Параметры квитирования
Протоколы, работающие с установлением соединения, обычно следят за корректностью доставки пакетов получателю и организуют повторные передачи искаженных или утерянных пакетов. В рамках соединения правильность передачи каждого пакета должна подтверждаться квитанцией получателя. Квитирование - это один из традиционных методов обеспечения надежной связи. Идея квитирования состоит в следующем.
Для того, чтобы можно было организовать повторную передачу искаженных данных отправитель нумерует отправляемые единицы передаваемых данных - пакеты. Для каждого пакета отправитель ожидает от приемника так называемую положительную квитанцию - служебное сообщение, извещающее о том, что исходный пакет был получен и данные в нем оказались корректными. Время этого ожидания ограничено - при отправке каждого пакета передатчик запускает таймер, и если по его истечению положительная квитанция не получена, то пакет считается утерянным. В некоторых протоколах приемник, в случае получения пакета с искаженными данными, должен отправить отрицательную квитанцию - явное указание того, что данный пакет нужно передать повторно.
Существуют два подхода к организации процесса обмена положительными и отрицательными квитанциями: с простоями и с организацией "окна".
Метод с простоями требует, чтобы источник, пославший кадр, ожидал получения квитанции (положительной или отрицательной) от приемника и только после этого посылал следующий кадр (или повторял искаженный). Из рисунка 2.5 видно, что в этом случае производительность обмена данными существенно снижается - хотя передатчик и мог бы послать следующий кадр сразу же после отправки предыдущего, он обязан ждать прихода квитанции.

Рис. 2.5. Реализация квитирования с простоями приемника
Снижение производительности для этого метода коррекции особенно заметно на низкоскоростных каналах связи, то есть в территориальных сетях.
Метод обмена квитанциями с простоями имеет один параметр - величину тайм-аута ожидания квитанции. При отправке очередного пакета взводится таймер ожидания квитанции и, если установленный тайм-аут истек, а квитанция не пришла, то пакет или квитанции считаются утерянными и оранизуется вторичная передача неподтвержденного пакета (рис. 2.6).

Рис. 2.6. Влияние тайм-аута на работу протокола
Величина тайм-аута - это основной параметр настройки протоколов, работающих в соотвествии с алгоритмом протоев источника. Слишком маленькие значения тайм-аута могут вызвать нежелательное снижение пропускной способности. Это может произойти в большой составной сети, в которой работают перегруженные маршрутизаторы, медленно обрабатывающие потоки пакетов. Если задержки передачи пакетов превзойдут значение тайм-аута, то исходный узел будет повторно передавать пакеты, которые на самом деле не были потеряны, а просто слишком медленно шли до узла назначения.
При выборе величины тайм-аута должны учитываться скорость и надежность физических линий связи, их протяженность и многие другие подобные факторы. В протоколе TCP, например, тайм-аут определяется с помощью достаточно сложного адаптивного алгоритма, идея которого состоит в следующем. При каждой передаче засекается время от момента отправки сегмента до прихода квитанции о его приеме (время оборота). Получаемые значения времен оборота усредняются с весовыми коэффициентами, возрастающими от предыдущего замера к последующему. Это делается с тем, чтобы усилить влияние последних замеров. В качестве тайм-аута выбирается среднее время оборота, умноженное на некоторый коэффициент. Практика показывает, что значение этого коэффициента должно превышать 2. В сетях с большим разбросом времени оборота при выборе тайм-аута учитывается и дисперсия этой величины.
При больших значениях тайм-аута потери времени, ушедшего на ожидание квитанции, могут быть слишком большими и пропускная способность сети может снизиться в десятки раз.
Рассмотрим пример, иллюстрирующий возможное снижение пропускной способности сети NovellNetWare из-за слишком большого значения тайм-аута времени ожидания квитанций.
Клиент и сервер NetWare по умолчанию используют алгоритм квитирования с простоями при организации передачи файлов. Если на сервере и клиенте работает стек IPX/SPX, то протокол прикладного уровня NCP, отвечающий за файловый сервис, не использует для транспортировки своих сообщений протокол SPX, работающий с установлением соединения, а обращается непосредственно к протоколу IPX.
Это делается для ускорения работы файлового сервиса, так как использование каждого дополнительного уровня в стеке протоколов снижает общую производительность стека.
Протокол IPX - это протокол дейтаграммного типа, который повторную передачу искаженных и утернных пакетов не выполняет. В результате при утере или искажении данных в локальной сети, где на нижнем уровне также работают протоколы дейтаграммного типа (Ethernet, TokenRing и т.п.), повторная передача пакетов организуется только протоколом NCP, который работает по алгоритму квитирования с простоем источника. По умолчанию протокол NCP использует тайм-аут в 0.5 секунды, после истечения которого выполняется повторная передача пакета, на который не пришла квитанция.
Рассмотрим на примере, насколько может снизиться пропускная способность сети NetWare при значении тайм-аута в 0.5 секунды и уровне потерянных и искаженных пакетов всего в 3%.
На рисунке 2.7 показаны временные диаграммы передачи файла между сервером и клиентом в двух случаях - при идеально работающей сети, когда пакеты не искажаются и не теряются, и в сети с 3% уровнем утерянных и искаженных пакетов.
Пусть в обоих случаях между клиентом и сервером передается файл размером в 240 000 байт. Файл передается с помощью протокола IPX со служебным заголовком в 30 байт и протокола Ethernet с размером служебного заголовка в 26 байт (с учетом преамбулы). Размер служебного заголовка самого протокола NCP составляет 20 байт.
Пусть файл передается частями по 1000 байт. Всего для передачи файла потребуется 240 пакетов.
Размер кадра Ethernet, переносящего 1000 байт передаваемого файла, составит 1000+20+30+26 = 1076 байт или 8608 бит.
Размер квитанции NCP, которая подтверждает получение пакета, равен 10 байтам, что дает размер кадра Ethernet, переносящего квитанцию в 86 байт (вместе с преамбулой) или 688 бит.
Предположим, что время обработки одного пакета на клиентской стороне составляет 650 мкс, а на сервере - 50 мкс.
В этих условиях время одного цикла передачи очередной части файла в идеальной сети составит 860.8 + 68.8 +650 + 50 = 1629.6 мкс.
Общее время передачи файла в 240 000 байт составит при этом 240х1629.6 = 0.391 секунды, а эффективная пропускная способность сети - 240000/0.391 = 613810 байт/с или 4.92 Мб/c.
При потере (независимо от причины) 3% кадров Ethernet повторная передача кадра начинается только после истечения тайм-аута в 0.5 сек. Всего таких случаев за время передачи файла будет 240х0.03 = 7. Следовательно, время передачи файла возрастет на 7х0.5 = 3.5 сек, а общее время передачи файла составит 0.391 + 3.5 = 3.891 сек. Пропускная способность сети при этом становится равной 240000/3.891 = 61680 байт/c или 0.49 Мб/c.
Таким образом, при наличии в сети NetWare всего 3% потерянных или искаженных пакетов пропускная способность этой сети снижается в 10 раз.

Рис. 2.7. Влияние потерь пакетов на производительность сети
Во втором методе - методе скользящего окна - для повышения коэффициента использования линии источнику разрешается передать некоторое количество пакетов в непрерывном режиме, то есть в максимально возможном для источника темпе, без получения на эти пакеты ответных квитанций (рис. 2.8).

Рис. 2.8. Квитирование с передачей "неподтвержденных" пакетов
Количество пакетов, которые разрешается передавать таким образом, называется размером окна. Рисунок 2.9 иллюстрирует данный метод для размера окна в 8 пакетов.

Рис. 2.9. Обмен квитанциями в режиме окна
Этот алгоритм называют алгоритмом скользящего окна. Действительно, при каждом получении квитанции окно перемещается (скользит), захватывая новые данные, которые разрешается передавать без подтверждения.
Алгоритм скользящего окна имеет два настраиваемых параметра - размер окна и время тайм-аута ожидания прихода квитанции. Оба параметра влияют на пропускную способность сети. В сетях с редкими искажениями и потерями пакетов целесообразно устанавливать большие значения окна и тайм-аута, в ненадежных сетях нужно работать с меньшими значениями как окна, так и тайм-аута.
Многие протоколы используют механизм скользящего окна для повышения своей пропускной способности.
К ним относятся такие популярные протоколы как LAP-B, LAP-D и LAP-M семейства HDLC, используемые в территориальных сетях, протокол V.42, работающий в современных модемах, протоколы SPX , TCP и многие протоколы прикладного уровня.
Особенность реализации алгоритма квитирования в протоколе TCP состоит в том, что хотя единицей передаваемых данных у протокола TCP является сегмент (другое название пакета), окно определено на множестве нумерованных байт неструктурированного потока данных, поступающих с верхнего уровня и буферизуемых протоколом TCP.
В качестве квитанции получатель сегмента отсылает ответное сообщение (сегмент), в которое помещает число, на единицу превышающее максимальный номер байта в полученном сегменте. Если размер окна равен W, а последняя квитанция содержала значение N, то отправитель может посылать новые сегменты до тех пор, пока в очередной сегмент не попадет байт с номером N+W. Этот сегмент выходит за рамки окна, и передачу в таком случае необходимо приостановить до прихода следующей квитанции.
Особенностью протокола TCP является также адаптивное изменение величины окна. В подавляющем большинстве других протоколов размер окна устанавливается администратором и самим протоколом в процессе его работы не изменяется. Варьируя величину окна, можно повлиять на загрузку сети. Чем больше окно, тем большую порцию неподтвержденных данных можно послать в сеть. Если сеть не справляется с нагрузкой, то возникают очереди в промежуточных узлах-маршрутизаторах и в конечных узлах-компьютерах.
