среды, несовместимые с данными.
Немонотонное обоснование
Подход, предложенный Дойлом [Doyle, 1979], отличается от того, который применил Мак-Аллестер. Он основан на философии "здравого смысла", в частности на презумпции значения по умолчанию. В первом приближении, помимо хранения допущений, подтвержденных какими-либо свидетельствами, хранятся также допущения, основанные на резонном предположении, т.е. допущения, свидетельства против которых отсутствуют.
Обоснования (или, пользуясь терминологией Доила, резоны) в пользу допущения Р представляют собой упорядоченную пару списков (INP, OUTp ). Список INp— обычные обоснования в форме, которая аналогична использованной Мак-Аллестером. Он содержит высказывания, истинность которых является необходимым условием истинности Р. Список OUTp содержит высказывания, присутствие которых во множестве допущений указывает на ложность Р. Это множество получило название множества немонотонных обоснований (nonmonotonic justification), поскольку добавление высказывания в него потребует отказаться от сделанного ранее допущения. В подходе, который рассматривался Мак-Аллестером, этот вариант не анализировался.
Пусть, например, обоснование для значения р имеет вид
({}, {-p}).
Это означает, что можно предполагать наличие р до тех пор, пока это обоснование не станет ложным. Обоснование для q пусть имеет вид
({p}, {r}).
Такое обоснование означает, что можно предполагать наличие q до тех пор, пока высказывание р присутствует в множестве текущих допущений (в терминологии Доила — получает статус поддержки (support status) "включено" — in), а высказывание r отсутствует в множестве допущений (в терминологии Доила — получает статус поддержки "исключено" — out). Обратите внимание на то, что обоснования могут быть связанными, как в приведенном выше примере. Если -р имеет статус исключено, то, следовательно, р имеет статус включено, а тогда и q имеет статус включено до тех пор, пока r имеет статус исключено.
Такая цепочка причинно-следственных связей называется SL-обоснованием (SL — сокращение от support list).
Общее правило для SL-обоснований гласит, что допущение Р присутствует в текущем множестве допущений только в том случае, если каждое из допущений, перечисленных в списке IN, имеет статус включено, а каждое из допущений, перечисленных в списке OUT, имеет статус исключено.
Дуальная структура обоснований, предложенная Дойлом, может быть использована для разделения допущений на три группы.
(1) Посылки (premises), т.е. высказывания, которые полагаются истинными без всякого обоснования (по определению). Пользуясь обозначениями из теории множеств, можно следующим образом представить определение посылки:
{Р

(2) Дедукции (deductions), т.е. высказывания, которые являются заключениями нормальной монотонной дедукции. В обозначениях теории множеств дедукции представляются выражением
(2) Проверить консеквенсы данного узла. Если таковых не существует, то изменить статус узла с исключено на включено, сформировать связанные с ним списки IN и OUT и на этом закончить. В противном случае сформировать список L, в который включить узел и его множество последствий, зафиксировать статус включено-исключено каждого из этих узлов, временно присвоить им статус nil и перейти к шагу (3).
(3) Для каждого узла N из списка L попытаться отыскать действительное и убедительное обоснование, которое позволяет изменить статус этого узла на включено. Если таковое найдено не будет, присвоить узлу статус исключено. В любом варианте изменения статуса узла распространить это изменение на его консеквенсы. (Примечание. Обоснование является действительным, если каждый узел, перечисленный в его списке IN, имеет статус включено, а каждый узел, перечисленный в списке OUT, — статус исключено. Обоснование является убедительным в том случае, когда в его логической цепочке отсутствует зацикливание. Например, обоснования ({-Р},{}) и ({},{Р}) являются зацикленными по отношению к Р. Из первого следует, что Р имеет статус включено только в случае, если —P также имеет статус включено, а из второго следует, что Р имеет статус включено только в случае, если Р имеет статус исключено. Таким образом, каждое обоснование, если применить его в отношении высказывания Р, приводит к противоречию.)
(4) Если некоторый узел в списке L имеет состояние включено и отмечен как противоречивый, то запустить процедуру обратного прослеживания, ведомого зависимостями (dependency-directed backtracking). Если в процессе выполнения этой процедуры вновь возникнут условия для запуска процесса отслеживания истинности предположений (шаги (1)-(3)), повторять эти шаги до тех пор, пока не будут разрешены все противоречия.
(5) Сравнить текущий статус поддержки каждого узла из списка L с его прежним статусом, зафиксированным ранее, и известить пользователя обо всех произведенных изменениях статуса.
Обе системы — и Мак-Аллестера, и Доила — демонстрируют более "интеллектуальный" подход к решению проблемы адекватного и непротиворечивого описания мира, чем тот, который был использован в рассмотренной ранее системе STRIPS (см. главу 7). В обоих случаях системы отслеживания истинности предположений берут на себя заботы об обновлении модели мира посредством распространения аналогов операций ADD и DELETE по сети зависимостей. Если при этом обнаруживается, что в модели возникли противоречия, пользователю предлагается отказаться от какой-либо из посылок, которые послужили причиной такого противоречия, и восстановить тем самым целостность модели.
19.2. Пара конфликтующих выражений
Приведенная ниже программа на языке CLIPS реализует простой алгоритм отслеживания истинности предположений по отношению к простым атомарным выражениям. Литералы являются атомарными высказываниями, имеющими статус либо включено, либо исключено. Список inlist некоторого выражения включает те выражения, которые должны иметь статус включено для того, чтобы и данное выражение имело статус включено. Список outlist некоторого выражения включает те выражения, которые должны иметь статус исключено, для того, чтобы данное выражение имело статус включено. Как и ранее, пустые списки поддержки по умолчанию имеют значение -1.
;; ШАБЛОНЫ
;; Литерал - атомарное высказывание.
(deftemplate literal (field id (type INTEGER})
(field atom (type SYMBOL))
(field status (type SYMBOL) (default unk))
(multifield inlist (type INTEGER) (default -1))
(multifield outlist (type INTEGER) (default -1))
)
;; Исходная модель мира.
(deffacts model
(literal (id 0) (atom P) (status in) (outlist 1) )
(literal (id 1) (atom Q) (status in) (outlist 0) )
)
;; ПРАВИЛА
;; Если выражение в списке outlist
;; выражения S имеет статус out
;; и выражение S имеет пустой список inlist,
;; то присвоить выражению S статус in.
(defrule in
(literal (id ?A) (status out)) ?F <-
(literal (status out) (inlist -1) (outlist ?A))
=> (modify ?F (status in))
)
Если выражение в списке outlist выражения S имеет статус in, то присвоить выражению S статус out. Обратите внимание на то, что в этом правиле наличие списка inlist для выражения S не имеет значения,
(defrule out
(literal (id ?A) (status in)) ?F <-
(literal (status in) (outlist ?A)) =>
(modify ?F (status out)) )
;; Это правило предлагает пользователю удалить
;; выражение и таким образом уладить конфликт,
(defrule deny
(declare (salience -10))
?L <- (literal (atom ?X) (status in) (inlist -1)) =>
(printout t crlf "Deny " ?X "? ")
(bind ?ans (read)) (if (eq Pans yes)
then (modify PL (status out)))
;; Что произойдет после того, как вы
;;запустите эту программу на выполнение?
;;Как ! будет вести себя программа, если
;;в ответ на запрос, сформированный правилом
;; deny, ввести yes? Как будет
;;вести себя программа, получив ответ по?
Отслеживание истинности предположений, основанное нанализе допущений
В системах отслеживания истинности предположений, основанных на анализе допущений {assumption-based truth-maintenance system), программа имеет дело с несколькими отличающимися контекстами, которые принято называть средами обитания (environments) [De Kleer, 1986]. Удобнее всего представить себе среду обитания как взгляд на мир через призму определенных допущений. Можно считать, что модель мира, которая использовалась в предыдущих разделах, характеризуется пустым множеством допущений. Все прочие среды, имеющие непустое множество допущений, представляют модели гипотетических миров.
В системах отслеживания истинности предположений, основанных на допущениях, различные варианты сред обитания можно организовать в виде решетки, поскольку допущения носят инкрементальный характер. Модель, показанная на рис. 19.3, представляет на самом нижнем уровне автомобиль, в котором не горит свет и который не удается завести. На более верхнем уровне решетки находятся гипотетические миры, в которых сделаны некоторые допущения о неисправностях в автомобиле, например разряжена аккумуляторная батарея. На еще более высоком уровне можно комбинировать сделанные допущения. Обратите внимание — чем выше мы поднимаемся "по ступеням решетки", тем более специфическими становятся гипотетические миры в том смысле, что мы характеризуем их все полнее.
Не всегда можно делать произвольные допущения. Например, нельзя объединить допущения {p,q} и {—p,r}, поскольку такая комбинация будет противоречивой. Более того, хотя само множество допущений может и не быть антагонистическим, определенные комбинации допущений могут привести к противоречию, если принять во внимание и другую имеющуюся в нашем распоряжении информацию.
Предположим, что наша модель неисправного автомобиля содержит информацию о том, что одновременно не может случиться так, чтобы и карбюратор не работал из-за избытка топлива, и в баке отсутствовал бензин. Следовательно, в том варианте среды, в котором сделано допущение "в баке отсутствует бензин", не может присутствовать допущение "избыток топлива в карбюраторе".
Такое логическое заключение образует контекст среды — множество высказываний, производных от сделанных допущений, и фактов, имеющихся в исходной модели мира. Например, мы можем оказаться в ситуации, представленной схематически на рис. 19.4. Здесь среда, образованная в результате объединения двух допущений, должна быть исключена из рассмотрения, поскольку ее контекст становится несовместимым (nogood).

Рис. 19.3. Решетка сред
Приведенный выше пример может служить наглядной иллюстрацией того очевидного факта, что имеющуюся теорию мира (предметной области) допускается расширять, только принимая во внимание "фоновые" знания об этой предметной области. Другими словами, между отдельными допущениями существуют определенные зависимости, которые мы должны каким-либо образом зафиксировать и не нарушать.
В системах отслеживания истинности предположений, основанных на анализе допущений, такие зависимости называются обоснованиями (justification). Конечно, такая вольная трактовка термина "обоснование" вносит некоторую неоднозначность в изложение материала (ранее мы придавали этому термину несколько другой смысл), но дело в том, что обоснование в тех системах, которые рассматриваются в данном разделе, играет роль, отличную от обоснований в простых системах отслеживания истинности, анализированных Мак-Аллестером и Дойлом. В тех системах обоснования формировались программой в результате распространения принуждений и связывались с узлами сети зависимостей, которые представляли высказывания.
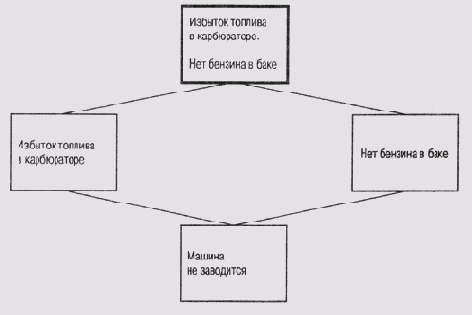
Рис. 19.4. Решетка сред, в которой выделен несовместный контекст
В системах отслеживания истинности предположений, основанных на анализе допущений, обоснования являются частью исходной информации, которой программа располагает в момент запуска на выполнение. Затем система для каждого узла высказывания формирует ярлык (label), который содержит список сред, имеющих отношение к этому высказыванию ("интересующих" это высказывание). Ниже мы увидим, что скрывается за этим "интересом", но сначала рассмотрим пример.
Такой список может быть созвучным (sound), завершенным (complete), совместимым (consistent) или минимальным (minimal) ярлыком. В эти термины вкладывается следующий смысл.
Ярлык является созвучным, если высказывание, к которому он относится, является производным от каждой среды, включенной в этот ярлык, т.е. оно имеет статус включено в контексте каждой такой среды.
Ярлык является завершенным, если любая непротиворечивая среда, в которой имеет место соответствующее высказывание, либо присутствует в списке, либо образована включением дополнительных допущений в ту среду, которая присутствует в списке.
