Источники неопределенности
9.1. Источники неопределенности
При решении проблем мы часто встречаемся со множеством источников неопределенности используемой информации, но в большинстве случаев их можно разделить на две категории: недостаточно полное знание предметной области и недостаточная информация о конкретной ситуации.
Теория предметной области (т.е. наши знания об этой области) может быть неясной или неполной: в ней могут использоваться недостаточно четко сформулированные концепции или недостаточно изученные явления. Например, в диагностике психических заболеваний существует несколько отличающихся теорий о происхождении и симптоматике шизофрении.
Неопределенность знаний приводит к тому, что правила влияния даже в простых случаях не всегда дают корректные результаты. Располагая неполным знанием, мы не можем уверенно предсказать, какой эффект даст то или иное действие. Например, терапия, использующая новые препараты, довольно часто дает совершенно неожиданные результаты. И, наконец, даже когда мы располагаем достаточно полной теорией предметной области, эксперт может посчитать, что эффективнее использовать не точные, а эвристические методы. Так, методика устранения неисправности в электронном блоке путем замены подозрительных узлов оказывается значительно более эффективной, чем скрупулезный анализ цепей в поиске детали, вышедшей из строя.
Но помимо неточных знаний, неопределенность может быть внесена и неточными или ненадежными данными о конкретной ситуации. Любой сенсор имеет ограниченную разрешающую способность и отнюдь не стопроцентную надежность. При составлении отчетов могут быть допущены ошибки или в них могут попасть недостоверные сведения. На практике далеко не всегда можно получить полные ответы на поставленные вопросы и хотя можно воспользоваться различного рода дополнительной информацией о пациенте, например с помощью дорогостоящих процедур или хирургическим путем, такие методики используются крайне редко из-за высокой стоимости и рискованности. Помимо всего прочего, существует еще и фактор времени. Не всегда есть возможность быстро получить необходимые данные, когда ситуация требует принятия срочного решения. Если работа ядерного реактора вызывает подозрение, вряд ли кто-нибудь будет ждать окончания всего комплекса проверок, прежде чем принимать решение о его остановке.
Суммируя все сказанное, отметим, что эксперты пользуются неточными методами по двум главным причинам:
точных методов не существует;
точные методы существуют, но не могут быть применены на практике из-за отсутствия необходимого объема данных или невозможности их накопления по соображениям стоимости, риска или из-за отсутствия времени на сбор необходимой информации.
Большинство исследователей, занимающихся проблемами искусственного интеллек: та, давно пришли к единому мнению, что неточные методы играют важную роль в разработке экспертных систем, но много споров вызывает вопрос, какие именно методы должны использоваться. До последнего времени многие соглашались с утверждениями Мак-Карти и Хейеса, чт.о теория вероятности не является адекватным инструментом для решения задач представления неопределенности знаний и данных [McCarthy and Hayes, 1969]. Выдвигались следующие аргументы в пользу такого мнения:
теория вероятности не дает ответа на вопрос, как комбинировать вероятности с количественными данными (см. об этом в главе 8);
назначение вероятности определенным событиям требует информации, которой мы просто не располагаем.
Другие исследователи прибавляли к этим аргументам свои:
непонятно, как количественно оценивать такие часто встречающиеся на практике понятия, как "в большинстве случаев", "в редких случаях", или такие приблизительные оценки, как "старый" или "высокий";
применение теории вероятности требует "слишком много чисел", что вынуждает инженеров давать точные оценки тем параметрам, которые они не могут оценить;
обновление вероятностных оценок обходится очень дорого, поскольку требует большого объема вычислений.
Все эти соображения породили новый формальный аппарат для работы с неопределенностями, который получил название нечеткая логика (fuzzy logic) или теория функций доверия (belieffunctions). Этот аппарат широко используется при решении задач искусственного интеллекта и особенно при построении экспертных систем. Нечеткая логика будет рассмотрена ниже в этой главе, а о теории функций доверия (ее также называют теорией признаков Демпстера— Шафера) мы поговорим в главе 21. Однако в последние годы адвокаты теории вероятностей предприняли довольно эффективную контратаку, а потому мы также представим читателям основные концепции этой теории и ее главных конкурентов, а обзор дальнейшего развития работ в этом направлении отложим до следующей главы.
Условная вероятность
9.2.1. Условная вероятность
Условная вероятность события d при данном s — это вероятность того, что событие d наступит при условии, что наступило событие s. Например, вероятность того, что пациент действительно страдает заболеванием d, если у него (или у нее) обнаружен только симптом s.
В традиционной теории вероятностей для вычисления условной вероятности события d при данном s используется следующая формула:
P(d|s)=(d^ s)/P(S) (9.1)
Как видно, условная вероятность определяется в терминах совместимости событий. Она представляет собой отношение вероятности совпадения событий d и s к вероятности появления события s. Из формулы (9.1) следует, что
P(d^s)=P(d|s)P(d).