При переполнении приемного буфера конечного узла "перегруженный" протокол TCP, отправляя квитанцию, помещает в нее новый, уменьшенный размер окна. Если он совсем отказывается от приема, то в квитанции указывается окно нулевого размера. Однако даже после этого приложение может послать сообщение на отказавшийся от приема порт. Для этого, сообщение должно сопровождаться пометкой "срочно". В такой ситуации порт обязан принять сегмент, даже если для этого придется вытеснить из буфера уже находящиеся там данные.
После приема квитанции с нулевым значением окна протокол-отправитель время от времени делает контрольные попытки продолжить обмен данными. Если протокол-приемник уже готов принимать информацию, то в ответ на контрольный запрос он посылает квитанцию с указанием ненулевого размера окна.
Другим проявлением перегрузки сети является переполнение буферов в маршрутизаторах. В таких случаях они могут централизовано изменить размер окна, посылая управляющие сообщения некоторым конечным узлам, что позволяет им дифференцированно управлять интенсивностью потока данных в разных частях сети.
Параметры оптимизации транспортной подсистемы
На выбранный критерий оптимизации сети влияет большое количество параметров различных типов. В наибольшей степени на производительность сети влияют:
используемые коммуникационные протоколы и их параметры; доля и характер широковещательного трафика, создаваемого различными протоколами; топология сети и используемое коммуникационное оборудование; интенсивность возникновения и харакетр ошибочных ситуаций; конфигурация программного и аппаратного обеспечения конечных узлов.
Поддержка широковещательного трафика на канальном уровне
Практически все протоколы, используемые в локальных сетях, поддерживают широковещательные адреса (кроме протоколов АТМ). Адрес, состоящий из всех единиц (111...1111), имеет один и тот же смысл для протоколов Ethernet, TokenRing, FDDI, FastEthernet, 100VG-AnyLAN: кадр с таким адресом должен быть принят всеми узлами сети. Ввиду особого вида и регулярного характера широковещательного адреса вероятность его генерации в результате ошибочной работы аппаратуры (сетевого адаптера, повторителя, моста, коммутатора или маршрутизатора) оказывается достаточно высокой. Иногда ошибочный широковещательный трафик генерируется в результате неверной работы программного обеспечения, реализующего функции протоколов верхних уровней.
Широковещательный трафик канального уровня распространяется в пределах не только сегмента, образованного пассивной кабельной системой или несколькими повторителями/концентраторами, но и в пределах сети, построенной с использованием мостов и коммутаторов. Принципы работы этих устройств обязывают их передавать кадр с широковещательным адресом на все порты, кроме того, откуда этот кадр пришел. Такой способ обработки широковещательного трафика создает для всех узлов, связанных друг с другом с помощью повторителей, мостов и коммутаторов, эффект общей сети, в которой все клиенты и серверы "видят" друг друга.
Поддержка широковещательного трафика на сетевом уровне
Как уже было сказано, мосты и коммутаторы не изолируют сегменты сетей, подключенных к портам, от широковещательного трафика канальных протоколов. Это может создавать проблемы для больших сетей, так как широковещательный шторм будет "затапливать" всю сеть и блокировать нормальную работу узлов. Надежной преградой на пути широковещательного шторма являются маршрутизаторы.
Принципы работы маршрутизатора не требуют от него обязательной передачи кадров с широковещательным адресом через все порты. Маршрутизатор при принятии решения о продвижении кадра руководствуется информацией заголовка не канального уровня, а сетевого. Поэтому широковещательные адреса канального уровня маршрутизаторами просто игнорируются. На сетевом уровне также существует понятие широковещательного адреса, но этот адрес имеет ограниченное действие - пакеты с этим адресом должны быть доставлены всем узлам, но только в пределах одной сети. В силу этого такие адреса называются ограниченными широковещательными адресами (limitedbroadcast). По таким правилам работают наиболее популярные протоколы сетевого уровня IP и IPX.
Однако, для нормальной работы сети часто оказывается желательной возможность широковещательной передачи пакетов некоторого типа в пределах всей составной сети. Например, пакеты протокола объявления сервисов SAP в сетях NetWare требуется передавать и между сетями, соединенными маршрутизаторами, для того, чтобы клиенты могли обращаться к серверам, находящимся в других сетях. Именно так работает программное обеспечение маршрутизации, реализованное компанией Novell в ОС NetWare. Для поддержания этого свойства практически все производители аппаратных маршрутизаторов также обеспечивают широковещательную передачу трафика SAP.
Подобные исключения делаются не только для протокола SAP, но и для многих других служебных протоколов, выполняющих функции автоматического поиска сервисов в сети или же другие не менее полезные функции, упрощающие работу сети.
Ниже описаны наиболее популярные в локальных сетях протоколы, порождающие широковещательный трафик.
Показатели надежности и отказоустойчивости
Важнейшей характеристикой вычислительной сети является надежность - способность правильно функционировать в течение продолжительного периода времени. Это свойство имеет три составляющих: собственно надежность, готовность и удобство обслуживания.
Повышение надежности заключается в предотвращении неисправностей, отказов и сбоев за счет применения электронных схем и компонентов с высокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечения тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Надежность измеряется интенсивностью отказов и средним временем наработки на отказ. Надежность сетей как распределенных систем во многом определяется надежностью кабельных систем и коммутационной аппаратуры - разъемов, кроссовых панелей, коммутационных шкафов и т.п., обеспечивающих собственно электрическую или оптическую связность отдельных узлов между собой.
Повышение готовностипредполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления циркуляции информации в сети после обнаружения неисправности. Повышение готовности представляет собой борьбу за снижение времени простоя системы.
Критерием оценки готовности является коэффициент готовности, который равен доле времени пребывания системы в работоспособном состоянии и может интерпретироваться как вероятность нахождения системы в работоспособном состоянии. Коэффициент готовности вычисляется как отношение среднего времени наработки на отказ к сумме этой же величины и среднего времени восстановления. Системы с высокой готовностью называют также отказоустойчивыми.
Основным способом повышения готовности является избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Вычислительные сети включают большое количество элементов различных типов, и для обеспечения отказоустойчивости необходима избыточность по каждому из ключевых элементов сети.
Существуют различные градации отказоустойчивых компьютерных систем, к которым относятся и вычислительные сети. Приведем несколько общепринятых определений:
высокая готовность (highavailability) - характеризует системы, выполненные по обычной компьютерной технологии, использующие избыточные аппаратные и программные средства и допускающие время восстановления в интервале от 2 до 20 минут; устойчивость к отказам (faulttolerance) - характеристика таких систем, которые имеют в горячем резерве избыточную аппаратуру для всех функциональных блоков, включая процессоры, источники питания, подсистемы ввода/вывода, подсистемы дисковой памяти, причем время восстановления при отказе не превышает одной секунды; непрерывная готовность (continuousavailability) - это свойство систем, которые также обеспечивают время восстановления в пределах одной секунды, но в отличие от систем устойчивых к отказам, системы непрерывной готовности устраняют не только простои, возникшие в результате отказов, но и плановые простои, связанные с модернизацией или обслуживанием системы. Все эти работы проводятся в режиме online. Дополнительным требованием к системам непрерывной готовности является отсутствие деградации, то есть система должна поддерживать постоянный уровень функциональных возможностей и производительности независимо от возникновения отказов.
Так как сети обслуживают одновременно большое количество пользователей, то при расчете коэффициента готовности необходимо учитывать это обстоятельство. Коэффициент готовности сети должен соответствовать доле времени, в течение которого сеть выполняла с должным качеством свои функции для всех пользователей. Очевидно, что в больших сетях очень трудно обеспечить значения коэффициента готовности, близкие к единице.
Между показателями производительности и надежности сети существует тесная связь. Ненадежная работа сети очень часто приводит к существенному снижению ее производительности. Это объясняется тем, что сбои и отказы каналов связи и коммуникационного оборудования приводят к потере или искажению некоторой части пакетов, в результате чего коммуникационные протоколы вынуждены организовывать повторную передачу утерянных данных.Так как в локальных сетях восстановлением утерянных данных занимаются как правило протоколы транспортного или прикладного уровня, работающие с тайм-аутами в несколько десятков секунд, то потери производительности из-за низкой надежности сети могут составлять сотни процентов.
|
Понятие "узкое место"
Выполнение вычислительной задачи может потребовать участия в работе нескольких устройств. Каждое устройство использует определенные ресурсы для выполнения своей части работы. Плохая производительность обычно является следствием того, что одно из устройств требует намного больше ресурсов, чем остальные. Чтобы исправить положение, администратор должен выявить устройство, которое требует наибольшей доли времени выполнения задачи. Такое устройство, которое требует наибольшей доли времени выполнения задачи, называется узким местом (bottleneck). Например, если на выполнение задачи требуется 3 секунды, и 1 секунда тратится на выполнение программы процессором, а 2 секунды - на чтение данных с диска, то диск является узким местом.
Определение узкого места - это критический этап в процессе улучшения производительности. Замена процессора в предыдущем примере на другой, в 2 раза более быстродействующий процессор, уменьшит общее время выполнения задачи только до 2.5 секунд, но существенно исправить ситуацию не сможет, так как мы не устраним этим узкое место. Если же мы купим диск и контроллер диска, которые будут быстрее прежних в 2 раза, то общее время уменьшится до 2 секунд.