Ярлык является совместимым, если любая среда, включенная в список, является непротиворечивой.
Ярлык является минимальным, если ни одна среда, включенная в список, не образуется добавлением какого-либо допущения к той среде, которая также присутствует в списке.
Если узел высказывания в сети имеет пустой ярлык, это означает, что высказывание не является производным ни от какого совместимого множества допущений. Другими словами, это высказывание не может быть истинным ни при каких совместимых комбинациях допущений. Например, ярлык узла, соответствующего высказыванию "отсутствует бензин в баке и влажные свечи", будет иметь пустой список.
На рис. 19.4 отрицание высказывания "Нет бензина в баке" существует в среде, в которой сделано допущение "Избыток топлива в карбюраторе", причем в модели имеется обоснование, которое гласит примерно следующее:
"Если в карбюраторе имеется избыток топлива, то бензин не может отсутствовать в баке".
Теперь интересующее нас высказывание будет "по наследству" истинно и в несовместимом контексте, но такая среда не представляет интереса для этого высказывания и, следовательно, в список ярлыка не включается.
Предположим также, что в модели имеется обоснование
"Если свечи влажные, то бензин не может отсутствовать в баке".
В этом случае отрицание высказывания "Нет бензина в баке" имеет место в среде, в которой сделано допущение "Влажные свечи", как показано на рис. 19.5. Эту среду уже имеет смысл включить в список ярлыка. Теперь ярлык интересующего нас высказывания будет содержать список, в котором перечислены два варианты среды, причем каждый из вариантов не содержит противоречий. На рисунке эти варианты среды заштрихованы. Как и ранее, варианты, представляющие несовместимый контекст (на рисунке они выделены прямоугольниками с утолщенными линиями контура), мы будем игнорировать.

Рис. 19.5. Решетка сред, в которой узлы, имеющие непустые списки ярлыков, заштрихованы
Очевидно, что высказывание также будет иметь место и в комбинированной среде, которая образуется совмещением обоих допущений, или в любой другой комбинированной среде, образованной в результате добавления к исходным каких-либо других допущений. Однако вряд ли имеет смысл фиксировать этот факт в списке ярлыка. В этот список желательно включать только те варианты среды, которые характеризуются минимальным множеством допущений, необходимых для истинности высказывания.
Таким образом, из всего сказанного выше вытекает, что основная забота системы отслеживания истинности предположений, основанной, на анализе допущений, состоит в формировании списка сред для узлов высказываний.
Отслеживание зависимостей
В главе 15 рассказывалось о том, что в экспертной системе VT для фиксации зависимостей между решениями, принимаемыми в процессе проектирования, используется сеть зависимостей. В такой сети узлы соответствуют присвоению значений конструктивным параметрам, причем между узлами существуют два вида связей— связи содействия (contributes-to) и связи принуждения (constrains). Узел А содействует узлу В, если значение параметра А появляется в результате вычисления значения В, а узел А принуждает узел В, если значение параметра A запрещает параметру В принимать определенные значения. В дальнейшем для некоторой формализации изложения будем обозначать узлы прописными буквами, а строчными— значения соответствующих параметров. Например, значение, присваиваемое узлу (параметру) А в какой-либо момент времени, будем обозначать как а.
Пересмотр допущений
Практически во всех программах экспертных систем в процессе решения проблемы обязательно тем или иным образом обновляются представления реального мира вещей, с которыми эта программа имеет дело (например, так происходит в программе планирования поведения роботов STRIPS, которую мы рассматривали в главе 3). В программах с разным уровнем "интеллектуальности" для пересмотра допущений в этом представлении применяются более или менее сложные методы. В литературе можно найти такую классификацию этих методов.
(1) Монотонный пересмотр (monotonic revision). Это самый простой метод, при котором программа принимает информацию о новых фактах и вычисляет, как эти факты могут повлиять на имеющееся представление, чтобы оно перешло в результате в состояние релаксации. При этом предполагается учитывать "важные" последствия, хотя определить, какие последствия важные, а какие не очень, зависит от уровня интеллектуальности программы. Например, к важным скорее будет отнесен вывод q из р и (р
(2) Немонотонный пересмотр (nonmonotonic revision). Иногда бывает желательно "взять назад" принятые ранее допущения и урезать сделанные на их основе заключения. Если я вижу вас за рулем "Мерседеса", то первое предположение — что он ваш собственный, а следовательно, вы, мягко говоря, человек не бедный. Но если через некоторое время я узнаю, что вы его, пользуясь терминологией Гека Финна, "позаимствовали", то я должен буду отбросить не только предположение, что он ваш собственный, но и предположение о вашем богатстве.
(3) Немонотонное обоснование (nonmonotonic justification). Дальнейшее усложнение метода происходит в тех программах, в которых определенные предположения полагаются истинными в том случае, когда нет никаких явных свидетельств против такого предположения.
Например, программа может предполагать, что все студенты малообеспечены. Отказ от такого предположения в отношении определенного студента выполняется в программе только в том случае, если на лицо явные признаки более чем среднего материального благополучия. Здесь именно отсутствие информации, противоречащей первоначальному допущению, а не наличие подтверждающей информации является обоснованием его правдоподобия.
(4) Гипотетическое суждение (hypothetical reasoning). В программе можно сначала принять во внимание определенные предположения, а затем посмотреть, что из них следует. Далее из этих предположений можно отобрать правдоподобные допущения. Таким образом, в этом способе предполагается формировать рассуждения в разных мирах, т.е. в таких состояниях представления о реальной области знаний, которые могут соответствовать или не соответствовать реальности. Отслеживание множества теорий такого вида требует определенных дополнительных ресурсов по сравнению с методами, предполагающими исследование единственной теории.
Методы первой из перечисленных категорий довольно тривиальны: нужно добавить в имеющуюся теорию новую информацию и некоторые дополнительные факты, которые необходимы, чтобы перевести новую теорию в состояние релаксации по отношению к имеющимся ограничениям. Простой метод, демонстрирующий реализацию второй из перечисленных категорий, мы рассмотрим в следующем разделе, а в разделах 19.3 и 19.4 рассмотрим методы третьей и четвертой категорий.
19.1. Запись информации о связях
Программой на языке CLIPS несложно проиллюстрировать простую процедуру записи зависимостей между данными в продукционной системе с прямой цепочкой вывода. Если в рабочей памяти имеются только два типа выражений — выражения импликации типа "Р имплицирует Q" и атомы, такие как "Р" и "Q", — то можно зафиксировать зависимости между элементами рабочей памяти в виде извлеченных из них характеристик влияния. Объекты литералов имеют поля support, в которых записывается, какие выражения используются для вывода этих литералов.
Может оказаться так, что некоторые литералы не имеют соответствующих выражений, поскольку представляют собой предположения, формируемые при инициализации рабочей памяти на основе конструкций def facts. В поле support таких литералов устанавливается значение -1. И литералы, и выражения импликации имеют нумерованные идентификаторы, которые позволяют отслеживать их состояние посредством специальных списков.
;; ШАБЛОНЫ
;; Литерал - атомарное высказывание,
(deftemplate literal (field id (type INTEGER))
(field atom (type SYMBOL))
(multifield support (type INTEGER) (default -1))
| )
Условие является импликацией в форме
;; "Р имплицирует Q", где "P" является левой частью правила
;; (left-hand side = Ihs),
;; "Q" - правой частью
;; (right-hand side = rhs).
(deftemplate conditional
(field Id (type INTEGER))
(multifield Ihs (type SYMBOL))
(multifield rhs (type SYMBOL)) )
;; Нам понадобится индекс в рабочей памяти, чтобы
;; можно было присваивать идентификаторы новым
;; производным высказываниям, (deftemplate index
(field no (type INTEGER)) )
;; Исходная модель мира. (deffacts model
(conditional (id 0) (Ihs P) (rhs Q);
(literal (id 1) (atom P)) )
;; ПРАВИЛА
;; Присвоить значение индекса очередному идентификатору,
(defrule init
?F <- (initial-fact)
(literal (id ?N))
(not (literal (id ?M&:{> ?M ?N)))) =>
(assert (index (no (+ ?N 1))))
(retract ?F) )
;; Применить правило modus ponens, чтобы можно было
;; вывести "Q" из "Р" и "Р имплицирует Q", формируя
;; указатели на "Р" и "Р имплицирует Q" в попе
;; support литерала "Q". (defrule mp ?I <- (index (no ?N))
(conditional (id ?C) (Ihs $?X) (rhs $?Y)) (literal (id ?A)
(atom $?X)) (not (literal (atom $?Y)))
(assert (literal (id ?N) (atom $?Y) (support ?C ?A)))
(modify ?I (no (+ ?N 1)))
Эта примитивная программа имеет дело только с условными выражениями и атомами. Например, нельзя, используя правило modus fallens (см.главу 8), вывести "не Р" из "Р имплицирует Q" и "не Q".
Пересмотр теорий высказываний
Систему отслеживания истинности предположений, разработанную Мак-Аллестером [McAllester, 1980], нельзя отнести к самым первым, но ее, пожалуй, лучше всего использовать в качестве наглядного пособия. Использованный им метод пересмотра предполагает наличие в системе базы данных утверждений, в которой пользователь может квалифицировать формулы как "истинные", "ложные" или "неопределенные". Таким образом, в основе метода лежит трехзначная логика, в отличие от классической двузначной, которую мы рассматривали в главе 8. Система представляет утверждения в виде узлов, которые хранят соответствующие значения.
Ограничения, которые накладывает на содержимое базы данных утверждений система отслеживания истинности, представляют собой фундаментальные аксиомы логики высказываний. Например, аксиома
¬(U^¬U)
утверждает, что высказывание U может быть одновременно и истинным, и ложным. (Учтите, что -U является метапеременной, которая представляет любое высказывание.) Система отслеживания истинности предположений, разработанная Мак-Аллестером, как и большинство других подобных систем, имеет дело только с формулами, которые не содержат кванторов. Например, в теорию может входить высказывание DEAD(fred), но не может входить (любой X)(DEAD(X)). Это ограничение существует по той простой причине, что не всегда возможно установить совместимость теории первого порядка, как это отмечалось в главе 8.
Система отслеживания истинности выполняет по отношению к базе данных четыре функции.
(1) Реализует множество дедукций высказываний, которые Мак-Аллестер назвал распространением пропозициональных принуждений (propositional constraint propagation).
(2) Формирует обоснования при присвоении высказываниям значений истинности, когда такое присвоение выполняется в результате распространения принуждений (а не при установке значения пользователем). Таким образом, если мы приходим к заключению, что q истинно, поскольку истинны p и (p
(3) Обновляет базу данных утверждений, как только какое-либо высказывание удаляется. Так, если мы приходим к выводу, что q истинно, поскольку истинны р и (p
(4) Отслеживает цепочку предположений, которые привели к противоречию, с помощью метода, получившего наименование обратное прослеживание, ведомое зависимостями (dependency-directed backtracking). После этого пользователю предлагается удалить одно из предположений, "виновных" в появлении противоречия.
Задавшись предположениями р и (— p v q) и пользуясь механизмом распространения принуждений, система отслеживания истинности может получить q. Затем она формирует поддерживающую структуру, представленную на рис. 19.2. Каждый узел в этой сети представляет собой фрейм (см. о фреймах в главе 6) с набором слотов, один из которых хранит наименование узла, другой — значение истинности, а третий — указатель на обоснование. Обоснование представлено другим фреймом, который содержит таблицу поддерживающих высказываний и их значения истинности. В структуре на рис. 19.2 истинность узла q подтверждается тем фактом, что узлы, представляющие р и (— p v g), отмечены как имеющие значения "истина". Обратите внимание на то, что узлы, представляющие предположения, как, например, р, не имеют указателей на фреймы обоснования, поскольку они полагаются истинными по определению.