Если разделить обе части на P(s) и подставить в правую часть (9.1), то получим правило Байеса в простейшем виде:
P(d|s)=(s|d)P(d)/P(S) (9.2)
Для систем, основанных на знаниях, формула (9.2) гораздо удобнее формулы (9.1), в чем вы сможете убедиться в дальнейшем.
Предположим, что у пациента имеется некоторый симптом заболевания, например боль в груди, и желательно знать, какова вероятность того, что этот симптом является следствием определенного заболевания, например инфаркта миокарда или перикардита (воспаление каверн в легких), или чего-нибудь менее серьезного, вроде несварения желудка. Для того чтобы вычислить вероятность Р(инфаркт миокарда боль в груди) по формуле (9.1), нужно знать (или оценить каким-либо способом), сколько человек в мире страдают таким заболеванием и сколько человек и больны инфарктом миокарда, и жалуются на боль в груди (т.е. имеют такой же симптом). Как правило, такая информация отсутствует, особенно последняя, которая нужна для вычисления вероятности Р (инфаркт миокарда л боль в груди). Таким образом, определение, данное формулой (9.1), в клинической практике не может быть использовано.
Отмеченная сложность получения нужной информации явилась причиной негативного отношения многих специалистов по искусственному интеллекту к вероятностному подходу вообще (см., например, [Charniak and McDermott, 1985, Chapter 8]). Это негативное отношение подкреплялось тем, что в большинстве классических работ по теории вероятностей понятие вероятности определялось как объективная частотность (частота появления при достаточно продолжительных независимых испытаниях).
Однако существует мнение, что эти базовые предположения небесспорны с точки зрения практических приложений (см., например, [Pearl, 1982] и [Cheeseman, 1985]). Сторонники такого подхода придерживаются субъективистской точки зрения на определение вероятности, который позволяет иметь дело с оценками совместного появления событий, а не с действительной частотой. Такой взгляд на вещи связывает вероятность смеси событий с субъективной верой в то, что событие действительно наступит.
Например, врач может не знать или не иметь возможности вычислить, какая часть пациентов, жалующихся на боль в груди, страдает инфарктом миокарда, но на основании собственного опыта он может оценить, у какой части его пациентов, страдающих этим заболеванием, встречался такой симптом. Следовательно, он может оценить значение вероятности Р(боль в груди | инфаркт миокарда). Субъективный взгляд на природу вероятности тесно связан с правилом Байеса по следующей причине. Предположим, мы располагаем достаточно достоверной оценкой вероятности P(s | а), где 5 означает симптом, a d— заболевание. Тогда по формуле (9.2) можно вычислить вероятность P(d\ s). Оценку вероятности P(d) можно взять из публикуемой медицинской статистики, а оценить значение P(s) врач может на основании собственных наблюдений.
Вычисление P(d | s) не вызывает затруднений, когда речь идет о единственном симптоме, т.е. имеется множество заболеваний D и множество симптомов S, причем для каждого члена из D нужно вычислить условную вероятность того, что у пациентов, страдающих этим заболеванием, наблюдался один определенный симптом из множества S. Тем не менее, если в множестве D имеется т членов, а в множестве S— п членов, потребуется вычислить тп + т + п оценок вероятностей. Это отнюдь не простая работа, еcли в системе медицинской диагностики используется до 2000 видов заболеваний и огромное число самых разнообразных симптомов.
Но ситуация значительно усложняется, если мы попробуем включить в процесс составления диагноза не один симптом, а несколько.
В более общей форме правило Байеса имеет вид
P(d|s1^...^sk )= P(s1^...^sk|d)P(d)/P(s1^...^sk) (9.3)
и требует вычисления (mn)k + m + nk оценок вероятностей, что даже при небольшом значении А; очень много. Эти оценки вероятностей требуются нам по той причине, что в общем случае для вычисления P(s1 ^ ....^ sk) нужно предварительно вычислить произведения вида
P(s1 | s2 ^.. .^sk )P(s2 | s3 ^.. .^sK )... P(sk ) .
P(Si)=P(Sl|Sj),
из чего следует соотношение
P(Si^Sj)=P(Si)P(Sj).
Если все симптомы независимы, то объем вычислений будет таким же, как и в случае учета при диагнозе единственного симптома.
Но, даже если это и не так, в большинстве случаев можно предположить наличие условной независимости. Это означает, что пара симптомов s\ и Sj является независимой, поскольку в нашем распоряжении имеются какие-либо дополнительные свидетельства на этот счет или фундаментальные знания Е. Таким образом,
P(Si|Sj,E)=P(Si|E).
Например, если в моем автомобиле нет горючего и не работает освещение, я могу смело сказать, что эти симптомы независимы, поскольку моих познаний в устройстве автомобиля вполне достаточно, чтобы предположить, что между ними нет никакой причинной связи. Но если автомобиль не заводится и не работает освещение, то заявлять, что эти симптомы независимы, нельзя, поскольку они могут быть следствием одной и той же неисправности аккумуляторной батареи. Степень доверия к симптому "не работает освещение" только увеличится, если обнаружится, что к тому же и двигатель не заводится. Необходимость отслеживать такого рода связи в программе и соответственно корректировать степень доверия к симптомам значительно увеличивает объем вычислений в общем случае (см. об этом в работе [Cooper, 1990]).