В процессе оптимизации операционных систем администратор может воспользоваться различным инструментарием - программными и аппаратными измерителями. Многие операционные системы имеют встроенные или специально разработанные для них программные системы мониторинга. Примером такой системы является PerformanceMonitor - средство анализа производительности ОС WindowsNT компании Microsoft.
Рассмотрим некоторые типовые процедуры оптимизации операционной системы на примере WindowsNT с помощью утилиты PerformanceMonitor.
Портативные анализаторы
Портативный вариант анализатора, почти аналогичный по своим возможностям DSS, реализован в продуктах серии ExpertSnifferAnalyzer (ESA), известный также как TurboSnifferAnalyzer. При значительно меньшей, чем продукты серии DSS, стоимости, ESA предоставляют администратору те же возможности, что и полномасштабная DSS, но только для того сегмента сети, к которой ESA подключен в данный момент. Существующие версии обеспечивают полный анализ, интерпретацию протоколов, а так же мониторинг подключенного сегмента сети или линии межсегментной связи. При этом поддерживаются все те же сетевые топологии, что и для систем DSS. Как правило, ESA используются для периодической проверки некритичных сегментов сети, на которых нецелесообразно постоянно использовать агент-анализатор.
Существует и еще более компактная версия анализатора - NotebookSnifferAnalyzer (NSA), реализованный на базе портативного компьютера класса notebook, специальной карты стандарта PCMCIA Туре II и программного обеспечения, аналогичного продуктам серии ESA с возможностью подсчета числа коллизий. Способен выполнять все функции по анализу сетей на базе Ethernet и TokenRing. Является хорошим решением для активно перемещающегося специалиста, использующего notebook в качестве портативного компьютера общего назначения.
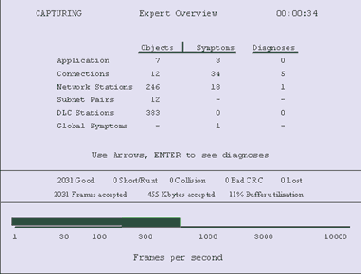
Рис. 3.3. ExpertAnalysis
Относительно недавно вышла более "облегченная" версия NotebookSnifferAnalyzer - NotebookSnifferAnalyzerLite, обладающая всеми возможностями полноценного NotebookSnifferAnalyzer, но только в отношении сетевых сред на базе NovellNetware, включая версию 4.х.
Построение пилотных проектов проектируемых сетей
Если для задания информации о топологии сети не нужно иметь реальную сеть, то для сбора исходных данных о интенсивности источников сетевого трафика могут потребоваться измерения на пилотных сетях, представляющих собой натурную модель проектируемой сети. Эти измерения могут быть выполнены различными средствами, в том числе и с помощью анализаторов протоколов.
Помимо получения исходных данных для имитационного моделирования пилотная сеть может использоваться для решения самостоятельных важных задач. Она может дать ответы на вопросы, касающиеся принципиальной работоспособности того или иного технического решения или совместимости оборудования. Натурные эксперименты могут потребовать значительных материальных затрат, но они компенсируются высокой достоверностью полученных результатов.
Пилотная сеть должна быть как можно более похожа на ту сеть, которая создается, для выбора параметров которой и создается пилотная сеть. Для этого необходимо в первую очередь выделить те особенности создаваемой сети, которые могут оказать наибольшее влияние на ее работоспособность и производительность.
Если имеются сомнения в совместимости продуктов разных производителей, например, коммутаторов, поддерживающих виртуальные сети или другие пока не стандартизованные возможности, то в пилотной сети должны проверяться на совместимость именно эти устройства и именно в тех режимах, которые вызывают наибольшие сомнения.
Что же касается использования пилотной сети для прогнозирования пропускной способности реальной сети, то здесь возможности этого вида моделирования весьма ограничены. Сама по себе пилотная сеть вряд ли сможет дать хорошую оценку производительности сети, включающей гораздо больше узлов подсетей и пользователей, так как не ясен способ экстраполяции результатов, полученных в небольшой сети, на сеть гораздо больших размеров.
Поэтому пилотную сеть целесообразно использовать в данном случае совместно с имитационной моделью, которая может использовать образцы трафика, задержек и пропускной способности устройств, полученных в пилотной сети, для задания характеристик моделей частей реальной сети. Затем, эти частные модели могут быть объединены в полную модель создаваемой сети, работа которой будет имитироваться.
|
Потери пакетов и квитанций
Регулярные потери пакетов или кадров могут иметь очень тяжелые последствия для локальных сетей, так как протоколы нижнего уровня (канальные протоколы) рассчитаны на качественные кабельные каналы связи и работают поэтому в дейтаграммном режиме, оставляя работу по восстановлению потерянных пакетов протоколам верхнего уровня.
К значительному снижению производительности могут приводить также потери служебных сообщений - квитанций подтверждения доставки, сообщений типа keepalive и т.п. Обычно протоколы более чувствительны к подобным потерям и даже разовые ситуации подобного рода могут вызывать серьезные последствия. Это легко объясняется особым значением для протокола служебной информации.
Примером может служить протокол NCP в режиме burstmode, когда положительная квитанция посылается не на каждый пакет, а на целую пачку пакетов. Если пакеты из этой пачки с пользовательскими данными дошли благополучно, а квитанция по доставке по каким-то причинам была искажена и тем самым отброшена передающим узлом, то этот узел по истечении тайм-аута повторно пошлет большую порцию информации, содержащейся в данной пачке. Повторные передачи пакетов могут существенно снизить полезную пропускную способность сети.
Представление результатов
Графики и отчеты
COMNETIII позволяет при моделировании задавать форму отчета о результатах для каждого отдельного элемента модели. Для этого необходимо в пункте меню Report выбрать требуемый элемент (пункт подменю networkelement) и задать для него опреленный тип отчета (пункт typeofreport).
Отчет генерируется каждый раз при запуске определенной модели. Отчет представлен в стандартной текстовой форме, имеющей ширину в 80 символов, и его легко можно распечатать на любом принтере.
Можно задать генерацию нескольких отчетов разного типа для каждого элемента сети.
Существуют другие способы получения статистических результатов прогона модели, кроме отчетов. В COMNETIII имеются кнопки Statistics, с помощью которых можно включить сбор статистики для каждого типа элемента модели - узлов, каналов, источников трафика, маршрутизаторов, коммутаторов и т.п. Монитор статистики каждого элемента можно установить для сбора только базовых статистических параметров (минимум, масимум, среднее значение и дисперсия) или же сбора данных во временном масштабе для построения графиков.
Если результаты наблюдений сохранены в файле для последующего построения графиков и анализа, то возможно также построение гистограмм и процентных показателей. Возможно построение графиков и во время моделирования.
Мультипликация и отслеживание событий
Перед моделированием или во время него можно установить режимы мультипликации и трассировки событий с помощью пунктов меню Animation иTrace.
Параметры менюAnimationпозволяют изменять скорость тактов моделирования и скорость предвижения токенов - графических символов, соответствующих кадрам и пакетам. В анимационном режиме система COMNETIII показывает поступление токенов в каналы связи и выход их из каналов, текущее количество пакетов в узлах, количество сессий, установленых с данным узлом, процент использования и многое другое.
В режиме трассировки можно отображать процесс наступления событий в модели либо в файл, либо на экран. При отображении на экран можно перейти в режим пошагового моделирования, когда очередное событие в модели наступает и отображается только при очередном нажатии на соответствующую кнопку графического интерфейса. Можно задать уровень отслеживаемых событий - от высокоурвневых событий, связанных с работой приложений до событий самого низкого уровня, связанных с обработкой кадров на канальном уровне.
Статистический анализ
COMNETIII включает интегрированный набор средств для статистического анализа исходных данных и результатов моделирования. С их помощью можно подобрать подходящее распределение вероятностей для экспериментально полученных данных. Средства анализа результатов позволяют вычислить доверительные интервалы, выполнить регрессионный анализ и оценить вариации оценок, полученных по нескольким прогонам модели.
Превышение значений тайм-аута и несогласованные значения тайм-аутов
Тайм-ауты - очень важные параметры многих протоколов, так как их непредвиденное превышение обычно приводит к серьезным последствиям. Например, превышение тайм-аута может привести к разрыву логического соединения между сервером и клиентом, или же к ненужным повторным передачам данных, которые и так уже благополучно дошли до получателя. Разрыв логического соединения приводит к большим временным потерям, а значит и к значительному снижению пропускной способности сети, так как процедура установления соединения может включать обмен сотнями пакетов, передающих аутентификационную и другую служебную информацию.
Наиболее чувствительным к превышению тайм-аута протоклом канального уровня является протокол SDLC стека SNA компании IBM. Из-за этого к территориальным сетям, передающим трафик SDLC, предъявляются повышенные требования к величине и стабильности времени реакции.
Однако, не только протокол SDLC чувствителен к временным задержкам передачи пакетов. Многие протоколы, работающие в режиме логического соединения, обладают таким свойством. Например, протокол TCP следит за целостностью логического соединения путем установки специального таймера, который устанавливается при прибытии очередного TCP-сообщения. Если таймер истекает раньше, то сессия TCP разрывается, что приводит к разрыву сессии протокола прикладного уровня, например, FTP. Так как протокол FTP не обладает свойством продолжения передачи файла с прерванного места после разрыва и повторного установления соединения, то разрывы сессии TCP могут приводить к тому, что файл объемом в несколько мегабайт, который был передан почти полностью, придется передавать заново. Подобная ситуация иногда встречается в сети Internet, когда загруженность FTP-сервера или маршрутизаторов приводит к значительным задержкам отправки очередного TCP-сообщения. Для предотвращения разрывов в протоколе TCP предусмотрена возможность генерации пакетов keepalive в то время, когда отсутствуют пользовательские данные для передачи, однако этот режим является опциональным и не все реализации стека TCP/IP его поддерживают.