Если в дальнейшем окажется, что значение q несовместимо с содержимым остальной базы данных утверждений, то, анализируя описанную структуру данных, можно будет выйти на фреймы обоснования. После этого пользователю будет предоставлена возможность проследить цепочку зависимостей, связанную либо с р, либо с (-p v q). Для выполнения такого отслеживания очень важно, чтобы структуры поддержки были убедительными.Убедительность структуры означает отсутствие зацикливания, т.е. отсутствие такой ситуации, когда некоторое высказывание не подтверждает через "посредников" само себя.
Обратите внимание — все утверждения являются либо предположениями, введенными пользователем, либо обосновываются наличием других утверждений. В следующем разделе мы рассмотрим другую, более сложную систему отслеживания истинности предположений, в которой допускается использовать в качестве обоснования отсутствие запрещающей информации.
Рис. 19.2. Структура представления связей между высказываниями
Работсо множеством контекстов
Те системы отслеживания истинности предположений, которые мы рассматривали в предыдущих разделах, работали с единственной непротиворечивой моделью мира. Однако иногда возникает необходимость строить логический вывод в контексте разных моделей гипотетических миров, которые могут совпадать, а могут и не совпадать с реальностью (см. главу 17). Например, при решении задачи диагностирования часто бывает полезно предположить, что возникла какая-то ошибка, и выдвинуть предположение на основе какого-нибудь допущения, а затем посмотреть, не подтверждается ли оно имеющимися фактами. Особенно уместна такая стратегия в ситуации, когда результаты наблюдений дают пищу для множества конкурирующих гипотез и скорее всего потребуется какая-либо комбинация гипотез, чтобы объяснить всю совокупность наблюдений. Другая область применения, в которой потребуется рассмотреть несколько вариантов модели мира, — проектирование. Вот тут-то уж точно потребуется несколько гипотетических "миров", чтобы представить разные варианты конструкции, удовлетворяющей заданным ограничениям.
Рекомендуемая литература
Сети зависимостей рассматриваются в работе [Charniak et al., 1987]. Статьи [De Kleer, 1986] и [Doyle, 1979] довольно сложные для неподготовленного читателя, а потому я бы посоветовал начинать углубленное изучение этой темы с работы [Forbus and De Kleer, 1993]. В этой же книге вы найдете и листинги множества программ, которые демонстрируют использование описанных в ней методов. Читатели, интересующиеся теоретическим обоснованием методов отслеживания истинности предположений, могут найти много интересного для себя в книге [Ginsberg, 1987] и сборнике статей [Martins and Reinfrank, 1991].
Релаксация в сети
Основное назначение связей в сети зависимостей состоит в том, чтобы, во-первых, показать, как изменение значения какого-либо параметра распространяется от узла к узлу, а во-вторых, выявить противоречия между значениями, присвоенными разным узлам.
Пусть, например, в сети имеются узлы А и М. Узел А представляет ускорение некоторой детали механизма, а М— массу этой детали. Оба узла, А и М, содействуют узлу F, который представляет силу, действующую на деталь. Более того, учитывая знакомую всем со школьной скамьи формулу f= та, узлы А и М также и принуждают узел F, поскольку если а и т известны, то значение f определяется этой формулой и не может быть произвольным, т.е. если а - 2 и от = 3, то мы можем присвоить узлу F только значение f= 6. Если же этому узлу уже ранее было присвоено значение f= 7, то сеть переходит в состояние противоречия.
Формула f= та играет роль принудительного ограничения для сети, описанной в этом примере. Если все ограничения в сети удовлетворяются, то она пребывает в состоянии релаксации. Рассмотрим варианты сетей, представленные на рис. 19.1. Сеть а) находится в промежуточном состоянии, поскольку узлу F не присвоено какого-либо определенного значения, сеть б) находится в состоянии релаксации, а сеть в) — в состоянии противоречия.
Строго говоря, термин "релаксация" относится к сети, а не к теории13. Но сеть есть не что иное, как только представление определенной теории, например сеть а) является представлением теории
f= mа
т=3
а = 2,
в которой формула f= та играет роль принудительного ограничения. Сеть б) представляет теорию
f= mа
т=3
а = 2
f=6,
которая находится в состоянии релаксации по отношению к ограничению f= та, а сеть в) представляет противоречивую теорию
f= mа
т=-3
а = 2
f=7.
По ходу изложения, не оговаривая отдельно, мы будем "перескакивать" от сетей к теориям, а для простоты использовать термин "представление", если нежелательно подчеркивать различие между этими двумя способами-реализации фактов и ограничений.

а

б

с
Рис. 19.1. Сети зависимостей с принудительными ограничениями. Окружностями представлены узлы сети, а прямоугольниками — связи
Системотслеживания истинности предположений
19.1. Отслеживание зависимостей
19.2. Пересмотр теорий высказываний
19.3. Немонотонное обоснование
19.4. Работа со множеством контекстов
19.5. Сравнение различных вариантов организации систем отслеживания истинности предположений
Рекомендуемая литература
Упражнения
Во всех экспертных системах мы тем или иным образом стремимся представить модель окружающего нас мира или, по крайней мере, какой-либо предметной области этого мира. Думаю, не следует тратить время на доказательство того очевидного факта, что программе нельзя позволять выполнять произвольные манипуляции над представлением мира, которое в ней имеется. Как правило, предположения в таком представлении влияют друг на друга, и существуют ограничения, которым должно удовлетворять любое множество предположений. Если такое влияние и ограничения игнорировать, то могут возникнуть серьезные расхождения между представлением мира в программе и реальностью. Системы, располагающие механизмом отслеживания зависимостей между предположениями и выявления их несовместимости, получили название систем отслеживания истинности предположений (truth maintenance systems). В литературе можно встретить и аналогичный по смыслу термин система отслеживания причинности (reason maintenance systems).
В этой главе мы в общих чертах представим вычислительные методы, которые используются для отслеживания зависимостей между представлением в программе состояний, действий и предположений. Начнем мы с относительно простых систем, затем перейдем к более сложным. Там, где без этого можно обойтись, мы будем пренебрегать строгими математическими формулировками и заменять их менее формальным описанием того, что делается в системе, почему делается именно так и какую пользу из этого можно извлечь.
Сравнение различных вариантов организации систем отслеживания истинности предположений
Функции компонента отслеживания истинности предположений в контексте более общей программы поиска решения проблемы можно сформулировать следующим образом:
кэшировать логический вывод, выполненный решателем проблем, чтобы однажды сформулированное заключение не пришлось выводить повторно;
предоставить в распоряжение решателя проблем средства формирования конструктивных допущений и анализа полезности заключений, выведенных на основе таких допущений;
анализировать и устранять возможные противоречия в моделях среды.
Подходы к построению системы отслеживания истинности предположений, предлагаемые Дойлом и Мак-Аллестером, можно использовать для нахождения единственного решения проблемы, удовлетворяющего заданным ограничениям. Прекрасным примером использования этого подхода на практике является экспертная система VT, описанная в главе 15,
Если же необходимо отыскать несколько вариантов решения или все возможные решения, понадобится более сложный механизм отслеживания. Работа с единственным состоянием сети зависимостей не позволяет выполнять сравнение альтернативных вариантов решения проблемы. Например, при выполнении дифференциального диагностирования желательно сравнивать конкурирующие гипотезы, поскольку среди них может оказаться такая, которая позволит объяснить все наблюдаемые проявления.
Подход, предложенный Де Клером, ориентирован именно на отыскание всех вариантов решения, удовлетворяющих заданным ограничениям. Если среди всех возможных решений система должна будет выбрать "наилучшее" по какому-либо критерию, понадобится оснастить ее дополнительным механизм управления.
Как вы понимаете смысл термина
Упражнения
1. Как вы понимаете смысл термина "релаксация" по отношению к сетям зависимостей?
2. Поясните отличие между монотонным и немонотонным пересмотром.
3. Если ({},{¬^р}) является причиной для и ({},{->р}) — причиной для q, что произойдет с р и q, если добавить ¬р в базу данных немонотонной системы отслеживания истинности?
4. Если ({<?},{}) является причиной для р и ({},{q})— причиной для q, что произойдет с р и q, если добавить ¬^q в базу данных немонотонной системы отслеживания истинности?
5. Заполните значения истинности г в структуре поддержки системы Мак-Аллестера, представленной на рис. 19.7.

Рис. 19.7. Структура представления связей между высказываниями для упр. 5
6. Рассмотрите набор обоснования для системы отслеживания истинности предположений, основанной на анализе допущений:
р^ q
¬р^q
р^¬q
¬p^¬q
7. Положим, что существуют четыре возможных допущения, которые можно использовать по отдельности или в сочетании друг с другом: р, —р, q и —q. Какие варианты сред для этого множества обоснований при таких допущениях будут непротиворечивыми?
Алгоритм формирования дереврешений по обучающей выборке
Ниже будет описан алгоритм формирования дерева решений по обучающей выборке, использованный в системе IDЗ. Задача, которую решает алгоритм, формулируется следующим образом. Задано:
множество целевых непересекающихся классов {С1, С2, ..., Сk};
обучающая выборка S, в которой содержатся объекты более чем одного класса.
Алгоритм использует последовательность тестовых процедур, с помощью которых множество 5 разделяется на подмножества, содержащие объекты только одного класса. Ключевой в алгоритме является процедура построения дерева решений, в котором нетерминальные узлы соответствуют тестовым процедурам, каждая из которых имеет дело с единственным атрибутом объектов из обучающей выборки. Как вы увидите ниже, весь фокус состоит в в выборе этих тестов.
Пусть Т представляет любую тестовую процедуру, имеющую дело с одним из атрибутов, а {О1,O2,...,On} — множество допустимых выходных значений такой процедуры
при ее применении к произвольному объекту х. Применение процедуры Т к объекту х будем обозначать как Т(х). Следовательно, процедура Т(х) разбивает множество S на составляющие {S1, S2, ..., Sn}, такие, что
Si= {x|T(x) = Oi}. Такое разделение графически представлено на рис. 20.3.
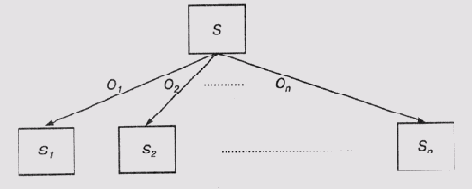
Рис. 20.3. Дерево разделения объектов обучающей выборки
Если рекурсивно заменять каждый узел Si, на рис. 20.3 поддеревом, то в результате будет построено дерево решений для обучающей выборки S. Как уже отмечалось выше, ключевым фактором в решении этой проблемы является выбор тестовой процедуры — для каждого поддерева нужно найти наиболее подходящий атрибут, по которому можно выполнять дальнейшее разделение объектов.
Квинлан (Quinlan) использует для этого заимствованное из теории информации понятие неопределенности. Неопределенность — это число, описывающее множество сообщений M= { m1, т2,..., тn}. Вероятность получения определенного сообщения mi из этого множества определим как р(тi). Объем информации, содержащейся в этом сообщении, будет в таком случае равен
I(mi) = -logp(mi).
Таким образом, объем информации в сообщении связан с вероятностью получения этого сообщения обратной монотонной зависимостью. Поскольку объем информации измеряется в битах, логарифм в этой формуле берется по основанию 2.
Неопределенность множества сообщений U(M) является взвешенной суммой количества информации в каждом отдельном сообщении, причем в качестве весовых коэффициентов используются вероятности получения соответствующих сообщений:
U(М) = -Sumip[(mi) logp(mi), i = 1,..., п.]
Интуитивно ясно, что чем большую неожиданность представляет получение определенного сообщения из числа возможных, тем более оно информативно. Если все сообщения в множестве равновероятны, энтропия множества сообщений достигает максимума.
Тот способ, который использует Квинлан, базируется на следующих предположениях.
Корректное дерево решения, сформированное по обучающей выборке S, будет разделять объекты в той же пропорции, в какой они представлены в этой обучающей выборке.
Для какого-либо объекта, который нужно классифицировать, тестирующую процедуру можно рассматривать как источник сообщений об этом объекте.