Таким образом, использование теории вероятности ставит перед нами следующие проблемы, которые лучше всего сформулировать в терминах задачи выбора:
либо априори предполагается, что все данные независимы, и использовать менее трудоемкие методы вычислений, за что придется платить снижением достоверности результатов;
либо нужно организовать отслеживание зависимости между используемыми данными, количественно оценить эту зависимость, реализовать оперативное обновление соответствующей нормативной информации, т.е. усложнить вычисления, но получить более достоверные результаты.
В главе 19 представлен обзор символических методов отслеживания зависимости между используемыми данными, а в главе 21 описаны некоторые численные методы моделирования зависимости между вероятностями.
В следующем разделе мы рассмотрим альтернативный подход, с помощью которого удается обойти указанные сложности при построении экспертных систем. Здесь же, а также в главе 21 будут проанализированы критические замечания, касающиеся этого подхода.
Коэффициенты уверенности
9.2.2. Коэффициенты уверенности
Теперь мы вернемся к коэффициентам уверенности, о которых уже шла речь в главе 3, когда мы рассматривали принципы работы системы MYCIN.
В идеальном мире можно вычислить вероятность P(di| E), где di — i-я диагностическая категория, а £ представляет все необходимые дополнительные свидетельства или фундаментальные знания, используя только вероятности P(di | Sj), где Sj является j-м клиническим наблюдением (симптомом). Мы уже имели возможность убедиться в том, что правило Байеса позволяет выполнить такие вычисления только в том случае, если, во-первых, доступны все значения P(sj | di), и, во-вторых, правдоподобно предположение о взаимной независимости симптомов.
В системе MYCIN применен альтернативный подход на основе правил влияния, которые следующим образом связывают имеющиеся данные (свидетельства) с гипотезой решения:
ЕСЛИ
пациент имеет показания и симптомы s1 ^ ...^ sk и имеют место определенные фоновые условия t1 ^ ... ^ fm ,
ТО
можно с уверенностью т заключить, что пациент страдает заболеванием di.
Основная идея состоит в том, чтобы с помощью порождающих правил такого вида попытаться заменить вычисление P(di | s1 ^ ... ^ sk) приближенной оценкой и таким образом сымитировать процесс принятия решения экспертом-человеком. Как было показано в главе 3, результаты применения правил такого вида связываются с коэффициентом уверенности окончательного заключения с помощью CF(a) — коэффициент уверенности в достоверности значения параметра а, а дополнительные условия t1 ^ ... ^ tm представляют фоновые знания, которые ограничивают применение конкретного правила. Чаще всего оказывается, что эти условия могут быть интерпретированы значениями "истина" или "ложь", т.е. соответствующие коэффициенты принимают значение +1 или -1. Таким образом, отличные от единицы значения коэффициентов характеризуют только симптомы s1, ... , sk. Роль фоновых знаний состоит в том, чтобы разрешить или запретить применение правила в данном конкретном случае. Пусть, например, имеется диагностическое правило, связывающее появление болей в брюшной полости с возможной беременностью. Применение этого правила блокируется фоновым знанием, что оно справедливо только по отношению к пациентам-женщинам.
Бучанан и Шортлифф утверждают, что, строго говоря, применение правила Байеса в любом случае не позволяет получить точные значения, поскольку используемые условные вероятности субъективны [Buchanan and Shortliffe, 1984, Chapter 11]. Как мы уже видели, это основной аргумент против применения вероятностного подхода. Однако такая аргументация предполагает объективистскую интерпретацию понятия вероятности, т.е. предполагается, что "правильные" значения все же существуют, но мы не можем их получить, а раз так, то и правило Байеса нельзя использовать. Этот аргумент имеет явно схоластический оттенок, поскольку любая экспертиза, проводимая инженером по знаниям, совершенно очевидно сводится к представлению тех знаний о предметной области, которыми обладает человек-эксперт (эти знания, конечно же, являются субъективными), а не к воссозданию абсолютно адекватной модели мира. С точки зрения теории представляется, что целесообразнее использовать математически корректный формализм к неточным данным, чем формализм, который математически некорректен, к тем же неточным данным.
Перл обратил внимание на важное практическое достоинство подхода, основанного на правилах [Pearl, 1988, р.5]. Вычисление коэффициентов уверенности заключения имеет явно выраженный модульный характер, поскольку не нужно принимать во внимание никакой иной информации, кроме той, что имеется в данном правиле. При этом не имеет никакого значения, как именно получены коэффициенты уверенности, характеризующие исходные данные.
При построении экспертных систем часто используется эта особенность. Полагается, что для всех правил, имеющих дело с определенным параметром, предпосылки каждого правила логически независимы. Анализируя систему MYCIN, Шортлифф посоветовал сгруппировать все зависимые признаки в единое правило, а не распределять их по множеству правил (см., например, [Buchanan and Shortliffe, 1984, p. 229]).