В локальных сетях превышение тайм-аута наблюдается гораздо реже, чем в глобальных, но при большой загрузке сети может также иметь место.
Нестабильный характер проявления ошибок истечения тайм-аутов затрудняет диагностику, так как ошибка проявляется в случайных потерях связи пользователей с серверами и может наблюдаться только в периоды большой нагрузки сети, никак не проявляя себя в остальное время.
К аналогичным последствиям приводят несогласованные значения тайм-аутов у взаимодействующих узлов или коммуникационных устройств. Примером такой несогласованности могут служить разные значения тайм-аута у пограничных маршрутизаторов при спуфинге широковещательного трафика. Другим примером может быть различный период обновления базы маршрутной информации у маршрутизаторов.
Продукты для мониторинга и анализа
3.2.1. Обзор популярных систем управления: HPOpenView, SunSoftSolstice, CabletronSpectrum, IBMNetView
Хорошая платформа для систем управления корпоративными сетями должна обладать следующими качествами:
масштабируемостью, истинной распределенностью в соответствии с концепцией клиент/сервер, открытостью, позволяющей справиться с разнородным - от настольных компьютеров до мейнфреймов - оборудованием.
Первые два свойства тесно связаны. Хорошая масштабируемость достигается за счет распределенности системы управления. Распределенность здесь означает, что система может включать несколько серверов и клиентов. Серверы (называемые также менеджерами) собирают данные о текущем состоянии сети от агентов (SNMP, CMIP или RMON), встроенных в оборудование сети, и накапливают их в своей базе данных. Клиенты представляют собой графические консоли, за которыми работают администраторы сети. Программное обеспечение клиента системы управления принимает запросы на выполнение каких-либо действий от администратора (например, построение подробной карты части сети) и обращается за необходимой информацией к серверу. Если сервер обладает нужной информацией, то он сразу же передает ее клиенту, если нет - то пытается собрать ее от агентов.
Ранние версии систем управления совмещали все функции в одном компьютере, за которым работал администратор. Для небольших сетей или сетей с небольшим количеством управляемого оборудования такая структура оказывается вполне удовлетворительной, но при большом количестве управляемого оборудования единственный компьютер, к которому стекается информация от всех устройств сети, становится узким местом. И сеть не справляется с большим потоком данных, и сам компьютер не успевает их обрабатывать. Кроме того, большой сетью управляет обычно не один администратор, поэтому, кроме нескольких серверов в большой сети должно быть несколько консолей, за которыми работают администраторы сети, причем на каждой консоли должна быть представлена специфическая информация, соответствующая текущим потребностям конкретного администратора.
Поддержка разнородного оборудования - скорее желаемое, чем реально существующее свойство сегодняшних систем управления. К числу наиболее популярных продуктов сетевого управления относятся четыре системы: Spectrum компании CabletronSystems, OpenView фирмы Hewlett-Packard, NetView корпорации IBM и Solstice производства SunSoft - подразделения SunMicrosystems. Три компании из четырех сами выпускают коммуникационное оборудование. Естественно, что система Spectrum лучше всего управляет оборудованием компании Cabletron, OpenView - оборудованием компании Hewlett-Packard, а NetView- оборудованием компании IBM.
При построении карты сети, которая состоит из оборудования других производителей, эти системы начинают ошибаться и принимать одни устройства за другие, а при управлении этими устройствами поддерживают только их основные функции, а многие полезные дополнительные функции, которые отличают данное устройство от остальных, система управления просто не понимает и, поэтому, не может ими воспользоваться.
Для исправления этого недостатка разработчики систем управления включают поддержку не только стандартных баз MIBI, MIBII и RMONMIB, но и многочисленных частных MIB фирм-производителей. Лидер в этой области - система Spectrum, поддерживающая около 1000 баз MIB различных производителей.
Другим способом более качественной поддержки конкретной аппаратуры является использование на основе какой-либо платформы управления приложения той фирмы, которая выпускает это оборудование. Ведущие компании - производители коммуникационного оборудования - разработали и поставляют весьма сложные и многофункциональные системы управления для своего оборудования. К наиболее известным системам этого класса относятся Optivity компании BayNetworks, CiscoWorks компании CiscoSystems, Transcend компании 3Com. Система Optivity, например, позволяет производить мониторинг и управлять сетями, состоящими из маршрутизаторов, коммутаторов и концентраторов компании BayNetwork, полностью используя все их возможности и свойства.
Оборудование других производителей поддерживается на уровне базовых функций управления. Система Optivity работает на платформах OpenView компании Hewlett-Packard и SunNetManager (предшественник Solstice) компании SunSoft. Однако, работа на основе какой-либо платформы управления с несколькими системами, такими как Optivity, слишком сложна и требует, чтобы компьютеры, на которых все это будет работать, обладали очень мощными процессорами и большой оперативной памятью.
Тем не менее, если в сети преобладает оборудование от какого-либо одного производителя, то наличие приложений управления этого производителя для какой-либо популярной платформы управления позволяет администраторам сети успешно решать многие задачи. Поэтому разработчики платформ управления поставляют вместе с ними инструментальные средства, упрощающие разработку приложений, а наличие таких приложений и их количество считаются очень важным фактором при выборе платформы управления.
Открытость платформы управления зависит также от формы хранения собранных данных о состоянии сети. Большинство платформ-лидеров позволяют хранить данные в коммерческих базах данных, таких как Oracle, Ingres или Informix. Использование универсальных СУБД снижает скорость работы системы управления по сравнению с хранением данных в файлах операционной системы, но зато позволяет обрабатывать эти данные любыми приложениями, умеющими работать с этими СУБД.
В следующей таблице представлены наиболее важные характеристики наиболее популярных платформ управления:
| OpenView Network Node Manager 4.1 (Hewlett- Packard) |
Spectrum Enterprise Manager (Cabletron Systems) |
NetView forAIX SNMP Manager (IBM) |
Solstice Enterprise Manager (SunSoft) | |
| Автообнаружение | ||||
| Ограничение по числу промежуточных маршрутизаторов | - | - | + | + |
| Определение имени хоста по его адресу через сервер DNS | + | + | + | + |
| Возможность модификации присвоенного имени хоста | + | - | + | + |
| Распознавание сетевых топологий | Любые сети, работающие по TCP/IP | Ethernet, TokenRing, FDDI, ATM, распределенные сети, сети с коммутацией | распознавание по интерфейсам устройств | Ethernet, TokenRing, FDDI, распределен- ные сети |
| Максимальное рекомендуемое число обслуживаемых узлов | 200 - 2000, наибольшее известное - 35000 | Программных ограничений не существует | Программных ограничений не существует | 10000 - 50000 |
| Поддержка баз данных | Ingres, Oracle | файлы | Собств., Oracle, Sybase, ... | Informix, Oracle, Sybase |
| Распределенное управление | ||||
| Один сервер / | много | клиентов | ||
| число клиентов | до 15 | Нет программного ограничения | Протестиро- вано более 30 | Нет программного ограничения |
| клиент использует X-Window | + | - | - | + |
| система с GUI запускается на клиенте | + | + | + | + |
| собственная карта сети у клиента | + | + | + | - |
| задание доступных для просмотра объектов сети | с помощью дополнительного продукта OperationsCenter (HP) | + | + | - |
| Много серверов / | много | клиентов | ||
| текущее состояние | +/- | +/+ | +/- | +/+ |
| планируется | +/+ | +/+ | +/+ | +/+ |
| Число приложений третьих фирм | 220 | 180 | > 200 | 400 |
| Число поддерживаемых MIB третьих фирм | 218 | > 1000 | 193 | Нет данных |
| Поддержка протокола SNMP: | ||||
| через IP | + | + | + | + |
| через IPX | + | - | - | - |
| Поддержка MIB, утвержденных IETF | Большинство, но нет RMON | Все | 20 | MIB-II |
| Поддержка протокола CMIP | Дополнительно оплачиваемый продукт - Open View HP Distributed Management Platform | Дополнительно оплачиваемый продукт | + | + |
| Взаимодействие с мейнфреймами | При помощи приложений третьих фирм | По SNA через Blue Vision | Может обращаться к NetView на мейнфрейме | + |
| Поддержка ОС | HPUX, SunOS, Solaris | IBM AIX, Sun OS, HP UX, SGI IRIX, Windows NT | AIX, OSF/1, Windows NT | SolarisSPARC |
Продукты мониторинга и анализа сетей компании NetworkGeneral
Продукты, выпускаемые компанией NetworkGeneral, предназначены для работы в трех секторах рынка средств мониторинга и анализа сетей:
Сектор недорогих систем для не очень критичных к сбоям сетей широкого класса. Компания Network General выпускаетдляэтогосекторапродукты Foundation Agent, Foundation Probe, Foundation Manager. Сектор дорогих систем высшего класса, предназначенных для анализа и мониторинга сетей, предъявляющих максимально возможные требования по обеспечению надежности и производительности. Такие системы обычно являются распределенными. В этом секторе позиционируется семейство DistributedSnifferSystem. Сектор переносных систем анализа и мониторинга: NotebookSnifferNetworkAnalyzer и ExpertSnifferNetworkAnalyzer.
Программное конфигурирование сети
В состав Optivity входит приложение LANarchitect, которое существенно упрощает процесс конфигурирования сети. Это приложение работает с устройствами семейств System5000, Distributed 5000 и LattisSwitchSystem 28000 и позволяет приписывать определенные порты, слоты или кластеры портов различным рабочим группам (то есть сегментам или кольцам), вне зависимости от их физического расположения. В результате образуется гибкая, программно управляемая конфигурация сети.