Пусть Ni — количество объектов в S, принадлежащих классу Сi. Тогда вероятность того, что произвольный объект с, "выдернутый" из S, принадлежит классу Сi, можно оценить по формуле
p(c~Ci) = Ni/|S|,
а количество информации, которое несет такое сообщение, равно I(с ~ Сi) = -1оg2р(mi) (с ~ Сi) бит.
Теперь рассмотрим энтропию множества целевых классов, считая их также множеством сообщений {С1 C2, ..., Ck}. Энтропия также может быть вычислена как взвешенная сумма количества информации в отдельных сообщениях, причем весовые коэффициенты можно определить, опираясь на "представительство" классов в обучающей выборке:
U(M) = -Sumi=1...,k[ р(с ~ Ci)x I(с ~ Сi)] бит.
Энтропия U(M) соответствует среднему количеству информации, которое необходимо для определения принадлежности произвольного объекта (с ~ S) какому-то классу до того, как выполнена хотя бы одна тестирующая процедура.
После того как соответствующая тестирующая процедура Т выполнит разделение S на подмножества {S1, S2, ..., Sn}, энтропия будет определяться соотношением
Uт(S) = -Sumi=1,...k(|S|/|Si|)х U(Si).
Полученная оценка говорит нам, сколько информации еще необходимо после того, как выполнено разделение. Оценка формируется как сумма неопределенностей сформированных подмножеств, взвешенная в пропорции размеров этих подмножеств.
Из этих рассуждений очевидно следует эвристика выбора очередного атрибута для тестирования, используемая в алгоритме, — нужно выбрать тот атрибут, который сулит наибольший прирост информации. Прирост информации GS(T) после выполнения процедуры тестирования Т по отношению к множеству 5 равен
GS(7)=U(S)-Uт(S).
Такую эвристику иногда называют "минимизацией энтропии", поскольку увеличивая прирост информации на каждом последующем тестировании, алгоритм тем самым уменьшает энтропию или меру беспорядка в множестве.
Вернемся теперь к нашему примеру с погодой и посмотрим, как эти формулы интерпретируются в самом простом случае, когда множество целевых классов включает всего два элемента. Пусть р — это количество объектов класса П в множестве обучающей выборки S, а п — количество объектов класса Н в этом же множестве. Таким образом, произвольный объект принадлежит к классу П с вероятностью p / (p + п), а к классу Н с вероятностью n /(p + п). Ожидаемое количество информации в множестве сообщений М = {П, Н} равно
U(M) = -p / (p + п) log2(p/(p + n )) -
n / (p + n) 1оg2(n/(р + п))
Пусть тестирующая процедура Т, как и ранее, разделяет множество S на подмножества {S1, S2.....Sn}, и предположим, что каждый компонент S, содержит pi, объектов класса
П и и, объектов класса Н. Тогда энтропия каждого подмножества Si будет равна
U(Si) = -рi/(рi + ni) log2(pi/(pi + ni)) -
n/(рi + ni) log2(ni/(pi +ni))
Ожидаемое количество информации в той части дерева, которая включает корневой узел, можно представить в виде взвешенной суммы:
Uт(S) = -Sumi=1,...n((pi, + ni)/(р + n)) х U(Si) Отношение (р, + п,)/(р + п) соответствует весу каждой i-и ветви дерева, вроде того, которое показано на рис. 20.3.
Это отношение показывает, какая часть всех объектов S принадлежит подмножеству S,.
Ниже мы покажем, что в последней версии этого алгоритма, использованной в системе С4.5, Квинлан выбрал слегка отличающуюся эвристику. Использование меры прироста информации в том виде, в котором она определена чуть выше, приводит к тому, что предпочтение отдается тестирующим процедурам, имеющим наибольшее количество выходных значений {O1 O2,..., Оп}.
Но несмотря на эту "загвоздку", описанный алгоритм успешно применялся при обработке достаточно внушительных обучающих выборок (см., например, [Quintan, 1983]). Сложность алгоритма зависит в основном от сложности процедуры выбора очередного теста для дальнейшего разделения обучающей выборки на все более мелкие подмножества, а последняя линейно зависит от произведения количества объектов в обучающей выборке на количество атрибутов, использованное для их представления. Кроме того, система может работать с зашумленными и неполными данными, хотя этот вопрос в данной книге мы и не рассматривали (читателей, интересующихся этим вопросом, я отсылаю к работе [Quinlan, 1986, b]).
Простота и эффективность описанного алгоритма позволяет рассматривать его в качестве достойного соперника существующим процедурам извлечения знаний у экспертов в тех применениях, где возможно сформировать репрезентативную обучающую выборку. Но, в отличие от методики, использующей пространства версий, такой метод не может быть использован инкрементально, т.е. нельзя "дообучить" систему, представив ей новую обучающую выборку, без повторения обработки ранее просмотренных выборок.
Рассмотренный алгоритм также не гарантирует, что сформированное дерево решений будет самым простым из возможных, поскольку использованная оценочная функция, базирующаяся на выводах теории информации, является только эвристикой. Но многочисленные эксперименты, проведенные с этим алгоритмом, показали, что формируемые им деревья решений довольно просты и позволяют прекрасно справиться с классификацией объектов, ранее неизвестных системе.
Продолжение поиска "наилучшего решения" приведет к усложнению алгоритма, а как уже отмечалось в главе 14, для многих сложных проблем вполне достаточно найти не лучшее, а удовлетворительное решение.
В состав программного комплекса С4.5, в котором используется описанный выше алгоритм, включен модуль C4.5Rules, формирующий из дерева решений набор порождающих правил. В этом модуле применяется эвристика отсечения, с помощью которой дерево решений упрощается. При этом, во-первых, формируемые правила становятся более понятными, а значит, упрощается сопровождение экспертной системы, а во-вторых, они меньше зависят от использованной обучающей выборки. Как уже упоминалось, в С4.5 также несколько модифицирован критерий отбора тестирующих процедур по сравнению с оригинальным алгоритмом, использованным в ID3.
Недостатком эвристики, основанной на приросте количества информации, является то, что она отдает предпочтение процедурам с наибольшим количеством выходных значений {О1, O2, ..., Оn}. Возьмем, например, крайний случай, когда практически бесполезные тесты будут разделять исходную обучающую выборку на множество классов с единственным представителем в каждом. Это произойдет, если обучающую выборку с медицинскими данными пациентов классифицировать по именам пациентов. Для описанной эвристики именно такой вариант получит преимущество перед прочими, поскольку UT(S) будет равно нулю и, следовательно, разность Gs(T) = U(S) - UT(S) достигнет максимального значения.
Для заданной тестирующей процедуры Т на множестве данных S, которая характеризуется приростом количества информации GS{T), мы теперь возьмем в качестве критерия отбора относительный прирост НS(Т), который определяется соотношением
НS{Т) = GS(Т)/V(S),
где
V(S) = -Sumi=1,..., (|S|/|Si|) x log2(|S|/|Si|).
Важно разобраться, в чем состоит отличие величины V(S) от U(S). Величина V(S) определяется множеством сообщений {О1, О2,...,Оn] или, что то же самое, множеством подмножеств {S1 S2,...,Sn}, ассоциированных с выходными значениями тестовой процедуры, а не с множеством классов {С1 C2,...,Ck}.
Таким образом, при вычислении величины V(S) принимается во внимание множество выходных значений теста, а не множество классов.
Новая эвристика состоит в том, что выбирается та тестирующая процедура, которая максимизирует определенную выше величину относительного прироста количества информации. Теперь те пустые тесты, о которых мы говорили чуть выше и которым прежний алгоритм отдал бы преимущество, окажутся в самом "хвосте", поскольку для них знаменатель будет равен log2(N), где N— количество элементов в обучающей выборке.
Оригинальный алгоритм формирования дерева страдает еще одной "хворью" - он часто формирует сложное дерево, в котором фиксируются несущественные для задачи классификации отличия в элементах обучающей выборки. Один из способов справиться с этой проблемой — использовать правило "останова", которое прекращало бы процесс дальнейшего разделения ветвей дерева при выполнении определенного условия. Но оказалось, что сформулировать это условие не менее сложно, а потому Квинлан пошел по другому пути. Он решил "обрезать" дерево решений после того, как оно будет сформировано алгоритмом. Можно показать, что такое "обрезание" может привести к тому, что новое дерево будет обрабатывать обучающую выборку с ошибками, но с новыми данными оно обычно справляется лучше, чем полное дерево. Проблема "обрезания" довольно сложна и выходит за рамки данной книги. Читателям, которые заинтересуются ею, я рекомендую познакомиться с работами [Mingers, 1989, b] и [Mitchell, 1997], а подробное описание реализации этого процесса в С4.5 можно найти в [Quinlan, 1993, Chapter 4].
Для того чтобы сделать более понятным результат выполнения алгоритма, в системе С4.5 дерево решений преобразуется в набор порождающих правил. Мы уже ранее демонстрировали соответствие между отдельным путем на графе решений от корня к листу и порождающим правилом. Условия в правиле — это просто тестовые процедуры, выполняемые в промежуточных узлах дерева, а заключение правила — отнесение объекта к определенному классу.
Однако строить набор правил перечислением всех возможных путей на графе — процесс весьма неэффективный. Некоторые тесты могут служить просто для того, чтобы разделить дерево и таким образом сузить пространство выбора до подмножества, которое в дальнейшем уточняется с помощью проверки других, более информативных атрибутов. Это происходит по той причине, что не все атрибуты имеют отношение ко всем классам объектов.
Квинлан применил следующую стратегию формирования множества правил из дерева решений.
(1) Сформировать начальный вариант множества правил, перечислив все пути от корня дерева к листьям.
(2) Обобщить правила и при этом удалить из них те условия, которые представляются излишними.
(3) Сгруппировать правила в подмножества в соответствии с тем, к каким классам они имеют отношение, а затем удалить из каждого подмножества те правила, которые не вносят ничего нового в определение соответствующего класса.
(4) Упорядочить множества правил по классам и выбрать класс, который будет являться классом по умолчанию.
Упорядочение правил, которое выполняется на шаге (4), можно рассматривать как примитивную форму механизма разрешения конфликтов (см. главу 5). Порядок классов внутри определенного подмножества теперь уже не будет иметь значения. Назначение класса по умолчанию можно считать своего рода правилом по умолчанию, которое действует в том случае, когда не подходит ни одно другое правило.
Полученное в результате множество правил скорее всего не будет точно соответствовать исходному дереву решений, но разобраться в них будет значительно проще, чем в логике дерева решений. При необходимости эти правила можно будет затем уточнить вручную.
Квинлан очень осторожно подошел к формулировке тех условий, при которых созданная им система С4.5 может быть использована как подходящий инструмент обучения, позволяющий ожидать удовлетворительных результатов. Подход, основанный на использовании дерева решений, можно применять для решения далеко не всех задач классификации.
Определенные ограничения свойственны и тем конкретным алгоритмам, которые использованы в системе С4.5. Необходимым условием успешного применения этой системы является выполнение следующих требований.
Перечень классов, с которыми в дальнейшем будет оперировать экспертная система, необходимо сформулировать заранее. Другими словами, алгоритмы, положенные в основу функционирования системы С4.5, не способны формировать перечень классов на основе группировки обучающей последовательности объектов. Кроме того, классы должны быть четко очерченными, а не "расплывчатыми" — некоторый объект либо принадлежит к данному классу, либо нет, никаких промежуточных состояний быть не может. И, кроме того, классы не должны перекрываться.
Применяемые в системе методы обучения требуют использовать обучающие выборки большого объема. Чем больше объем выборки, тем лучше. При малой длине обучающей выборки на полученных в результате правилах будут сказываться индивидуальные особенности экземпляров в обучающей выборке, что может привести к неверной классификации незнакомых объектов. Методы "усечения" дерева решений, использованные в С4.5, будут работать некорректно, если длина обучающей выборки слишком мала и содержит нетипичные объекты классов.