Пусть, например, существует зависимость между признаками Е1 и E2- Шортлифф рекомендует сгруппировать их в единое правило если E1 и Е2, то приходим к заключению Н с уверенностью т, а не распределять по двум правилам если E1, то приходим к заключению Н с уверенностью t, если Е2, то приходим к заключению Н с уверенностью t.
В основе этой рекомендации лежит одно из следствий теории вероятностей, гласящее, что Р(Н | E1, Е2) не может быть простой функцией от Р(Н | Е1) и Р(Н | Е2).
Выражения для условной вероятности не могут в этом смысле рассматриваться как модульные. Выражение
P(B | A) = t
не позволяет заключить, что Р(В) = t при наличии А, если только А не является единственным известным признаком. Если кроме А мы располагаем еще и знанием Е, то нужно сначала вычислить Р(В | А, Е), а уже потом можно будет что-нибудь сказать и о значении Р(В). Такая чувствительность к контексту может стать основой очень мощного механизма логического вывода, но, как уже не раз подчеркивалось, за это придется платить существенным повышением сложности вычислений.
Коэффициенты уверенности и условные вероятности
9.2.3. Коэффициенты уверенности и условные вероятности
Адаме показал, что если используется простая вероятностная модель на основе правила Байеса, то в системе MYCIN коэффициенты уверенности гипотез не соответствуют вероятностям гипотез при заданных признаках [Adams, 1976]. На первый взгляд, если коэффициенты уверенности используются только для упорядочения альтернативных гипотез, это не очень страшно. Но Адаме также показал, что возможна ситуация, когда при использовании коэффициентов уверенности две гипотезы будут ранжированы в обратном порядке по отношению к соответствующим вероятностям. Рассмотрим этот вопрос подробнее.
Обозначим через Р(h) субъективное, т.е. составленное на основе заключения эксперта, значение вероятности того, что гипотеза h справедлива, т.е. значение Р(Н) отражает степень уверенности эксперта в справедливости гипотезы h. Усложним положение дел и добавим новый признак е в пользу этой гипотезы, такой что P(h | е) > Р(h). Степень доверия эксперта к справедливости гипотезы увеличится, и это увеличение выразится отношением
MB(h,e)= [P(h|e)-P(h)]/[1-P(h)]
где MB означает относительную меру доверия.
Если же признак е свидетельствует против гипотезы h, т.е. P(h | е) < P(h), то увеличится мера недоверия эксперта к справедливости этой гипотезы. Меру недоверия MD можно выразить следующим отношением:
MD(h, e) =[P(h)-P(h|e) ] / P(h)]
Адаме обратил внимание на то, что уровни доверия к одной и той же гипотезе с учетом разных дополнительных признаков не могут быть определены независимо. Если некоторый признак является абсолютным диагностическим индикатором конкретного заболевания, т.е. если все пациенты с симптомом s1 страдают заболеванием dj, то никакие другие признаки уже не могут изменить диагноз, т.е. уровень доверия к выдвинутой гипотезе. Другими словами, если существует пара признаков s1 и s2 и
P(di|s1)=P(di|S1^S2)=1,
то
P(di|s2)= P(dl).
Бучанан и Шортлифф определили коэффициент уверенности как некий артефакт, который позволяет численно оценить комбинацию уровней доверия или недоверия к гипотезам [Buchanan and Shortliffe, 1984, p. 249]. Он представляет собой разницу между мерой доверия и недоверия:
CF(h, еа ^ ef ) = MB(h, ef) - MD(h, ea),
P(h|ea^ef)=[P(ea^ef | h)P(h)]/[P(ea^ef )]
управлять ходом выполнения программы при формировании суждений;
управлять процессом поиска цели в пространстве состояний: если коэффициент уверенности гипотезы оказывается в диапазоне [+0.2, -0.2], то поиск блокируется;
ранжировать набор гипотез после обработки всех признаков.
Адаме, однако, показал, что ранжирование гипотез на основе коэффициентов уверенности может дать результат, противоположный тому, который будет получен при использовании вероятностных методов. Он продемонстрировал это на следующем примере.
Положим, что d1u d2 — это две гипотезы, а е — признак, свидетельствующий как в пользу одной гипотезы, так и в пользу другой. Пусть между априорными вероятностями существует отношение P(d1) > P(d2) и P(d\ \ е) > P(d2 | е). Другими словами, субъективная вероятность справедливости гипотезы d\ больше, чем гипотезы d2, причем это соотношение сохраняется и после того, как во внимание принимается дополнительный признак. Адаме показал, что при этих условиях возможно обратное соотношение CF(d1, е) < CF(d2, е) между коэффициентами уверенности гипотез.
Предположим, что вероятности имеют следующие значения:
P(d1) = 0.8,
P(d2) = 0.2,
P(d1|e) = 0.9,
P(d2| e) = 0.8.
d2 — (0.8 - 0.2) / 0.8 = 0.75.
Отсюда следует, что CF(d1| e) < CF(d2, е), несмотря на то, что и P(d1 | e) > P(d2| е).