Приложение LANarchitect связано с иконками устройств System 5000, Distributed 5000 и LattisSwitchSystem 28000 на карте сети и при указании на них представляет все рабочие группы, относящиеся к данному устройству в форме каталога файлов. При открытии каталога показываются все порты и кластеры, содержащиеся в данной рабочей группе, и администратор, используя технику drag-and-drop, может добавлять новые порты или кластеры, перемещать их между рабочими группами или создавать новые рабочие группы. При этом создаются новые соединения в управляемых устройствах, которые поддерживаются встроенным в них программным обеспечением, и тем самым исключается потребность физических перекоммутаций в сети.
С помощью компоненты LANarchitect администратор может передать указание модулю управления DCE (DataCollectionEngine), который может устанавливаться в устройствах System 5000 и Distributed 5000, проводить детальный анализ и обработку пакетов в определенных сегментах Ethernet или кольцах TokenRing.
Пропускная способность
Основная задача, для решения которой строится любая сеть - быстрая передача информации между компьютерами. Поэтому критерии, связанные с пропускной способностью сети или части сети, хорошо отражают качество выполнения сетью ее основной функции.
Существует большое количество вариантов определения критериев этого вида, точно также, как и в случае критериев класса "время реакции". Эти варианты могут отличаться друг от друга: выбранной единицей измерения количества передаваемой информации, характером учитываемых данных - только пользовательские или же пользовательские вместе со служебными, количеством точек измерения передаваемого трафика, способом усреднения результатов на сеть в целом. Рассмотрим различные способы построения критерия пропускной способности более подробно.
Критерии, отличающиеся единицей измерения передаваемой информации. В качестве единицы измерения передаваемой информации обычно используются пакеты (или кадры, далее эти термины будут использоваться как синонимы) или биты. Соответственно, пропускная способность измеряется в пакетах в секунду или же в битах в секунду.
Так как вычислительные сети работают по принципу коммутации пакетов (или кадров), то измерение количества переданной информации в пакетах имеет смысл, тем более что пропускная способность коммуникационного оборудования, работающего на канальном уровне и выше, также чаще всего измеряется в пакетах в секунду. Однако, из-за переменного размера пакета (это характерно для всех протоколов за исключением АТМ, имеющего фиксированный размер пакета в 53 байта), измерение пропускной способности в пакетах в секунду связано с некоторой неопределенностью - пакеты какого протокола и какого размера имеются в виду? Чаще всего подразумевают пакеты протокола Ethernet, как самого распространенного, имеющие минимальный для протокола размер в 64 байта (без преамбулы). Пакеты минимальной длины выбраны в качестве эталонных из-за того, что они создают для коммуникационного оборудования наиболее тяжелый режим работы - вычислительные операции, производимые с каждым пришедшим пакетом, в очень слабой степени зависят от его размера, поэтому на единицу переносимой информации обработка пакета минимальной длины требует выполнения гораздо больше операций, чем для пакета максимальной длины.
Измерение пропускной способности в битах в секунду ( для локальных сетей более характерны скорости, измеряемые в миллионах бит в секунду - Мб/c) дает более точную оценку скорости передаваемой информации, чем при использовании пакетов.
Критерии, отличающиеся учетом служебной информации. В любом протоколе имеется заголовок, переносящий служебную информацию, и поле данных, в котором переносится информация, считающаяся для данного протокола пользовательской. Например, в кадре протокола Ethernet минимального размера 46 байт (из 64) представляют собой поле данных, а оставшиеся 18 являются служебной информацией. При измерении пропускной способности в пакетах в секунду отделить пользовательскую информацию от служебной невозможно, а при побитовом измерении - можно.
Если пропускная способность измеряется без деления информации на пользовательскую и служебную, то в этом случае нельзя ставить задачу выбора протокола или стека протоколов для данной сети. Это объясняется тем, что даже если при замене одного протокола на другой мы получим более высокую пропускную способность сети, то это не означает, что для конечных пользователей сеть будет работать быстрее - если доля служебной информации, приходящаяся на единицу пользовательских данных, у этих протоколов различная (а в общем случае это так), то можно в качестве оптимального выбрать более медленный вариант сети. Если же тип протокола не меняется при настройке сети, то можно использовать и критерии, не выделяющие пользовательские данные из общего потока.
При тестировании пропускной способности сети на прикладном уровне легче всего измерять как раз пропускную способность по пользовательским данным. Для этого достаточно измерить время передачи файла определенного размера между сервером и клиентом и разделить размер файла на полученное время. Для измерения общей пропускной способности необходимы специальные инструменты измерения - анализаторы протоколов или SNMP или RMON агенты, встроенные в операционные системы, сетевые адаптеры или коммуникационное оборудование.
Критерии, отличающиеся количеством и расположением точек измерения. Пропускную способность можно измерять между любыми двумя узлами или точками сети, например, между клиентским компьютером 1 и сервером 3 из примера, приведенного на рисунке 1.2. При этом получаемые значения пропускной способности будут изменяться при одних и тех же условиях работы сети в зависимости от того, между какими двумя точками производятся измерения. Так как в сети одновременно работает большое число пользовательских компьютеров и серверов, то полную характеристику пропускной способности сети дает набор пропускных способностей, измеренных для различных сочетаний взаимодействующих компьютеров - так называемая матрица трафика узлов сети. Существуют специальные средства измерения, которые фиксируют матрицу трафика для каждого узла сети.
Так как в сетях данные на пути до узла назначения обычно проходят через несколько транзитных промежуточных этапов обработки, то в качестве критерия эффективности может рассматриваться пропускная способность отдельного промежуточного элемента сети - отдельного канала, сегмента или коммуникационного устройства.
Знание общей пропускной способности между двумя узлами не может дать полной информации о возможных путях ее повышения, так как из общей цифры нельзя понять, какой из промежуточных этапов обработки пакетов в наибольшей степени тормозит работу сети. Поэтому данные о пропускной способности отдельных элементов сети могут быть полезны для принятия решения о способах ее оптимизации.
В рассматриваемом примере пакеты на пути от клиентского компьютера 1 до сервера 3 проходят через следующие промежуточные элементы сети:
Сегмент АR КоммутаторR Сегмент ВR МаршрутизаторR Сегмент СR ПовторительR Сегмент D.
Каждый из этих элементов обладает определенной пропускной способностью, поэтому общая пропускная способность сети между компьютером 1 и сервером 3 будет равна минимальной из пропускных способностей составляющих маршрута, а задержка передачи одного пакета (один из вариантов определения времени реакции) будет равна сумме задержек, вносимых каждым элементом.Для повышения пропускной способности составного пути необхдимо в первую очередь обратить внимание на самые медленные элементы - в данном случае таким элементом скорее всего будет маршрутизатор.
Имеет смысл определить общую пропускную способность сети как среднее количество информации, переданной между всеми узлами сети в единицу времени. Общая пропускная способность сети может измеряться как в пакетах в секунду, так и в битах в секунду. При делении сети на сегменты или подсети общая пропускная способность сети равна сумме пропускных способностей подсетей плюс пропускная способность межсегментных или межсетевых связей.
Протоколы
Коммуникационные протоколы физического и канального уровней учитываются в системе COMNETIII в таких элементах сети как каналы (links). Протоколы сетевого уровня отражены в работе узлов модели, которые принимают решения о выборе маршрута пакетов в сети.
Магистраль сети и каждая из подсетей могут работать на основе различных и независимых алгоритмов маршрутизации. Алгортмы маршрутизации, используемые COMNETIII, принимают решение на основе вычисления кратчайшего пути. Используются различные вариации этого принципа, отличающиеся используемой метрикой и способом обновления таблиц маршрутизации. Применяются статические алгоритмы, у которых таблица обновляется только один раз в начале моделирования, и динамические алгоритмы, периодически обновляющие таблицы. Возможно моделирование многопутевой маршрутизации, при которой достигается баланс трафика по нескольким альтернативным маршрутам.
COMNETIII поддерживает следующие алгоритмы маршрутизации:
RIP (минимум хопов), Наименьшая измеренная задержка, OSPF, IGRP, Задаваемые пользователем таблицы маршрутизации.
Протоколы, выполняющие транспортные функции и функции доставки сообщений между конечными узлами представлены в системе COMNETIII обширным набором протоколов: ATP, NCP, NCPBurstMode, TCP, UDP, NetBIOS, SNA. При испоьзовании этих протоколов пользователь выбирает их из библиотеки системы и задает конкретные параметры, например, размер сообщения, размер окна и т.п.
Рабочая нагрузка
В системе COMNETIII рабочая нагрузка создается источниками трафика. Каждый узел может быть соединен с несколькими источниками трафика разного типа.
Источники-приложения генерируют приложения, которые выполняются узлами типа процессоров или маршрутизатров. Узел выполняет команду за командой, имитируя работу приложений в сети. Источники могут генерировать сложные нестандартные приложения, а также простые, занимающиеся в основном отправкой и получением сообщений по сети.
Источники вызовов генерируют запросы на установление соединений в сетях с коммутацией каналов (сети с коммутируемыми виртуальными соединениями, ISDN, POTS).
Источники планируемой нагрузки генерируют данные, используя зависящее от времени расписание. При этом источник генерирует данные периодически, используя определенное распределение интервала времени между порциями данных. Можно моделировать зависимость интенсивности генерации данных от времени дня.