4 Данные в обучающей выборке должны быть представлены в формате "атрибут-значение", т.е. каждый объект должен быть охарактеризован в терминах фиксированного набора атрибутов и их значений для данного объекта. Существуют методы обработки, которые позволяют справиться и с пропущенными атрибутами, — предполагается, что в таких случаях выход соответствующей тестирующей процедуры будет в вероятностном смысле распределен по закону, определенному на основе тех объектов, в которых такой атрибут определен.
В тех областях применения, в которых можно использовать и подход, базирующийся на дереве решений, и обычные статистические методы, выбор первого дает определенные преимущества. Этот подход не требует знания никаких априорных статистических характеристик классифицируемого множества объектов, в частности функций распределения значений отдельных атрибутов (использование статистических методов зачастую основано на предположении о существовании нормального распределения значений атрибутов).Как показали эксперименты с экспертными системами классификации разных типов, те из них, в которых используются деревья решений, выигрывают по сравнению с другими по таким показателям, как точность классификации, устойчивость к возмущениям и скорость вычислений.
Алгоритм отсеивания кандидатов
Пространство версий, как следует из приведенного описания, есть не что иное, как структура данных для представления множества описаний концептов. Однако термин "пространство версий" часто применяется и по отношению к технологии обучения, использующей при работе с этой структурой данных алгоритм, известный как алгоритм отсеивания кандидатов (candidate elimination). Этот алгоритм манипулирует с граничными множествами, представляющими определенное пространство версий.
Выполнение алгоритма начинается с инициализации пространства версий — заполнения его множеством всех описаний концептов, совместимых с первым позитивным экземпляром в обучающей выборке. Другими словами, множество максимально специфических образцов (S) заполняется наиболее специфическими описаниями концептов, которые способен сформировать язык образцов, а множество максимально обобщенных образцов (G) заполняется наиболее обобщенными описаниями концептов. При анализе каждого последующего экземпляра в обучающей выборке множества S и G модифицируются таким образом, чтобы отсеять из пространства версий те описания концептов, которые несовместимы с анализируемым экземпляром.
Таким образом, в процессе обучения границы монотонно "движутся" навстречу друг другу. Перемещение границы S в направлении большей общности можно рассматривать как выполнение поиска в ширину от специфических образцов к более общим. Цель поиска — сформировать новое граничное множество, которое будет обладать минимально достаточной общностью, чтобы "охватить" новый позитивный экземпляр обучающей выборки. Другими словами, граница 5 перемещается в том случае, если новый позитивный экземпляр в обучающей выборке не сопоставим ни с одним из образцов в множестве S. Точно так же и перемещение границы G в направлении большей специфичности можно рассматривать как поиск в ширину от более общих образцов к более специфичным. Цель такого поиска— сформировать новое граничное множество, которое будет обладать минимально достаточной спецификой, чтобы не "накрыть" очередной негативный экземпляр в обучающей выборке.
Коррекция границы G происходит в том случае, когда программа обнаруживает, что очередной негативный экземпляр сопоставим с каким-либо образцом в G.
В этом алгоритме нет никакой эвристики, поскольку ограничения четкие и тем самым гарантируется сходимость алгоритма. Монотонность поиска оказалась тем "золотым ключиком", с помощью которого удалось решить проблему комбинаторики обновления пространств.
Технология пространства версий обладает множеством привлекательных свойств, которые стоят того, чтобы их здесь перечислить.
Гарантируется совместимость всех описаний концептов со всеми экземплярами в обучающей выборке.
Пространство поиска суммирует альтернативные интерпретации наблюдений.
Результат не зависит от порядка обработки обучающей выборки.
Каждый экземпляр в обучающей выборке анализируется только один раз.
Не возникает необходимость возвращаться к однажды отвергнутой гипотезе.
Тот факт, что пространство версий суммирует данные, означает, что его можно использовать в качестве базиса для формирования новых экземпляров для обучающей выборки, т.е. экземпляров, которые могли бы еще более сблизить границы. То, что программа анализирует каждый экземпляр только один раз, позволяет обойтись без сохранения ранее обработанных экземпляров. Следовательно, и время обучения пропорционально объему обучающей выборки, а не связано с количеством экземпляров в ней какой-либо показательной функцией. Поскольку отпадает необходимость в обратном прослеживании, эффективность процедуры должна быть довольно высокой. Наиболее серьезным "подводным камнем" в этой технологии является фактор ветвления в процессе частичного упорядочения образцов, который имеет тенденцию к комбинаторному росту по мере увеличения количества дизъюнктов в описаниях концептов.
Формирование и уточнение правил
Программа Meta-DENDRAL формирует на основе рассуждений правила, которые затем используются программой DENDRAL в процессе определения молекулярной структуры неизвестного органического соединения. В первой версии программы Meta-DENDRAL гипотетические правила (гипотезы о правилах) формировались в процессе эвристического поиска, подобного тому, который использовался в самой программе DENDRAL. Другими словами, для формирования правил в этой версии использовалась та же стратегия, что и в системе, применяющей эти правила.
Роль программы Meta-DENDRAL во всем комплексе состояла в хом, чтобы помочь химику выявить взаимосвязи между вариантами фрагментации молекул в процессе получения массового спектра и структурными характеристиками компонентов молекулы. Работая совместно, программа и химик решают, какие данные о структуре компонентов представляют интерес, а затем отыскивают спектрометрический процесс, который может объяснить появление таких данных. В результате формируются правила, связывающие структуру с масс-спектрограммой. Затем программа тестирует эти правила и при необходимости модифицирует их так же, как это сделал бы химик.
Те правила масс-спектрометрии, которые химик использует для описания фрагментации молекулы, могут быть символически представлены в виде порождающих правил. Например, следующее правило расщепления позволяет представить в программе связь между определенной структурой молекулы и определенным процессом ее расщепления в процессе масс-спектрометрии. Здесь значком "-" представлена связь в молекуле, а значком "*" — место разрыва под воздействием бомбардировки электронами:
N-C-C-C-> N-C*C-C.
В левой части правила представлены характеристики структуры, а в правой — процесс расщепления при формировании массового спектра.
Для обучения Meta-DENDRAL используется набор молекул, структура и массовый спектр которых известны. Для этого набора молекул формируются пары "структура-спектр", которые и включаются в обучающую выборку.
Хочу обратить ваше внимание на следующее. Хотя "словарь" атомов в подграфах структуры молекулы и невелик, а "грамматика" конструирования подграфов проста, количество формируемых подграфов может быть довольно велико. Поэтому существует опасность экспоненциального взрыва. Учитывая потенциальную опасность экспоненциального взрыва, в Meta-DENDRAL (как, впрочем, и в DENDRAL) используется стратегия "планирование— формирование гипотез— проверка". Фаза планирования в Meta-DENDRAL выполняется программой INTSUM (сокращение от interpretation and summary — интерпретация и суммирование данных). Эта программа должна предложить набор простых процессов, которые можно включить в обучающую выборку. Процессы
Выходная информация программы INTSUM передается программе эвристического поиска RULEGEN, которая играет в Meta-DENDRAL, ту же роль, что и программа CONGEN в DENDRAL. Но в отличие от CONGEN, она формирует не гипотезы о структурах молекул, а более общие гипотетические правила расщепления, которые, например, могут предполагать и множественные разрывы связей в молекулах. Эти правила должны охватывать все случаи, представленные в обучающей выборке, сформированной программой INTSUM. После того как будет сформировано множество гипотетических правил, в дело вступает программа RULEMOD, на которую возложено выполнение последней фазы процесса, — фазы тестирования и модификации правил.
Разделение нагрузки между программами RULEGEN и RULEMOD следующее: программа RULEGEN выполняет сравнительно поверхностный поиск в пространстве правил и формирует при этом приблизительные и избыточные правила, а программа RULEMOD выполняет более глубокий поиск и уточняет набор гипотетических правил.
Алгоритм работы программы RULEMOD и по сей день представляет определенный интерес, хотя со времени ее создания прошло более 30 лет. Задачи, которые решает эта программа, типичны для всех программ тонкой настройки правил.
(1) Устранение избыточности. Данные, поступающие на вход программы (гипотетические правила), могут быть переопределены, т.е.
несколько правил, сформированных на предыдущем этапе, объясняют одни и те же факты. Обычно в окончательный набор правил нужно включить только часть из них. При выполнении этой задачи также удаляются правила, которые вносят противоречие во всю совокупность или порождают некорректные предсказания.
(2) Слияние правил. Иногда несколько правил, взятых в совокупности, объясняют сразу множество фактов, и эту совокупность имеет смысл объединить в одно, более общее правило, которое будет включать все позитивные свидетельства и не содержать ни одного негативного. Если удастся отыскать такое совокупное правило, то им заменяются в окончательном наборе все его исходные компоненты.
(3) Специализация правила. Иногда оказывается, что слишком общее правило порождает некорректные предсказания, т.е. в его "зону охвата" попадают и негативные свидетельства. В таком случае нужно попытаться добавить в правило уточняющие компоненты, которые помогут исключить из "зоны охвата" правила негативные свидетельства, но сохранят охват всех позитивных свидетельств. В результате правило станет более специализированным.
(4) Обобщение правила. Поскольку порождение правил выполняется на основе обучающей выборки ограниченного объема, то среди сформированных правил могут оказаться и такие, в которых специализация выходит за рамки разумного. Программа пытается сохранить только минимальный набор условий в левой части правила, необходимый для обеспечения корректности правила на данной тестовой выборке.
(5) Отбор правил в окончательный набор. После обобщения и специализации правил в наборе вся совокупность может снова стать избыточной. Поэтому программа снова повторяет процедуру устранения избыточности, описанную в п. 1.
Все описанные процедуры могут итеративно повторяться до тех пор, пока пользователь не будет удовлетворен сформированным набором правил. Единственное, что после этого еще остается сделать пользователю — присвоить правилам веса. Ниже в этой главе мы покажем, как на практике выполняется формирование набора правил.
Качество правил, сформированных системой Meta-DENDRAL, проверялось на наборе структур, не включенных в обучающую выборку. Они также сравнивались с теми правилами, которые имеются в опубликованных источниках, и анализировались опытными специалистами по спектрометрии органических соединений. Программа успешно "открыла" опубликованные правила и, более того, нашла новые. Способность сформированных правил предсказать вид спектра соединений, ранее ей неизвестных, поразила специалистов. Однако ни DENDRAL, ни Meta-DENDRAL не стали коммерческими программными продуктами, хотя многие идеи, рожденные в процессе работы над этим проектом, и нашли широкое применение в компьютерной химии. Различные модули этих программ были включены в состав других программных комплексов, в частности в системы управления базой данных химических соединений [Feigenbaum and Buchanan, 1993].
Формирование знаний носнове машинного обучения
20.1. Индуктивное обучение
20.2. Система Meta-DENDRAL
20.3. Построение дерева решений и порождающих правил
20.4. Уточнение наборов правил
Рекомендуемая литература
Упражнения
В главе 1 мы уже вскользь упоминали о связи между приобретением знаний экспертной системой и использованием автоматизированных методов формирования знаний на базе машинного обучения (machine learning). Было отмечено, что в ряду тех проблем, с которыми сталкивается разработчик экспертной системы, приобретение знаний является одной из наиболее трудоемких. В главе 10 было рассмотрено множество методов извлечения знаний, но ни один из них не позволяет избавиться от услуг человека-эксперта и соответственно от значительного объема работы, выполняемой "вручную".
Можно предложить три варианта приобретения знаний, которые позволят обойтись без создания базы знаний "вручную" объединенными усилиями человека-эксперта и инженера по знаниям.
(1) Использовать интерактивные программы, которые извлекали бы знания непосредственно у человека-эксперта в процессе диалога за терминалом. Различные варианты такого рода программ мы рассматривали в предыдущих главах. Вы могли убедиться, что такой вариант может успешно использоваться на практике в том случае, если диалоговая система обладает некоторым запасом базовых знаний об определенной предметной области.
(2) Использовать программы, способные обучаться, читая тексты, аналогично тому, как учится человек в процессе чтения технической литературы. Этот метод "упирается" в более общую проблему машинного распознавания смысла естественного языка человека. Поскольку сложность этой проблемы, пожалуй, на порядок выше, чем проблемы приобретения знаний о конкретной предметной области, вряд ли на таком пути мы быстро достигнем цели (по крайней мере, при современном уровне решения проблемы распознавания естественного языка).