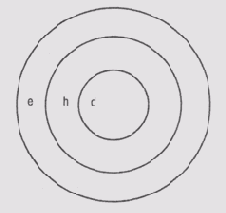
Последовательное применение правил в системе MYCIN также связано с существованием определенных теоретических проблем. Используемая при этом функция комбинирования основана на предположении, что если признак е влияет на некоторую промежуточную гипотезу h с вероятностью P(h | е), а гипотеза h входит в окончательный диагноз d с вероятностью P(d | h), то
P(d|e) = P(d|h)P(h|e).
Таким образом, создается впечатление, что транзитивное отношение в последовательности правил вывода суждений справедливо на первом шаге, но не справедливо в общем случае. Для того чтобы существовала связь между правилами, популяции, связанные с этими категориями, должны быть вложены примерно так, как на рис. 9.1.
Экспертные системы и теория вероятностей
9.2. Экспертные системы и теория вероятностей
В этом разделе будут рассмотрены те аспекты теории вероятностей, которые имеют отношение к представлению неопределенностей. Мы начнем с понятия условной вероятности и остановимся на тех причинах, по которым вероятностный подход критикуется большинством исследователей, занимающихся экспертными системами. Затем мы вернемся к коэффициентам уверенности, которые обсуждались в главе 3 в связи с системой MYCIN, рассмотрим их подробнее и сравним результаты, которые получаются при использовании этого аппарата и аппарата теории вероятностей.
Нечеткие множества
9.3.1. Нечеткие множества
То знание, которое использует эксперт при оценке признаков или симптомов, обычно базируется скорее на отношениях между классами данных и классами гипотез, чем на отношениях между отдельными данными и конкретными гипотезами. Большинство методик .решения проблем в той или иной форме включает классификацию данных (сигналов, симптомов и т.п.), которые рассматриваются как конкретные представители некоторых более общих категорий. Редко когда эти более общие категории могут быть четко очерчены. Конкретный объект может обладать частью характерных признаков определенной категории, а частью не обладать, принадлежность конкретного объекта к определенному классу может быть размыта. Предложенная Заде [Zadeh, 1965] теория нечетких множеств (fuzzy set theory) представляет собой формализм, предназначенный для формирования суждений о таких категориях и принадлежащих к ним объектах. Эта теория лежит в основе нечеткой логики (fuzzy logic) [Zadeh, 1975] и теории возможностей (possibility theory) [Zadeh, 1978].
Классическая теория множеств базируется на двузначной логике. Выражения в форме а & А, где а представляет индивидуальный объект, а А — множество подобных объектов, могут принимать только значение "истина" либо "ложь". После появления понятия "нечеткое множество" прежние классические множества иногда стали называть жесткими. Жесткость классической теории множеств стала источником ряда проблем при попытке применить ее к нечетко определенным категориям.
Рассмотрим категорию, определенную словом "быстрый" (fast). Если применить это определение к автомобилям, то какой автомобиль можно считать быстрым? В классической теории мы можем определить множество А "быстрых автомобилей" либо перечислением (составив список всех членов множества), либо введя в рассмотрение некоторую характеристическую функцию f такую, что для любого объекта X
f(X) = истина тогда и только тогда, когда Х принадлежит А.
Например, эта функция может отбирать только те автомобили, которые имеют скорость более 150 миль в час:
GT150(X)={ истина,если CAR(X) и TOP_SPEED(X) > 150 ложь в противном случае
Множество, определенное такой характеристической функцией, представляется формулой
{Х ~ CAR TOP-SPEED(X)> 150}.
Эта формула утверждает, что элементами нового множества являются те элементы множества CAR, которые имеют максимальную скорость свыше 150 миль в час.
А что можно сказать о множестве (категории) "быстрых" автомобилей? Интуитивно кажется, что ситуация сходна с представленной на рис. 9.2, где границы множества размыты и принадлежность элементов множеству может быть каким-то образом ранжирована. В таком случае можно говорить о том, что отдельный объект (автомобиль) более или менее типичен для этого множества (категории). Можно с помощью некоторой функции/охарактеризовать степень принадлежности объектов X такому множеству. Функция /(X) определена на интервале [0,1]. Если для объекта X функция f(X) = 1, то объект определенно является членом множества, если ДА) = 0, то объект определенно не является членом множества. Все промежуточные значения означают степень членства объекта X в этом множестве. В примере с автомобилями нам понадобится функция, оперирующая с максимальной скоростью каждого претендента на членство. Можно определить ее таким образом, что fFAST(80) = 0, fFAST(180) = 1, а промежуточные значения представляются некоторой монотонной гистограммой, имеющей значения в интервале между нулем и единицей. Тогда множество "быстрых автомобилей" может быть охарактеризовано функцией
fFAST CAR(X) =fFAST(TOP-SPEED(X)),
FAST-CAR = {(Porche-944, 0.9),
(BMW-316, 0.5), (Chevy-Nova, 0.1)}.