Источники "клиент-сервер" позволяют задавать не трафик между клиентами и сервером, а приложения, которые порождают этот трафик. Эти приложения работают в модели "клиент-сервер", и источник данного типа позволяет промоделировать вычислительную загрузку компьютера, работающего в роли сервера, то есть учесть время выполнений вычислительных операций, операций, связанных с обращением к диску, подсистеме ввода-вывода и т.п.
Разделение общей среды с помощью локальных мостов
Для преодоления ограничений технологий локальных сетей уже достаточно давно начали применять локальные мосты, которые являются функциональными предшественниками коммутаторов. Хотя в современных сетях коммутаторы почти вытеснили мосты из локальных сетей, принципы работы и соображения по их применению практически совпадают.
Мост - это устройство, которое обеспечивает взаимосвязь двух (реже нескольких) локальных сетей посредством передачи кадров из одной сети в другую с помощью их промежуточной буферизации. Мост, в отличие от повторителя, не старается поддержать побитовый синхронизм в обеих объединяемых сетях. Вместо этого он выступает по отношению к каждой из сетей как конечный узел. Он принимает кадр, буферизует его, анализирует адрес назначения кадра, и только в том случае, когда адресуемый узел действительно принадлежит другой сети, он передает его туда.
Для передачи кадра в другую сеть мост должен получить доступ к ее разделяемой среде передачи данных в соответствии с теми же правилами, что и обычный узел.
Таким образом, мост изолирует трафик одного сегмента от трафика другого сегмента, фильтруя кадры. Так как в каждый из сегментов теперь направляется трафик от меньшего числа узлов, то коэффициент загрузки сегментов уменьшается (рис. 2.11). В результате пропускная способность каждого сегмента увеличивается, а, значит, повышается и суммарная пропускная способность сети.

Рис. 2.11. Локализация трафика при использовании моста
Каждый сегмент сети остается доменом коллизий, то есть участком сети, в котором все узлы одновременно фиксируют и отрабатывают коллизию, в каком бы месте этого участка она бы ни случилась. Однако коллизии одного сегмента не приводят к возникновению коллизий в другом сегменте, так как мост не транслирует их между сегментами.
Сегментация сетей с помощью коммутаторов
Технология коммутации сегментов Ethernet была предложена фирмой Kalpana в 1990 году в ответ на растущие потребности в повышении пропускной способности локальных сетей. Эта технология основана на отказе от использования разделяемых линий связи между всеми узлами сегмента и использовании коммутаторов, позволяющих одновременно передавать пакеты между всеми его парами портов.
Функционально многопортовый коммутатор работает как многопортовый мост, то есть работает на канальном уровне, анализирует заголовки кадров, автоматически строит адресную таблицу и на основании этой таблицы перенаправляет кадр в один из своих выходных портов или фильтрует его, удаляя из буфера. Новшество заключалось в параллельной обработке поступающих кадров, в то время как мост обрабатывает кадр за кадром. Коммутатор же обычно имеет несколько внутренних процессоров обработки кадров, каждый из которых может выполнять алгоритм моста. Таким образом, можно считать, что коммутатор - это мультипроцессорный мост, имеющий за счет внутреннего параллелизма высокую производительность.
Этот эффект иллюстрирует рисунок 2.12. На рисунке изображена идеальная в отношении повышения производительности ситуация, когда два порта из 4-х, подключенных к коммутатору передают данные с максимальной для протокола Ethernet скоростью 10 Мб/с, причем они передают эти данные на остальные два порта коммутатора не конфликтуя - у каждого входного порта свой выходной порт. Если коммутатор обладает способностью успевать обрабатывать входной трафик даже при максимальной интенсивности поступления кадров на входные порты, то общая производительность коммутатора в приведенном примере составит 2х10 Мб/с, а при обобщении примера на N портов - (N/2 )х10 Мб/с. Говорят, что коммутатор предоставляет каждой станции или сегменту, подключенным к его портам выделенную пропускную способность протокола.
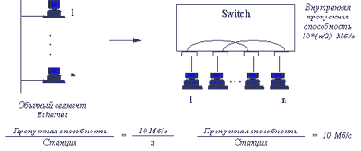
Рис. 2.12. Повышение производительности сети за счет одновременной обработки нескольких кадров
Первый коммутатор для локальных сетей не случайно появился для технологии Ethernet.
Семействопродуктов Distributed Sniffer System
DistributedSnifferSystem (DSS) - представляет собой систему, состоящую из нескольких распределенных по сети аппаратных компонент и программного обеспечения, необходимого для непрерывного анализа всех, включая удаленные, сегментов сети.
Система DSS строится из компонент двух типов - SnifferServer (SS) и SniffMasterConsole (SM).
Устройства типа SnifferServer представляют собой специализированный программно-аппаратный комплекс, построенный на базе компьютера класса 486 или Pentium, специализированных сетевых карт и дополнительных интерфейсов для взаимодействия с консолью. На сегодня доступны SnifferServer для анализа следующих сетевых технологий LAN и WAN:
Ethernet (10Base-Т, 10Base-2, 10Base-5); Token Ring (UTP, STP); FDDI (multimode fiber); Fast Ethernet (100Base-TX, 100Base-T4); ATM (ОС-3а multi-mode fiber, OC-3с copper, DS-3 соах, Е-3 соах); глобальных сетей (RS-232/Р5-449/Ч.35, X.25, framerelay, ISDNBRI и PRI до скоростей Е1 и T1).
В качестве интерфейсов для взаимодействия с консолью могут быть использованы карты Ethernet, TokenRing или последовательный порт. Таким образом, есть возможность контролировать сегмент практически любой сетевой топологии и использовать различные среды взаимодействия с консолью, включая соединения по модему.
SniffMasterConsole - программное обеспечение, выполняющее функции управления всей системой DSS. SniffMaster выпускается в вариантах для работы с MSWindows 3.1 или старше и для работы с различными вариантами Unix и систем управления сетями (HP-UX с НР OpenView, AIX с NetView, SunOS или Solaris с SunNetManager). Система SniffMaster предоставляет пользователю развитый графический интерфейс управления серверами SnifferServer. Одна единственная консоль SniffMaster способна управлять любым количеством серверов SnifferServer любых сетевых топологий. Кроме того, возможна установка нескольких консолей для управления одним сервером SnifferServer или их группой, что позволяет создавать запасные пункты контроля сети и позволяет нескольким экспертам-администраторам совместно решать возникающие задачи.
Система DSS в общих чертах повторяет типичную схему построения распределенной системы анализа сетей. Однако есть несколько особенностей, выведших именно эту систему в лидеры рынка.
Во-первых, это - концепция взаимодействия сервера и консоли анализа. Развивая концепцию RMON, сервер анализа SnifferServer действует как полностью независимое устройство, не только собирая информацию о функционировании сети (подобно агенту SNMP) или проводя ее первичную обработку (подобно агенту RMON), но и выполняя ее полный анализ на всех семи уровнях сетевой модели ISO/OSI. Более того, сервер берет на себя все функции по отображению информации, формируя некий виртуальный экран с информацией о функционировании конкретного сегмента сети. Далее этот виртуальный экран передается на консоль, где и отображается в отдельном окне. Для управления сервером анализа имеется возможность пересылки команд с консоли на сервер. Любые обмены данными между сервером и консолью оптимизируются, например, при передаче виртуального экрана реально передаются только скомпрессированные данные, представляющие собой изменение содержимого этого экрана по сравнению с предыдущей пересылкой.
Второй особенностью является использование для связи между консолью и сервером фирменного протокола передачи данных NGCP (NetworkGeneralCommunicationProtocol) вместо SNMP. Протокол NGCP базируется на протоколе ТСР и, в отличие от SNMP, является защищенным, то есть все передаваемые посредством NGCP данные передаются в зашифрованном виде. Учитывая, что при работе систем типа SnifferServer любая циркулирующая в сети информация, включая адреса станций, запросы к серверам баз данных и ответы от них и даже пароли доступа, могут быть легко перехвачены и подвергнуты анализу, возможность использования защищенных методов связи оказывается очень уместной. NGCP может быть использован как для связи по локальной сети, так и по коммутируемым и выделенным каналам (в этом случае используется протокол NGCP-serial, подобный PPP).
Программное обеспечение SnifferServer состоит из трех подсистем - мониторинга, интерпретации протоколов и экспертного анализа.
Подсистема мониторинга представляет собой систему отображения текущего состояния сети, позволяющую получать статистику по каждой из станций и сегментов сетей по каждому из используемых протоколов. Две остальные подсистемы заслуживают отдельного обсуждения.
Подсистема ProtocolInterpreter
В функции этой подсистемы входит анализ захваченных пакетов и как можно более полная интерпретация каждого из полей заголовков пакетов и его содержимого. Компания NetworkGeneral создала самую мощную подсистему подобного типа - ProtocolInterpreter способен полностью декодировать более 200 протоколов всех семи уровней модели ISO/OSI (TCP/IP, IPX/SPX, NCP, DECnetSunNFS, X-Windows, семейство протоколов SNAIBM, AppleTalk, BanyanVINES, OSI, XNS, Х.25, различные протоколы межсетевого взаимодействия). При этом отображение информации возможно в одном из трех режимов - общем, детализированном и шестнадцатеричном.
Общий режим предусматривает отображение лишь наиболее важной информации о пакете - адреса отправителя и получателя, название высшего по иерархии ISO/OSI протокола, использованного в пакете, краткая характеристика содержимого пакета (например, чтение данных). В этом режиме каждый из пакетов занимает одну строку в окне интерпретатора протоколов.