(3) Использовать программы, которые способны обучаться под руководством человека-учителя. Один из подходов состоит в том, что учитель предъявляет программе примеры реализации некоторого концепта, а задача программы состоит в том, чтобы извлечь из предъявленных примеров набор атрибутов и значений, определяющих этот концепт.
Такой подход уже успешно опробован в ряде исследовательских систем, и использованные при этом базовые методы составляют предмет обсуждения данной главы.
За последние 10 лет в области исследования методов формирования знаний на основе машинного обучения (в дальнейшем для краткости мы будем употреблять термин машинное обучение — machine learning) наблюдается бурный прогресс. Но мы не будем в этой главе делать широкого, а следовательно, и поверхностного обзора имеющихся работ, а сконцентрируемся на тех методах, которые имеют прямое отношение к проблематике экспертных систем:
извлечение множества правил из предъявляемых примеров;
анализ важности отдельных правил;
оптимизация производительности набора правил.
Существуют и другие аспекты машинного обучения, которых мы здесь касаться не будем, поскольку пока что еще не видно, как они смогут повлиять на технологию экспертных систем (но нельзя исключать, что в будущем дело может радикально измениться). Читатели, которых заинтересуют такие аспекты, могут обратиться к работам, перечисленным в конце главы.
Индуктивное обучение
Точное определение термину "обучение" дать довольно трудно, но большинство авторов сходятся во мнении, что это — качество адаптивной системы, которая способна совершенствовать свое поведение (умение справляться с проблемами), накапливая опыт, например опыт решения аналогичных задач [Simon, 1983]. Таким образом, обучение — это одновременно и способность, и действие. Любая программа обучения должна обеспечивать возможность сохранять и анализировать полученный опыт решения проблем, а также обладать способностью применять сделанные выводы для решения новых проблем.
В работе [Carbonell et al, 1983] представлена классификация программ обучения на основе используемой стратегии. Попросту говоря, использованная стратегия зависит от того, насколько глубоко может программа проникнуть в суть той информации, которую она получает в процессе обучения.
На одном конце спектра находятся программы, которые обучаются, непосредственно воспринимая новые знания, и не выполняют при этом никакого логического анализа. Обычно такую методику обучения называют rote learning ("зубрежка", а программы соответственно — "зубрилками"). Аналогов такой методике в обычной жизни не счесть. Самый знакомый всем — зазубривание таблицы умножения (или "Отче наш..."). На другом конце спектра обучающих программ находятся те, которые пользуются методикой unsupervised learning, т.е. обучение без преподавателя. Под этим подразумевается способность формулировать теоремы, которая имеет очевидную аналогию с образом мышления человека, делающего научное открытие на основе эмпирических фактов.
В этой главе мы рассмотрим методики, лежащие посередине между этими двумя крайностями. Они получили наименование супервизорного обучения (supervised learning). Программам, использующим такую методику, демонстрируются ряд примеров. Программа должна проанализировать набор свойств этих примеров и идентифицировать подходящие концепты. Свойства примеров известны и представлены парами "атрибут-значение". "Надзор" за процессом обучения заключается, главным образом, в подборе репрезентативных примеров, т.е.
в формировании пространства атрибутов, над которым будет размышлять программа.
Наиболее общая форма задач, решаемых в такой системе обучения, получила наименовании индукции (induction). Таким образом, индуктивная программа обучения — это программа, способная к обучению на основе обобщения свойств предъявляемых ей примеров (экземпляров, образцов). В работе [Michalski, 1983, р. 83] дано такое определение процессу обучения:
"Эвристический поиск в пространстве символических описаний, сформированный применением различных правил вывода к исходным наблюдаемым проявлениям".
Символические описания представляют собой, как правило, обобщения, которые можно сделать на основе наблюдаемых проявлений. Такие обобщения являются формой логического заключения, т.е. они предполагают выполнение определенных, регламентируемых некоторыми правилами трансформаций символических описаний, которые представляют наблюдаемые проявления. Одна из форм индуктивного обучения предусматривает демонстрацию примеров двух типов — тех, которые соответствуют концепту (позитивные экземпляры), и тех, которые ему не соответствуют (негативные экземпляры). Задача программы обучения — выявить или сконструировать подходящий концепт, т.е. такой, который включал бы все позитивные экземпляры и не включал ни одного негативного. Такой тип обучения получил название обучение концептам (concept learning).
Рассмотрим набор данных, представленный в табл. 20.1.
Таблица 20.1. Обучающая выборка примеров
Экземпляр |
Страна-изготовитель |
Размер |
Старая модель |
Позитивный/ негативный |
||
Oldsmobile Cutlass |
США |
Большой |
Нет |
Негативный |
||
BMW 31 6 |
Германия |
Малый |
Нет |
Позитивный |
||
Thunderbird Raodster |
США |
Малый |
Да |
Негативный |
||
VW Cabriolet |
Германия |
Малый |
Нет |
Позитивный |
||
Rolls Royce Corniche |
Великобритания |
Большой |
Да |
Негативный |
||
Chevrolet Bel Air |
США |
Малый |
Да |
Негативный |
||
Тогда позитивными экземплярами для этого концепта будут BMW 316 и VW Cabriolet, а остальные— негативными. Если же целевой концепт— Американский автомобиль старой марки, то позитивными экземплярами будут Thunderbird Raodster и Chevrolet Bel Air, а остальные — негативными.
Очень существенно предъявлять программе и позитивные, и негативные экземпляры. В первой из рассмотренных выше задач и BMW 316, и VW Cabriolet являются малыми автомобилями, поэтому если программе не представить в качестве негативного экземпляра Chevrolet Bel Air, то она может сделать вывод, что концепт Немецкий автомобиль совпадает с концептом Малый автомобиль. Аналогично, если во второй задаче не будет представлен негативный экземпляр Oldsmobile Cutlass, то программа может посчитать концепт Американский автомобиль старой марки совпадающим с более общим концептом Американский автомобиль.
С формальной точки зрения любое множество данных, в котором выделены положительные и отрицательные экземпляры, можно считать обучающей выборкой для индуктивной программы обучения. В обучающей выборке также нужно специфицировать некоторый набор атрибутов, имеющих отношение к обучаемым концептам, а запись каждого экземпляра должна содержать значения этих атрибутов. В табл. 20.1 представлены значения атрибутов обучающей выборки для концепта Немецкий автомобиль.
Другая задача обучения получила наименование обобщение дескрипторов (descriptive generalization). Формулируется задача следующим образом: программе обучения предъявляется набор экземпляров некоторого класса объектов (т.е. представляющих некоторый концепт), а программа должна сформировать описание, которое позволит идентифицировать (распознавать) любые объекты этого класса. Пусть, например, обучающая выборка имеет вид
{Cadillac Seville, Oldsmobile Cutlass, Lincoln Continental},
причем каждый экземпляр выборки имеет атрибуты размер, уровень комфорта и расход топлива. Тогда в результате выполнения задачи обобщения дескрипторов программа сформирует описание, представляющее набор значений дескрипторов, характерный для данного класса объектов:
{большой, комфортабельный, прожорливый}.
Отличие между задачами обучение концептам и обобщение дескрипторов состоит в следующем:
задача обучения концептам предполагает включение в обучающую выборку как позитивных, так и негативных экземпляров некоторого заранее заданного набора концептов, а в процессе выполнения задачи будет сформировано правило, позволяющее затем программе распознавать ранее неизвестные экземпляры концепта;
задача обобщения дескрипторов предполагает включение в обучающую выборку только экземпляров определенного класса, а в процессе выполнения задачи создается наиболее компактный вариант описания из всех, которые подходят к каждому из предъявленных экземпляров.
Обе задачи относятся к классу методик, который мы назвали супервизорным обучением, поскольку в распоряжении программы имеется и специально подготовленная обучающая выборка, и пространство атрибутов.
В следующем разделе мы рассмотрим две программы обучения, которые разработаны в связи с созданием экспертной системы DENDRAL. Первый вариант реализации программы обучения нельзя отнести ни к одной из перечисленных выше категорий, но второй вариант использовал методику, которую мы сейчас можем отнести к категории "индуктивное обучение". В оригинальном описании программы авторы назвали ее version space (пространство версий). Постановка задачи очень напоминает обучение концептам, поскольку предусматривает включение в обучающую выборку позитивных и негативных экземпляров концепта.
Интересно сравнить оба варианта системы и выяснить, как знания, специфичные для определенной предметной области (в данном случае, химии), могут быть использованы алгоритмом обучения, независящим от предметной области.
В разделе 20.3 описана современная программа индуктивного обучения, на примере которой будет продемонстрировано, как формируются правила для экспертных систем. В разделе 20.4 мы затронем вопрос настройки отдельных правил и набора связанных правил.
Построение дереврешений и порождающих правил
Правила являются не единственно возможным способом представления информации о концептах в виде пар- "атрибут-значение" для целей классификации. Альтернативный метод структурирования такой информации — использование дерева решения. Существуют эффективные алгоритмы конструирования таких деревьев из исходных данных. Мы обсудим их в разделе 20.3.1.
За последние 30 лет создано довольно много систем обучения, в которых использована эта методика. Среди них системы CLS [Hunt et al., 1966], ID3 [Quinlan, 1979], ACLS [Paterson and Niblett, 1982], ASSISTANT [Kononenko et al., 1984] и IND [Buntine, 1990]. Система ACLS (развитие системы ID3) стала базовой для множества коммерческих экспертных систем, таких как Expert-Ease и RuleMaster, которые нашли широкое применение в промышленности. Несколько подробнее об алгоритме работы системы ID3 будет рассказано в разделе 20.3.2.
Программный комплекс С4.5 [Quinlan, 1993] использует алгоритмы ЮЗ и включает программу C4.5Rules. Этот модуль формирует порождающие правила, используя в качестве входной информации описание дерева решений. Подробное описание этой программы имеется в технической литературе, а потому мы не будем останавливаться на ней в данной книге. В последней версии этой системы, С5.0, реализована еще более тесная интеграция форматов представления деревьев решений и правил.
Пространство версий
В этом разделе мы рассмотрим одну из методик обучения, которая получила в литературе наименование пространство версий (version space) [Mitchell, 1978], [Mitchell, 1982], [Mitchell, 1997]. Эта методика была реализована во второй версии системы Meta-DENDRAL. При выводе общего правила масс-спектрометрии из набора примеров, демонстрирующих, как определенные молекулы расщепляются на фрагменты, в этой версии Meta-DENDRAL интенсивно используется механизм обучения концептам, о котором мы рассказывали выше. В работе [Mitchell, 1978] так формулируется проблема обучения концептам.
"Концепт можно представить как образец, который обладает свойствами, общими для всех экземпляров этого концепта. Задача состоит в том, чтобы при заданном языке описания образцов концептов и наличии обучающей выборки — наборе позитивных и негативных экземпляров целевого концепта и способе сопоставления данных из обучающей выборки и гипотез описания концепта — построить описание концепта, совместимого со всеми экземплярами в обучающей выборке".
В этом контексте "совместимость" означает, что сформированное описание должно охватывать все позитивные экземпляры и не охватывать ни один негативный экземпляр.
Для того чтобы "рассуждать" о правилах, касающихся масс-спектрометрии, система Meta-DENDRAL должна располагать языком представления концептов и отношений между ними в этой предметной области. В Meta-DENDRAL это объектно-ориентированный язык (см. главу 6), который описывает сеть с помощью узлов и связей между ними. Узлы представляют атомы в структуре молекулы, а связи — химические связи в молекуле. В этом языке некоторый экземпляр в обучающей выборке соответствует образцу в том случае, если сопоставимы все их узлы и связи и удовлетворяются все ограничения, специфицированные в описании образца.
В контексте проблемы обучения концептам пространство версий есть не что иное, как способ представления всех описаний концептов, совместимых в оговоренном выше смысле со всеми экземплярами в обучающей выборке.