Нечеткая логика
9.3.2. Нечеткая логика
Ту роль, которую в классической теории множеств играет двузначная булева логика, в теории нечетких множеств играет многозначная нечеткая логика, в которой предположения о принадлежности объекта множеству, например FAST-CAR(Porche-944), могут принимать действительные значения в интервале от 0 до 1. Возникает вопрос, а как, используя концепцию неопределенности, вычислить значение истинности сложного выражения, такого как
¬FAST¬CAR(Chevy-Nova).
¬F(X)=1-F(X).
"Porche 944 является быстрым (fast), представительским (pretentious) автомобилем". В классической логике предположение
FAST-CAR(Porche-944) ^PRETENTIOUS-CAR(Porche-944)
является истинным в том и только в том случае, если истинны оба члена конъюнкции. В нечеткой логики существует соглашение: если F и G являются нечеткими предикатами, то
Таким образом, если
FAST-CAR(Porche-944) = 0.9
PRETENTIOUS-CAR(Porche-944) = 0.7,
FAST-CAR(Porche-944) ^ PRETENTIOUS-CAR(Porche-944) = 0.7.
А теперь рассмотрим выражение
Вероятность истинности этого утверждения равна 0, поскольку
но в нечеткой логике значение этого выражения будет равно 0.1 . Какой смысл имеет это значение. Его можно считать показателем принадлежности автомобиля к нечеткому множеству среднескоростных автомобилей, которые в чем-то близки к быстрым, а в чем-то — к медленным.
Смысл выражения FAST-CAR(Porche-944) = 0.9 заключается в том, что мы только на 90% уверены в принадлежности этого автомобиля к быстрым именно из-за неопределенности самого понятия "быстрый автомобиль". Вполне резонно предположить, что существует некоторая уверенность в том, что Porche-944 не принадлежит к быстрым, например он медленнее автомобиля, принимающего участие в гонках "Формула-1".
Аналог операции дизъюнкции в нечеткой логике определяется следующим образом:
f(F v G)(X) = max(fF(X),fG(X)).
Р(А v В) = Р(А) + Р(B) - Р(А ^ В) .
FAST-CAR(Porche-944) v ¬FAST-CAR(Porche-944) = 0.9,
FAST-CAR(BMW-316) v FAST-CAR(BMW-316) = 0.5,
FAST-CAR(Chevy-Nova) v FAST-CAR(Chevy-Novd) = 0.9.
Операторы обладают свойствами коммутативности, ассоциативности и взаимной дистрибутивности. Как к операторам в стандартной логике, к ним применим принцип композитивности, т.е. значения составных выражений вычисляются только по значениям выражений-компонентов. В этом операторы нечеткой логики составляют полную противоположность законам теории вероятностей, согласно которым при вычислении вероятностей конъюнкции и дизъюнкции величин нужно принимать во внимание условные вероятности.
Теория возможности
9.3.3. Теория возможности
Нечеткая логика имеет дело с ситуациями, когда и сформулированный-вопрос, и знания, которыми мы располагаем, содержат нечетко очерченные понятия. Однако нечеткость формулировки понятий является не единственным источником неопределенности. Иногда мы просто не уверены в самих фактах. Если утверждается: "Возможно, что Джон сейчас в Париже", то говорить о нечеткости понятий Джон и Париж не приходится. Неопределенность заложена в самом факте, действительно ли Джон находится в Париже.
Теория возможностей является одним из направлений в нечеткой логике, в котором рассматриваются точно сформулированные вопросы, базирующиеся на неточных знаниях. В этом разделе вы познакомитесь только с основными идеями этой теории. Лучше всего это сделать на примере.
Предположим, что в ящике находится 1 0 шаров, но известно, что только несколько из них красных. Какова вероятность того, что на удачу из ящика будет вынут красный шар?
Просто вычислить искомое значение, основываясь на знаниях, что только несколько шаров красные (red), нельзя. Тем не менее для каждого значения X из P(RED) в диапазоне [0,1] можно следующим образом вычислить возможность, что P(RED) = Х.
Во-первых, определим "несколько" (several) как нечеткое множество, например, так:
fSEVERAL = {(3, 0.2), (4, 0.6), (5, 1.0), (6, 1.0), (7, 0.6), (8, 0.3)} .
Теперь распределение возможностей для P(RED) представляется формулой
fP(RED) = SEVERAL / 10,
которая после подстановки дает
{(0.3, 0.2), (0.4, 0.6), (0.5, 1.0), (0.6, 1.0), (0.7, 0.6), (0.8, 0.3)}.
Полагая, что почти любое понятие может быть областью определения такой функции, естественно ввести в обиход и понятие "нечеткое значение правдоподобия". Мы часто оцениваем некоторое утверждение как "очень правдоподобное" или "частично правдоподобное". Таким образом, можно представить себе нечеткое множество
ftrue-: [0 , 1]-> [0, 1],
TRUE(FASR-CAR(Porsche-944)) = 1
даже при FASR-CAR(Porsche-944) = 0.9, поскольку (0.9, 1.0)~ftrue Это означает, что любое предположение относительно значения 0.9 рассматривается как "достаточно правдоподобное". Таким образом, можно с уверенностью сказать, что Porsche-944 является быстрым автомобилем, несмотря на то, что на рынке есть и более скоростные.