Детализированный режим предусматривает отображение полной расшифровки всей иерархии протоколов, при этом каждый из уровней иерархии отображается своим цветом, дается расшифровка на близком к естественному английскому, каждого из полей пакетов всех уровней иерархии и подробно описываются данные пакета (рис. 3.2).

Рис. 3.2. ProtocolInterpreter
При работе в шестнадцатеричном режиме пакеты отображаются в шестнадцатеричном виде, а также в виде символов кодировок ASCII или EBCDIC.
Для разработчиков поставляется специальный инструментарий - PDK (ProtocolDevelopmentKit), позволяющий создавать модули поддержки новых протоколов для ProtocolInterpreter.
Подсистема ЕхреrtAnаlysis
Сердцем серверов SnifferServer является экспертная система анализа сети ExpertAnаlysis.
В основе системы лежит уникальная база знаний, накопленная специалистами компании NetworkGeneral с 1986 года и основанная на опыте работы с пользователями различных сетей и разработках групп Станфордского и Массачусетского университетов, а также компании NipponTelephoneandTelegraph (NTT).
Основное назначение системы - сокращение времени простоя сети и ликвидация узких мест сети с помощью автоматической идентификации аномальных явлений и автоматической генерации методов их разрешения. Система экспертного анализа предоставляет диагностическую информацию трех категорий:
Симптом - событие в сети, которому администратор сети должен уделить дополнительное внимание (например, физическая ошибка при обращении к узлу сети или единичная повторная передача файла). Не обязательно означает возникновение проблемы, однако при высоком уровне периодичности требует внимания администратора. Диагноз - неоднократное повторение симптома, подлежащее обязательному расследованию со стороны администратора сети. Обычно диагноз описывает ситуации, характеризующие серьезные неисправности в сети (например, дублируемый сетевой адрес). Объяснение - контекстно-зависимое экспертное заключение системы анализа для каждого симптома или диагноза. Объяснение содержит описание нескольких возможных причин сложившейся ситуации, обоснование подобного заключения и рекомендации по их устранению.
В системе имеются возможности дополнения существующей базы знаний специфическими данными, полученными администратором сети в процессе ее использования.
Система автоматического анализа ExpertAnalysis основана на уникальной многозадачной технологии анализа пакетов, которую в нескольких словах можно описать следующим образом:
Циркулирующие в сети пакеты непрерывно захватываются и помещаются в кольцевой буфер захвата (первая задача). Одновременно с этим несколько задач-анализаторов протоколов (по одной на каждое из семейств протоколов) сканируют буфер захвата и генерируют информацию в едином внутреннем формате. Эта стандартизованная информация поступает на группу задач-экспертов.
Каждый из экспертов является таковым лишь в своей узкой области, например, в знании протокола взаимодействия клиента с сервером NetWare. Если эксперт находит событие, связанное с его областью интересов, он генерирует некоторый соответствующий объект (например, "пользователь Guest сервера IBSO") в объектно-ориентированной базе данных о сети, называемой BlackboardKnowledgeBase, и связывает его с соответствующими объектами более низкого уровня (в нашем случае - с адресом IPX станции пользователя Guest, связанным с МАС-адресом платы этой станции, и с сервером IBSO, связанным с адресами IPX и IP, а также с MAC-адресами сетевых плат сервера, а также со всеми уже вошедшими на сервер пользователями, принт-серверами, и т.д.). В результате возникает некоторая сложная структура, отображающая все объекты сети, относящиеся к некоторому протоколу и все возможные связи между ними на всех 7 уровнях модели ISO/OSI. Существует вторая группа задач-экспертов, постоянно анализирующая состояние базы данных и выдающих сообщения о ненормальном функционировании сети (симптомы или диагнозы). В общей сложности система ExpertAnalysis знакома с более чем 200 различными проблемами функционирования сети.
Последний элемент этой системы - эксперты, генерирующие подробное описание проблемы и методы ее исправления. При этом эти эксперты сканируют базу данных и подставляют в выдаваемые рекомендации реальные объекты сети - МАС-адреса, названия серверов, имена задач и т.д.
Подобная многозадачная система анализа является уникальной на рынке анализаторов. Некоторые из продуктов компаний-конкурентов также предлагают системы с элементами искусственного интеллекта, однако принципы построения их совершенно иные. Исповедуемый компанией NetworkGeneral принцип построения анализатора на основе "круглого стола экспертов", реализованного на основе специализированного многозадачного ядра, позволяет проводить анализ с очень высокой производительностью. Задачи-эксперты одновременно ведут обработку информации по мере ее поступления, а используемые эвристические правила позволяют быстро локализовать круг экспертов по каждому из конкретных случаев и временно приостановить работу других экспертов.
Исповедуемый другими компаниями принцип, требующий последовательного применения всех эвристических правил, ведет к снижению производительности анализа на тех же мощностях процессора и к необходимости использования более мощного процессора для обеспечения соизмеримой производительности.
Система ExpertAnalysis обеспечивает то, что компания NetworkGeneral называет активным анализом. Для понимания этой концепции рассмотрим обработку одного и того же ошибочного события в сети системами традиционного пассивного анализа, и системой активного анализа.
Пусть в сети в 3:00 ночи произошел широковещательный шторм, вызвавший в 3:05 сбой системы создания архивных копий баз данных. К 4:00 шторм прекращается и параметры системы входят в норму. В случае работы в сети системы пассивного анализа трафика пришедшие на работу к 8:00 администраторы не имеют для анализа ничего, кроме информации о втором сбое и, в лучшем случае, общей статистики по трафику за ночь - размер любого буфера захвата не позволит хранить весь трафик, прошедший по сети за ночь. Вероятность ликвидации причины, приведшей к широковещательному шторму в такой ситуации крайне мала.
А теперь рассмотрим реакцию на те же события системы активного анализа. В 3:00, сразу после начала широковещательного шторма, система активного анализа фиксирует наступление нестандартной ситуации, активирует соответствующий эксперт и фиксирует выданную им информацию о событии и его причинах в базе данных. В 3:05 фиксируется новая нестандартная ситуация, связанная со сбоем системы архивирования, и фиксируется соответствующая информация. В результате в 8:00 администраторы получают полное описание возникших проблем, их причин и рекомендации по устранению этих причин.
Сетевые анализаторы
Сетевые анализаторы (не следует путать их с анализаторами протоколов) представляют собой эталонные измерительные инструменты для диагностики и сертификации кабелей и кабельных систем. В качестве примера можно привести сетевые анализаторы компании HewlettPackard - HP 4195A и HP 8510C.
Сетевые анализаторы содержат высокоточный частотный генератор и узкополосный приемник. Передавая сигналы различных частот в передающую пару и измеряя сигнал в приемной паре, можно измерить затухание и NEXT. Сетевые анализаторы - это прецизионные крупногабаритные и дорогие (стоимостью более $20'000) приборы, предназначенные для использования в лабораторных условиях специально обученным техническим персоналом.
Широковещательный шторм
Обычно протоколы проектируются таким образом, что уровень широковещательного трафика составляет небольшую долю общей пропускной способности сети. Считается, что нормальный уровень широковещательного трафика не должен превышать 8% - 10% пропускной способности сети. Однако, уже при достижении порога в 5% считается целесообразным провести анализ узлов, которые генерируют наибольщую долю широковещательного трафика - возможно, они нуждаются в реконфигурации.
Каждый протокол-источник широковещательных пакетов чаще всего порождает широковещательный трафик постоянной интенсивности, так как посылает в сеть пакеты фиксированного размера через определенные промежутки времени. Например, протокол SAP объявляет о существовании конкретного файл- или принт- сервиса каждые 60 секунд с помощью широковещательного сообщения фиксированного размера. Можно привести пример источника, порождающего широковещательный трафик переменной интенсивности. Таким источником является протокол обмена маршрутной информации RIP, который раз в 30 или 60 секунд рассылает по сети содержимое таблицы маршрутизации, а так как эта таблица может иметь переменный размер, то и интенсивность трафика, создаваемого протоколом RIP, может изменяться.
Общая интенсивность широковещательного трафика в сети будет определяться двумя факторами - количеством источников такого трафика и средней интенсивностью каждого источника. Протоколы локальных сетей разрабатывались в начале 80-х годов в расчете на сравнительно небольшое число компьютеров, генерирующих широковещательный трафик, а также с учетом большого запаса пропускной способности каналов локальных сетей (10 Мб/c) по сравнению с потребностями файлового сервиса миникомпьютеров и настольных компьютеров того времени. Поэтому стеки протоколов, которые проектировались исключительно для применения в локальных сетях - NovellNetWareIPX/SPX и стек NetBIOS/SMB компаний IBM и Microsoft - широко пользовались широковещательными рассылками для создания максимума удобств для пользователей, которым не нужно было запоминать имена и адреса серверов.
Стек TCP/IP проектировался в расчете на работу в любых условиях - как в локальных сетях, так и в глобальных сетях с низкоскоростными каналами. Поэтому стек TCP/IP гораздо реже пользуется широковещательными сообщениями - в основном только тогда, когда это крайне необходимо. Это гарантирует стеку TCP/IP приемлемый уровень широковещательности даже на низкоскоростных каналах, в то время как в сетях NetWare уровень широковещательности на глобальных каналах может достигать нежелательной цифры в 20%.
Превышение широковещательным трафиком уровня более 20% называется широковещательным штормом (bradcaststorm). Это явление крайне нежелательно, так как приводит к возрастанию коэффициента использования сети, а, следовательно, и к резкому увеличению времени ожидания доступа.