Главное достоинство использованной Митчеллом (Mitchell) методики представления и обновления пространств версий состоит в том, что версии могут строиться последовательно одна за другой, не оглядываясь на ранее обработанные экземпляры или ранее отвергнутые гипотезы описаний концептов.
Митчелл отыскал ключ к решению проблемы эффективного представления и обновления пространств версий, заметив, что пространство поиска допустимых описаний концептов является избыточным. В частности, он пришел к выводу, что можно выполнить частичное упорядочение образцов, сформированных описаниями концептов. Самым важным является отношение "более специфичный чем или равный", которое формулируется следующим образом.
"Образец Р1 более специфичен или равен образцу Р2 (это записывается в форме Р2 =< Р2) тогда и только тогда, когда Р1 сопоставим с подмножеством всех образцов, с которыми сопоставим образец Р2".
Рассмотрим следующий простой пример из обучающей программы для "мира блоков" [Winston, 1975, а]. На рис. 20.1 образец Р1 более специфичен, чем образец Р2, поскольку ограничения, специфицированные в образце Р1, удовлетворяются только в том случае, если удовлетворяются более слабые ограничения, специфицированные в образце Р2. Можно посмотреть на эту пару образцов и с другой точки зрения: если в некотором экземпляре удовлетворяются ограничения, специфицированные в образце Р1, то обязательно удовлетворяются и условия, специфицированные в образце Р2, но не наоборот.

Рис. 20.1. Отношения между образцами
Обратите внимание на следующий нюанс. Для того чтобы программа смогла выполнить упорядочение представленных образцов, она должна быть способна разобраться в смысле множества понятий и отношений между ними, которые специфичны для данной предметной области.
Программа должна понимать, что если В — это "брусок", то, значит, В — это одновременно и "объект произвольной формы", т.е. в программу должны быть заложены определенные критерии, которые помогут ей выделить категории сущностей, представленных узлами в языке описания структуры образцов.
Программа должна знать, что если А "поддерживает" В, то, следовательно, А "касается" В в мире блоков, т.е. программа должна обладать способностью разобраться в избыточности отношений между объектами в предметной области.
Программа должна понимать логический смысл таких терминов, как "не", "любой" и "или", и то как они влияют на ограничения или разрешения в процессе сопоставления образцов.
Все эти знания необходимы программе для того, чтобы она смогла сопоставить образец Р1 с Р2, т.е. узлы и связи в одном образце с узлами и связями в другом, и выяснить, что любое ограничение, специфицированное в Р1, является более жестким, более специфичным, чем соответствующее ему ограничение в образце Р2. Если программа сможет во всем этом
разобраться, то открывается путь к представлению пространств версий в терминах большей "специфичности" или большей "общности" образцов в этом пространстве. Тогда программа может рассматривать некоторое пространство версий как содержащее:
множество максимально специфических образцов;
множество максимально обобщенных образцов;
все описания концептов, которые находятся между этими двумя крайними множествами.
Все это в совокупности называется представлением пространств версий граничными множествами (boundary sets). Такое представление, во-первых, компактно, а во-вторых, легко обновляется. Оно компактно, поскольку не хранит в явном виде все описания концептов в данном пространстве. Его легко обновлять, так как определение нового пространства можно выполнить перемещением одной или обеих границ.
Рекомендуемая литература
Рекомендуемая литература
Как отмечалось в самом начале этой главы, существует множество проблем, связанных с машинным обучением, о которых мы даже не упоминали в данной книге. Читателям, которые заинтересуются этой проблемой, я бы порекомендовал начинать знакомство с ней с обзоров [Michalski et al, 1983] и [Michalski et al., 1986] и работы [Winston, 1984, Chapter 11]. В этих статьях рассматриваются разнообразные виды машинного обучения, приложимые не только к экспертным системам.
Множество статей на эту тему публикуется в журнале Artificial Intelligence. В частности, я рекомендую познакомиться со статьями [Winston, 1982J и [Lenat, 1982]. Классификация программ обучения, основанная на анализе базовых алгоритмов, представлена в работе [Bundy et al., 1984]. Но учтите, что эта статья предполагает предварительное знакомство с основными концепциями работы систем, анализируемых в ней. Сравнительные анализ существующих систем можно найти также в работах [O'Rourke, 1982] и [Dietterich and Michalski, 1983].
Из поздних работ я бы отметил статью [Buchanan and Wilkihs, 1993], в которой вы найдете много информации о современном состоянии проблемы извлечения знаний и машинного обучения. Довольно подробное описание системы С4.5 представлено в [Quintan, 1993], причем в описание включены и листинги программ. Пространство версий рассматривается в книге [Mitchell, 1997, Chapter 2].
СистемMeta-DENDRAL
В рамках проекта DENDRAL, который был начат в Станфордском университете в 1965 году, была разработана первая система, продемонстрировавшая, что программа может успешно конкурировать с человеком-экспертом в определенной предметной области. Перед экспертной системой стояла задача определения молекулярной структуры неизвестного органического соединения. В экспертной системе использовался слегка модифицированный вариант метода порождения и проверки. Исходной информацией были показания масс-спектрометра, который бомбардировал образец соединения потоком электронов. В результате происходила перестройка структуры соединения и его компонентов. Перемещение отдельных атомов в структуре соединения соответствует отсоединению узла от одного подграфа и присоединению его к другому. Изменение структуры молекул соединения и улавливалось масс-спектрометром.
Проблема состояла в том, что для любой сложной молекулы существует множество вариантов разделения на фрагменты, поскольку в результате бомбардировки могут разрываться разные связи в молекуле, а соответственно и перемещаться могут разные фрагменты молекулы. В этом смысле теория масс-спектрометрии являетсл неполной— мы можем говорить только о вероятности разрыва определенной связи, но никогда не можем точно предсказать, как разделится молекула на фрагменты.
В рамках проекта DENDRAL была разработана программа CONGEN, которая формировала описание полной химической структуры, манипулируя символами, представляющими атомы и молекулы. В качестве входной информации эта программа получала формулу молекулы и набор ограничений, накладываемых на возможные взаимные связи между атомами. Результатом выполнения программы является список всех возможных комбинаций атомов в структуре молекулы с учетом заданных ограничений.
В состав DENDRAL входят также программы, которые помогают пользователю отбрасывать одни гипотезы и ранжировать другие, используя знания о связях показаний масс-спектрометра со структурой молекул соединения. Например, программа MSPRUNE отсеивает те гипотезы-кандидаты, которые предполагают варианты фрагментации, не совпадающие с полученными от масс-спектрометра данными. Программа MSRANK ранжирует оставшиеся гипотезы-кандидаты в соответствии с тем, какая часть пиков масс-спектрограммы, предсказанных этой гипотезой, была действительно обнаружена в полученных экспериментально данных. Таким образом, в экспертной системе DENDRAL фактически реализована стратегия "формирование гипотез и их последующая проверка". Исходные данные служат для формирования некоторого пространства гипотез, которые предсказывают наличие и отсутствие определенных свойств масс-спектрограммы, а затем эти гипотезы сопоставляются с результатами экспериментов.
Сопоставление экземпляров с образцами в Meta-DENDRAL
Для описания экземпляров обучающей выборки в Meta-DENDRAL используется тот же язык, что и для описания образцов. Каждый образец представляет собой описание определенной цельной молекулы, причем основное внимание уделяется описанию компонентов.
При сопоставлении экземпляров с образцами отыскивается цепочка связных отображений узлов образца и узлов экземпляра. Отображение X является связным, если оно является однозначным и допускающим вставку и если каждая пара узлов экземпляра Х(р1), Х(р2), соответствующая узлам образца р1 и р2, разделяет общую связь в том и только в том случае, если р1 и р2 также разделяют общую связь. Требуется также, чтобы значения характеристик каждого узла экземпляра Х(р) удовлетворяли ограничениям, определенным для соответствующего узла p образца.
Теперь открывается возможность дать определение частичного упорядочения по Митчеллу, специфичное для той предметной области, в которой используется система Meta-DENDRAL. В этом определении будет использовано и приведенное выше определение связности. Строчными буквами будем обозначать узлы образца, а прописными — весь образец в целом. Образец Р1 является более специфическим или равным образцу Р2 в том и только в том случае, когда существует такое связанное отображение X узлов в Р2 на узлы в Р1, что для каждой пары узлов р2, Х(р2) ограничения на значения свойств, ассоциированные с Х(р2), являются более специфическими или равными ограничениям, ассоциированным с р2. Для того чтобы разобраться в существе этого определения, имеет смысл вновь вернуться к примеру из мира блоков, который мы рассматривали выше. В мире химических структур аналогами блоков являются атомы и "суператомы", а аналогами пространственных отношений между блоками, такими как "поддерживает" или "касается", — химические связи.
Специфические знания из области химии могут быть двояко использованы алгоритмом отсеивания кандидатов.
(1)Язык представления химических структур допускает такие языковые формы представления образцов, которые синтаксически отличны, но семантически эквивалентны, т.е.
на этом языке один и тот же образец можно описать разными выражениями. Следовательно, для удаления избыточных образцов из граничных пространств версий требуется знание семантики образца, представленного в описании. Это не оказывает никакого влияния на полноту подхода, основанного на пространстве версий.
(2) Для некоторых проблем граничные пространства версий могут вырасти и достичь достаточно большого объема. Следовательно, было бы очень полезно использовать какие-либо правила для сокращения объемов граничных пространств. Однако, если использовать для этого эвристические методы, нет уверенности, что программа сможет определить все описания концептов, совместимые с обучающей выборкой.
Митчелл утверждает, что подход, основанный на пространстве версий, добавит новые возможности первоначальному варианту программы Meta-DENDRAL.
Можно модифицировать существующий набор правил новой обучающей выборкой и при этом не повторять анализ ранее представленной выборки.
Процесс обучения будет носить явно выраженный инкрементальный характер. Можно будет индивидуально решать для каждого правила, до какой степени имеет смысл его уточнять в процессе обучения.
Новая стратегия формирования правил позволит избежать использования "поиска со спуском" в программе RULEGEN и сосредоточить в первую очередь внимание на наиболее интересных экземплярах в обучающей выборке.
Метод анализа альтернативных версий каждого правила является более полным, чем операции обобщения и специализации в программе RULEMOD.
Суммируя все сказанное выше, приходим к выводу, что использование подхода, основанного на пространствах версий, позволяет реализовать методику инкрементального обучения (обучения с последовательным наращиванием уровня полноты знаний). Стратегия отсеивания кандидатов может быть противопоставлена стратегии поиска в глубину или в ширину, поскольку она позволяет отыскать не единственное приемлемое описание концепта, как при выполнении поиска в глубину, или максимально специфические описания, как при поиске в ширину, а все описания концептов, совместимые с обучающей выборкой.Митчелл также специально акцентирует внимание на том, что ключевым вопросом применения такой технологии является разработка методов формирования обучающей выборки.
Структурдереврешений
Дерево решений представляет один из способов разбиения множества данных на классы или категории. Корень дерева неявно содержит все классифицируемые данные, а листья — определенные классы после выполнения классификации. Промежуточные узлы дерева представляют пункты принятия решения о выборе или выполнения тестирующих процедур с атрибутами элементов данных, которые служат для дальнейшего разделения данных в этом узле.
В работе [Quinlan, 1993] дерево решений определено как структура, которая состоит из
узлов-листьев, каждый из которых представляет определенный класс;
узлов принятия решений, специфицирующих определенные тестовые процедуры, которые должны быть выполнены по отношению к одному из значений атрибутов; из узла принятия решений выходят ветви, количество которых соответствует количеству возможных исходов тестирующей процедуры.
Можно рассматривать дерево решений и с другой точки зрения: промежуточные узлы дерева соответствуют атрибутам классифицируемых объектов, а дуги — возможным альтернативным значениям этих атрибутов. Пример дерева представлен на рис. 20.2.