Сомнительность и возможность
9.3. Сомнительность и возможность
Помимо использования коэффициентов уверенности, в литературе описаны и иные подходы, альтернативные вероятностному. В частности, много внимания уделяется нечеткой логике (fuzzy logic) и теории функций доверия (belieffunctions). О функциях доверия мы поговорим в главе 21, а в данном разделе читатель познакомится с основными аспектами нечеткой логики. Будет показано, почему подход, основанный на идеях нечеткой логики, в последнее время все шире используется при создании экспертных систем.
Неопределенное состояние проблемы неопределенности
9.4. Неопределенное состояние проблемы неопределенности
Одно из главных достоинств формализма нечеткой логики в применении к экспертным системам состоит в возможности комбинирования его логических операторов. Ранее мы уже отмечали, что для правила MYCIN
ЕСЛИ
пациент имеет показания и симптомы s1 ^ ... ^ sk и
ТО можно с уверенностью т заключить, что пациент страдает заболеванием di
P(s1 | s2 ^.. ,^ sk )P(s2 | s3 ^.. .^ sk )... P(sk)
Такая операция в худшем случае требует вычисления k-1 оценки вероятностей свыше тех, что необходимы для si.
Было также показано, что в MYCIN конъюнкция интерпретируется как оператор нечеткой логики, — при этом вычисляется min (s1^ ...^ sk). Это может иногда привести к результатам, полностью противоположным тем, которые следуют из теории вероятностей. Прк сравнении результатов, полученных с помощью различных методов обработки неопределенности в практических системах, были найдены и другие примеры ошибочных выводов, Это сравнение показало, что методы, основанные на нечеткой логике, менее надежны, чем те, которые используют Байесовский подход (см., например, [Wise and Henrion, 1986]).
С другой стороны, нелишне отметить, что человеку также не свойственно строить суждения на основе Байесовского подхода. Исследования Канемана и Тверского показали, что люди склонны не принимать во внимание прежний опыт и отдавать предпочтение более свежей информации [Kahneman and Tversky, 1972]. Некоторые исследователи полагают, что людям свойственно переоценивать свою компетентность (см., например, статьи в сборнике [Kahneman et al, 1982]), причем большинство имеют слабое представление о теории оценок [Tversky and Kahneman, 1974].
Частично привлекательность нечеткой логики для проектировщиков экспертных систем состоит в ее близости к естественному языку. Таким терминам, как "быстрый", "немного", "правдоподобно", чаще всего дается интерпретация на основе повседневного опыта и интуиции. Это упрощает процесс инженерии знаний, поскольку подобные суждения человека-эксперта можно непосредственно преобразовать в выражения нечеткой логики.
Мы еще вернемся к нечеткой логике в главе 21. Здесь же были изложены только основные идеи, чтобы читатель мог получить первое представление о концепции неопределенности знаний и данных и связанных с этим проблемах. Но даже из этого краткого изложения ясно, что предстоит еще очень много сделать для того, чтобы иметь полное понятие об адекватном представлении неопределенности в технических системах.
Представление неопределенности знаний и данных
ГЛАВА 9. Представление неопределенности знаний и данных 9.1. Источники неопределенности 9.2. Экспертные системы и теория вероятностей 9.2.1. Условная вероятность 9.2.2. Коэффициенты уверенности 9.2.3. Коэффициенты уверенности и условные вероятности 9.3. Сомнительность и возможность 9.3.1. Нечеткие множества 9.3.2. Нечеткая логика 9.3.3. Теория возможности 9.4. Неопределенное состояние проблемы неопределенности Рекомендуемая литература Упражнения
Нечеткое множество "быстрых" автомобилей
Нечеткое множество "быстрых" автомобилей

Популяции, позволяющие использовать P(d | е; = P(d| h)P(h| z)
Популяции, позволяющие использовать P(d | е; = P(d| h)P(h| z)
Адаме пришел к выводу, что успех практического применения системы MYCIN и других подобных систем объясняется тем, что в них используются довольно короткие последовательности комбинирования правил, а рассматриваемые гипотезы довольно просты.
Другое критическое замечание относительно MYCIN было высказано Горвицем и Гекерманом и касается использования коэффициентов уверенности в качестве меры изменения доверия, в то время как в действительности они устанавливаются экспертами в качестве степени абсолютного доверия [Horvitz and Heckerman, 1986]. Связывая коэффициенты доверия с правилами, эксперт отвечает на вопрос: "Насколько вы уверены в правдоподобности того или иного заключения?" При применении в MYCIN функций комбинирования дополнительных признаков эти коэффициенты становятся мерой обновления степени доверия, что приводит к несовместимости этих значений с теоремой Байеса.
Представление неопределенности знаний и данных
Представление неопределенности знаний и данных
9.1. Источники неопределенности
9.2. Экспертные системы и теория вероятностей
9.3. Сомнительность и возможность
9.4. Неопределенное состояние проблемы неопределенности Рекомендуемая литература
Упражнения
Во многих реальных приложениях приходится сталкиваться с ситуацией, когда автоматический решатель задач имеет дело с неточной информацией. В этой главе мы рассмотрим основные идеи, касающиеся количественной оценки неопределенности и методов формирования нечетких суждений. В главах 11-15 будет продемонстрировано, как такие методы используются на практике. В настоящей главе речь пойдет в основном о теоретических аспектах представления неопределенности и о том, почему в исследованиях по искусственному интеллекту такое большое внимание уделяется этим проблемам. В главе 21 мы вновь вернемся к проблеме неопределенности и рассмотрим ее более глубоко, но для большинства читателей вполне достаточно будет и тех сведений, которые представлены в данной главе.
Рекомендуемая литература
Рекомендуемая литература
Подробное изложение методики применения коэффициентов уверенности в системе MYCIN читатель найдет в части 4 книги Бучанана и Шортлиффа [Buchanan and Shartliffe, 1984]. В этой же книге воспроизведена критическая статься Адамса. В сборнике [Mamdani and Games, 1981] собраны статьи зачинателей теории нечеткой логики. Книга Санфорда [Sanford, 1987] содержит популярное изложение исследований в области психологических аспектов теории возможностей.
Наиболее свежие работы в области нечеткой логики опубликованы в сборниках [Baldwin, 1996], [Dubois et al, 1996], [Jamshidi et al., 1997]. В книге [Walker and Nguyen, 1996] представлен вводный курс нечеткой логики, а в книге [Yager and Filev, 1994] описано применение идей нечеткой логики в моделировании и управлении. Книга [McNeill and Freiberger, 1993] предназначена для читателей-неспециалистов и содержит описание истории нечетких суждений, сопровождаемое множеством анекдотов и исторических фактов.
Какова вероятность того, что из
Упражнения
1. Какова вероятность того, что из полной колоды будет вытянута одна из старших карт (король, дама или валет)?
2. Какова вероятность того, что в каждом из двух последовательных бросаний игральной кости выпадет число больше трех?
3. Предположим, что вероятность отказа одного из двигателей трехмоторного самолета равна 0.01. Какова вероятность того, что откажут все три двигателя, если считать, что работоспособность одного двигателя не зависит от состояния двух других?
4. Какова вероятность того, что в примере упр. 3 откажут все три двигателя, если отказаться от предположения о независимости состояния двигателей, а использовать приведенные ниже значения условных вероятностей?
Р(отказ_двиг_1 | отказ_двиг_2 v отказ _двиг_3) =0.4
Р(отказ_двиг_2 | отказ_двиг_1 v отказ_двиг_3) = 0.3
Р(отказ_двиг_3 | отказ_двиг_1 v отказ_двиг_2) = 0.2
Р(отказ_двиг_1 отказ_двиг_2 v отказ_двиг_3) = 0.9
Р(отказ_двиг_2 | отказ_двиг_1 v отказ_двиг_3) = 0.8
Р(отказ_двиг_3 | отказ_двиг_1 v отказ_двиг_2) = 0.7
5. Положим, что Р(ртказ_трех_двиг | диверсия) = 0.9, а вероятность отказа любого отдельного двигателя, как и ранее, равна 0.01. Используя условные вероятности, представленные в упр. 4, определите, какова вероятность того, что была совершена диверсия, если известно, что отказали все три двигателя.
6. Поясните, в чем состоит отличие между частотной и субъективистской интерпретацией вероятности.
7. Почему во многих экспертных системах для вычисления степени уверенности в сделанном заключении не используется правило Байеса?
8. Какие проблемы могут появиться при использовании следующей пары правил системы MYCIN? Какие особенности структуры управления в MYCIN усугубляют ситуацию?
если Е1, то Н c уверенностью +0.5, если Е1 и £2, то Н с уверенностью -0.5.
Как следует скорректировать данные правила, чтобы избежать появления этих проблем?
9. Предположим, что понятие "немного" определено как нечеткое множество:
fНЕМНОГО = {(3, 0.8), (4, 0.7), (5, 0.6), (6, 0.5), (7, 0.4), (8, 0.3)}.
В ящике находится 15 шаров и известно, что немногие из них синего цвета. Какова вероятность того, что наудачу из ящика будет вынут именно синий шар?
10. Предположим, что понятие "необычная оценка из десяти" определено как нечеткое множество:
fНЕОБЫЧНО = {(0, 1.0), (1, 0.9), (2, 0.7), (3, 0.5), (4, 0.3), (5, 0.1),
(6, 0.1), (7, 0.3), (8, 0.5), (9, 0.9), (10, 0.9)},
а понятие "высокая оценка из десяти" определено как нечеткое множество
f ВЫСОКАЯ= {(0, 0), (1, 0), (2, 0), (3, 0.1), (4, 0.2), (5, 0.3),
(6, 0.4), (7, 0.6), (8, 0.7), (9, 0.8), (10, 1.0)}.
Постройте составную функцию "необыкновенно высокая оценка из десяти".