На этом дереве промежуточные узлы представляют атрибуты наблюдение, влажность, ветрено. Листья дерева промаркированы одним из двух классов П или Н. Можно считать, что П соответствует классу позитивных экземпляров концепта, а Н — классу негативных. Например, П может представлять класс "выйти на прогулку", а Н — класс "сидеть дома".
Хотя очевидно, что дерево решений является способом представления, отличным от порождающих правил, дереву можно сопоставить определенное правило классификации, которое дает для каждого объекта, обладающего соответствующим набором атрибутов (он представлен множеством промежуточных узлов дерева), решение, к какому из классов отнести этот объект (набор классов представлен множеством значений листьев дерева). В приведенном примере правило будет относить объекты к классу П или Н. Можно прямо транслировать дерево в правило, показанное ниже:
если наблюдение = облачно
v
наблюдение = солнечно &
влажность = нормально
v
наблюдение = дождливо &
ветрено = нет то П

Рис. 20.2. Дерево решений (заимствовано из [Quinlan, 1986, a])
Единственное приведенное правило, созданное непосредственно после преобразования дерева, можно разделить на три отдельных правила, которые не требуют использования логической дизъюнкции, а затем представить каждое из них на языке описания порождающих правил, например CLIPS:
if наблюдение = облачно
then П
if наблюдение = солнечно &
влажность = нормально then П
if наблюдение = дождливо &
ветрено = нет then П
Причина, по которой предпочтение иногда отдается деревьям решений, а не порождающим правилам, состоит в том, что существуют сравнительно простые алгоритмы построения дерева решений в процессе обработки обучающей выборки, причем построенные деревья могут быть использованы в дальнейшем для корректной классификации объектов, не представленных в обучающей выборке. Алгоритм системы ID3, который используется для построения дерева по обучающей выборке, мы рассмотрим в следующем разделе. Этот алгоритм достаточно эффективен с точки зрения количества вычислительных операций, поскольку объем вычислений растет линейно по отношению к размерности проблемы.
В табл. 20.2 показана обучающая выборка, которая использовалась для формирования дерева на рис. 20.2.
Таблица 20.2. Обучающая иыборка (заимствовано us [Quinlan, 1986,a])
Номер |
Наблюдение |
Температура |
Влажность |
Ветрено |
Класс |
||
1 |
Солнечно |
Жарко |
Высокая |
Нет |
Н |
||
2 |
Солнечно |
Жарко |
Высокая |
Да |
Н |
||
3 |
Облачно |
Жарко |
Высокая |
Нет |
п |
||
4 |
Дождливо |
Умеренно |
Высокая |
Нет |
п |
||
5 |
Дождливо |
Холодно |
Нормальная |
Нет |
п |
||
6 |
Дождливо |
Холодно |
Нормальная |
Да |
Н |
||
7 |
Облачно |
Холодно |
Нормальная |
Да |
п |
||
8 |
Солнечно |
Умеренно |
Высокая |
Нет |
Н |
||
9 |
Солнечно |
Холодно |
Нормальная |
Нет |
п |
||
10 |
Дождливо |
Умеренно |
Нормальная |
Нет |
п |
||
11 |
Солнечно |
Умеренно |
Нормальная |
Да |
п |
||
12 |
Облачно |
Умеренно |
Высокая |
Да |
п |
||
13 |
Облачно |
Жарко |
Нормальная |
Нет |
п |
||
14 |
Дождливо |
Умеренно |
Высокая |
Да |
Н |
||
В чем отличие методик супервизорного
1. В чем отличие методик супервизорного обучения и "обучения без преподавателя"?
2. Проведите разграничение между задачами "обучение концептам" и "обобщение дескрипторов".
3. По образцу, приведенному в тексте главы, постройте обучающую выборку для следующих концептов:
I) иностранная машина,
II) маленькая иностранная машина,
III) маленькая американская машина.
Как вы думаете, можно ли использовать в обучающей выборке для концептов II) и III) те же экземпляры, что и представленные в табл. 20.1?
4. На рис. 20.4 показаны три пары образцов. Скажите, во всех ли парах имеются более и менее специфические образцы, а если это так, то какой именно из них является более специфическим.
5. Рассмотрите обучающую выборку, представленную в табл. 20.2. Из 14 объектов 9 относятся к классу П, а 5 — к классу Н. Следовательно, энтропия множества сообщений будет равна
-(9/14)log2(9/14) - (5/14)*log2(l/J4) = 0.94 бит.

Рис. 20.4. Пары образцов
I) Чему равно ожидаемое количество информации для атрибута наблюдение?
II) Чему равен прирост количества информации после анализа атрибута наблюдение?
III) Повторите этот анализ по отношению к атрибутам влажность и ветрено.
IV) Анализ какого атрибута сулит наибольший прирост количества информации?
6. Перечислите несколько методик обучения, которые используются в практике работы с людьми, и постарайтесь разграничить эти методики по характеру. Например, методика обучения таблице умножения существенно отличается от методики обучения игре на музыкальных инструментах. Какая из методик легче всего реализуется программно и почему?
Уточнение наборов правил
Проблеме отладки и уточнения характеристик правил посвящено множество исследований. Ниже мы рассмотрим только пару примеров, которые позволят читателям понять суть этой проблемы, слегка "прикоснуться" к методам ее решения и послужат отправной точкой для более углубленного изучения этой темы. Несмотря на то что эта работа имеет теоретическую направленность, ее практическая ценность несомненна. Появление любого инструментального средства, которое поможет повысить производительность набора взвешенных правил в экспертной системе, будет только приветствоваться инженерами по знаниям.
Если в нашем распоряжении имеется набор правил, сформированный по индукции программой обучения или извлеченный в процессе собеседования с экспертом, то нас, как правило, больше всего интересует следующее:
"взнос" отдельных правил в результат;
эффективность набора правил в целом и достоверность получаемого результата.
В отношении отдельных правил наибольшую озабоченность вызывают характеристики "применимости": насколько часто правило применяется корректно, а насколько часто оно приводит к ошибочному заключению. В отношении набора правил в целом желательно знать, какова полнота набора, т.е. насколько этот набор позволяет охватить все возможные комбинации исходных данных, не является ли он избыточным, т.е. нет ли в нем правил, которые можно удалить без ущерба для качества результата. При этом нужно учитывать, что хотя само по себе "избыточное" правило может быть вполне корректным, удаление его из набора может положительно сказаться на производительности экспертной системы.
В работе [Langlotz et al, 1986] представлен метод теории принятия решений, который позволяет уточнять характеристики отдельных правил. Если в спецификации правила имеются свойства, которые можно варьировать, например связанные с вероятностными характеристиками, очень полезно выяснить, как сказывается изменение этого параметра на результатах работы системы.
В качестве иллюстрации авторы работы рассматривали простое правило системы MYCIN, которое "оппонирует" применению тетрациклина при лечении детей, поскольку этот препарат оказывает нежелательный побочный эффект на состояние зубов ребенка.
ЕСЛИ
1) против инфекции предполагается применение тетрациклина;
2) возраст пациента (лет) менее 8,
ТО
есть серьезное основание полагать (0.8), что применение тетрациклина не рекомендуется против этой инфекции.
Это правило содержит в себе возможность варьирования между воздействием на поразившую пациента инфекцию и риском отрицательного побочного эффекта. Ожидаемая полезность применения этого правила является функцией полезности результатов правила и вероятностей реального получения этих результатов.
В теории принятия решений ожидаемая полезность (EU — expected utility) действия А, возможные результаты которого есть элементы множества {О1, О2, ...,Оn}, причем исходы характеризуются вероятностями р1,р2, ...,рn, выражается формулой
EU(A) = Sumi[pi u(Oi) i=1,..,n.]
В этой формуле и(Оi) означает оценку полезности отдельного варианта результата операции (исхода) Оi. Нас интересует, как будет меняться полезность действия, которое рекомендуется правилом, при изменении вероятностей рi и оценок полезности и(Оi). Если, например, инфекция, к которой имеет отношение это правило, устойчива против всех прочих препаратов, кроме тетрациклина, а вероятность побочного эффекта довольно мала, то значение EU(A) будет более высоким по сравнению с ситуацией, когда против инфекции можно применить и другие препараты, не имеющие побочных эффектов, а вероятность побочного эффекта от применения тетрациклина довольно высока.
Авторы описывают применение методов анализа чувствительности, которые позволяют выявить зависимость между полезностью исходов и их вероятностями. Точка, в которой рекомендации альтернативных курсов лечения имеют равную полезность, представляет пороговое значение вероятности. Анализируя эти пороговые значения, можно определить, насколько далеко отстоит оценка вероятности в модели от того значения, при котором потребуется изменить принятое оптимальное решение. Усилия, затраченные на выполнение описанного анализа, окупаются тем, что инженер по знаниям и эксперт получают более точное обоснование рациональности применения того или иного правила.
В частности, методы теории принятия решений позволяют определить в явном виде значения тех переменных, от которых зависит применимость отдельных правил. Это поможет инженеру по знаниям отыскать нежелательные взаимосвязи между правилами в наборе, включая и такие, которые являются результатом вероятностных зависимостей, рассмотренных нами в главе 9.
В работе [Wilkins and Buchanan, 1986] основное внимание уделено комплексной отладке набора эвристических правил. Авторы работы утверждают, что поочередная (инкрементальная) модификация отдельных правил в процессе настройки и эксплуатации экспертной системы (например, как это делается в программе TEIRESIAS, описанной в главе 10) не гарантирует сходимости процесса к оптимальному набору правил. Они предостерегают против применения "универсальных стратегий" делать правила более общими или более специализированными в тех случаях, когда обнаруживаются неверные результаты работы системы в целом. Эвристические правила по самой своей природе являются приблизительными и их нельзя модифицировать только потому, что обнаружен отдельный неправильный результат. Фактически любое эвристическое правило представляет определенный компромисс между общностью и специализацией в терминах некоторой общей линии поведения, а потому вполне целесообразно уделить основное внимание именно этой линии поведения, а не вносить судорожно изменения в отдельные правила.
Авторы дают определение оптимальному набору правил, как такому, который минимизирует вероятность получения неверных результатов. Предполагается, что отдельные правила в наборе соответствуют определенному стандарту качества, а главные усилия направляются на выбор в существующем наборе подмножества правил, наилучшего в определенном смысле. Процесс отбора такого оптимального подмножества формулируется как проблема минимизации двудольного графа (bipartite graph minimization problem), которая базируется на отображении множества вершин, представляющих объекты обучающей выборки, на множество вершин, представляющих исходное множество правил.
Показано, что хотя в общем виде эта проблема относится к классу необозримых, но существует эвристический метод ее решения для конкретной постановки, связанной со спецификой экспертных систем. Предлагаемое решение в основном сводится к тому, чтобы минимизировать в наборе вредные взаимные связи между "хорошими" эвристическими правилами, которые сформированы индуктивными методами.
Другая работа, имеющая отношение к проблематике настройки наборов порождающих правил, посвящена описанию системы LAS (Learning Apprentice System) [Smith et al, 1985]. LAS представляет собой интерактивный инструментальный комплекс для создания и настройки баз знаний. В системе частично автоматизирован процесс формирования эвристических правил на основании теории предметной области и отладки этих правил при возникновении каких-либо проблем с их применением в экспертной системе. Работа LAS базируется на формализме сетей зависимостей (они обсуждаются в главе 19), который используется для представления обоснования правил в терминах теории предметной области. Эти же структуры используются и для формирования пояснений при возникновении сбоев в работе системы.
Разработки, упоминавшиеся в этой главе, демонстрируют возможность создания средств автоматизации формирования баз знаний. Хотя некоторые из них носят исследовательский характер, совершенно очевиден прогресс в этой области искусственного интеллекта, который позволяет надеяться, что в недалеком будущем будет устранено наиболее узкое место в создании экспертных систем — найдено эффективное решение задачи приобретения знаний.
Подводя итог всему сказанному об исследованиях в области машинного обучения, отметим, что эти исследования обещают внести значительный вклад в теорию и практику не только экспертных систем, но и других проблем искусственного интеллекта.