Широковещательный трафик мостов и коммутаторов, поддерживающих алгоритм SpanningTree
Мосты и коммутаторы используют алгоритм покрывающего дерева SpanningTree для поддержания в сети резервных избыточных связей и перехода на них в случае отказа одной из основных связей. Алгоритм работы мостов и коммутаторов не позволяет использовать избыточные связи в основном режиме работы (при такой топологии связей кадры могут зацикливаться или дублироваться), поэтому основной задачей алгоритма SpanningTree является нахождение топологии дерева, покрывающей исходную топологию сети.
Для создания древовидной конфигурации мосты и коммутаторы, поддерживающие алгоритм SpanningTree постоянно обмениваются специальными служебными кадрами, которые вкладываются в кадры MAC-уровня. Эти кадры рассылаются по всем портам моста/коммутатора, за исключением того, на который они пришли, точно так же, как и пакеты протоколов RIP или OSPF маршрутизаторами. На основании этой служебной информации некоторые порты мостов переводятся в резервное состояние, и тем самым создается топология покрывающего дерева.
После установления этой топологии широковещательный трафик алгоритма SpanningTree не прекращается. Мосты/коммутаторы продолжают распространять по сети кадры протокола SpanningTree для контроля работоспособности связей в сети. Если какой-либо мост/коммутатор перестает периодически получать такие кадры, то он снова активизурует процедуру построения топологии покрывающего дерева.
Уровень широковещательного трафика протокола SpanningTree прямо пропорционален количеству мостов и коммутаторов, установленных в сети.
Маршрутизаторы трафик алгоритма SpanningTree не передают, ограничивая топологию покрывающего дерева одной сетью.
Широковещательный трафик сетей NetBIOS
Протокол NetBIOS широко используется в небольших сетях, не разделенных маршрутизаторами на части. Этот протокол поддерживается в операционных системах WindowsforWorkgroups и WindowsNT компании Microsoft, в операционной системе OS/2 Warp компании IBM, а также в некоторых версиях Unix. NetBIOS используется не только как коммуникационный протокол, но и как интерфейс к протоколам, выполняющим транспортные функции в сети, например, к протоколам TCP, UDP или IPX. Последняя роль NetBIOS связана с тем, что в ОС, традиционно использовавших NetBIOS в качестве коммуникационного протокола, многие приложения и протоколы прикладного уровня были написаны в расчете на API, предоставляемый протоколом NetBIOS. При замене протокола NetBIOS на другие транспортные протоколы разработчики приложений и ОС захотели оставить свои программные продукты в неизменном виде, поэтому появились реализации интерфейса NetBIOS, оторванные от его функций как коммуникационного протокола, и выполняющие роль некоторой прослойки, транслирующей запросы одного API в другой.
Основным источником широковещательного трафика в сетях, использующих NetBIOS либо в качестве интерфейса, либо в качестве протокола, является служебный протокол разрешения имен, который ставит в соответствие символьному имени компьютера его МАС-адрес. Все компьютеры, поддерживающие NetBIOS, периодически рассылают по сети запросы и ответы NameQuery и NameRequest, с помощью которых это соответствие поддерживается. При большом количестве компьютеров уровень широковещательного трафика может быть весьма высоким.
Маршрутизаторы обычно не пропускают широковещательный трафик NetBIOS между сетями.
Для уменьшения уровня этого трафика необходимо использовать централизованную службу имен, подобную службе WINS компании Microsoft.
Широковещательный трафик сетей NetWare
Стек протоколов сетей NetWare использует наибольшее число различных типов широковещательного трафика:
SAP (Service Advertising Protocol). Включает два типа сообщений - сообщения серверов о предоставляемых ими сервисах и запросы клиентских станций о поиске соответствующих сервисов в сети. Сообщения серверов включают информацию об имени сервера, типе сервиса (например, файл-сервис или принт-сервис), а также о полном сетевом адресе сервиса, включающем номер сети, номер узла и номер сокета. Сообщения сервера распространяются раз в 60 секунд. RIP IPX (Routing Information Protocol). Распространяет по интерсети информацию о составляющих сетях IPX, известных данному маршрутизатору, а также о расстоянии от данного маршрутизатора до каждой сети. Инормация распространяется каждые 60 секунд. Так как каждый сервер NetWare всегда является и маршрутизатором, то уровень трафика RIPIPX прямо пропорционален количеству серверов NetWare в интерсети, к которому следует добавить также количество установленных аппаратных маршрутизаторов, работающих по протоколу RIP. NLSP (NetWare Link State Protocol). Новый протокол обмена маршрутной информацией, который серверы NetWare и IPX-маршрутизаторы независимых производителей могут использовать вместо протокола RIP. Протокол NLSP создает меньший уровень широковещательного трафика, так как основную часть его широковещательных сообщений представляют сообщения об изменении состояния связей в сети и состояния самих маршрутизаторов. Очевидно, что в надежной сети такие сообщения генерируются достаточно редко. Протокол NLSP создает также и периодически генерируемый трафик, но он используется только для тестирования связей между соседними маршрутизаторами и порождает пакеты очень небольшой длины. NDS (NetWare Directory Services). Служба NDS сетей NetWare представляет собой централизованную справочную службу, хранящую информацию о всех пользователях и ресурсах сети. При наличии в сети сервера, выполняющего функции NDS, отпадает необходимость постоянной генерации трафика протокола SAP остальными серверами сети. Однако сам сервер службы NDS пользуется протоколом SAP для того, чтобы клиенты сети NetWare автоматически смогли узнать о его существовании и адресе. Поэтому служба NDS создает в сети собственный широковещательный трафик взамен трафика, создаваемого отдельными серверами. В сети может существовать несколько серверов NDS, реализующих распределенную и резервируемую структуру справочной службы, поэтому уровень широковещательного трафика NDS может быть значительным. Пакеты Keepalive протокола NCP (другое название - watchdog). С помощью пакетов этого типа сервер и клиент сообщают друг другу о том, что они работают и намерены поддерживать логическое соединенение. Пакеты keepalive используются в том случае, когда между сервером и клиентом длительное время (более 5 минут) нет обмена другими данными, что бывает в том случае, когда пользователь на длительное время отлучается от своего компьютера, оставляя его включенным.
Широковещательный трафик сетей TCP/IP
Как уже отмечалось, в сетях TCP/IP широковещательный трафик используется гораздо реже, чем в сетях NetWare. Широковещательный трафик в сетях TCP/IP создают протоколы разрешения IP-адресов ARP и RARP (реверсивный ARP), а также протоколы обмена маршрутной информацией RIPIP и OSPF. Протоколы ARP и RARP используются только в локальных сетях, где широковещательность поддерживается на канальном уровне. Протокол RIPIP принципиально ничем не отличается от протокола RIPIPX, а протокол OSPF является протоколом типа "состояния связей" как и протокол NLSP, поэтому он создает широковещательный трафик гораздо меньшей интенсивности, чем RIP.
Система имитационного моделирования COMNET компании CACIProducts
Компания CACIProducts является одним из лидеров рынка систем имитационного моделирования сетей, разрабатывая подобные средства уже 35 лет.
Система имитационного моделирования COMNET позволяет анализировать работу сложных сетей, работающих на основе практически всех современных сетевых технологий и включающих как локальные, так и глобальные связи.
Система COMNET состоит из нескольких основных частей, работающих как автономно, так и в комплексе:
COMNETBaseliner - пакет, предназначенный для сбора исходных данных о работе сети, необходимых для проведения моделирования. COMNETIII вместе с пакетом AdvanceFeaturesPack - система детального моделирования сети. COMNETPredictor - система быстрой оценки производительности сети.
4.4.1. COMNETBaseliner
Главной проблемой при любом моделировании сети является проблема сбора данных о существующей сети. Именно эту проблему помогает решить пакет COMNETBaseliner.
Этот пакет может работать со многими промышленными системами управления и мониторинга сетей, получая от них собранные данные и обрабатывая их для использования при моделировании сети с помощью систем COMNETIII или COMNETPredictor.
COMNETBaseline позволяет создавать разнообразные фильтры, с помощью которых можно извлечь нужную для моделирования информацию из импортируемых данных. С помощью COMNETBaseline можно:
Импортировать информацию о топологии сети, возможно, в иерархическом виде; Комбинировать информацию из нескольких файлов регистрации трафика, которые могут импортироваться из разных средств мониторинга в единую модель трафика; Предоставлять полученную модель трафика для предварительного беглого обзора; Просматривать графическое представление межузлового взаимодействия, в котором трафик каждой пары узлов отображается линией определенного цвета.
Пакет COMNETBaseline может импортировать данные из следующих продуктов:
| Топологическая информация: | Информация о трафике: |
| HP OpenView | Network General Expert Sniffer Network Analyzer |
| Cabletron SPECTRUM | Network General Distributed Sniffer System |
| IBM NetView for AIX | Frontier Software NETscout |
| Digital POLYCENTER | Axon Network LAN servant |
| Castlerock SNMPc | HP NetMetrix |
| CACI SIMPROCESS | Wandel & Goltermann Domino Analyzer Compuware EcoNet |
| NACMIND | Большинство средств RMON |
Система управления сетями Optivity
Система управления Optivity компании BayNetworks выпускается в различных вариантах, отличающихся набором функциональных свойств и программно-аппаратными платформами.
Версия OptivityEnterprise работает на RISC-компьютерах в средах SunNetManager, HPOpenViewNetworkNodeManager и IBMNetViewAIX/6000. Эта версия предназначена для больших корпоративных сетей с количеством узлов более 1000, обладает высокой степенью масштабируемости и наиболее полным набором функций. Состоит из следующих подсистем:
OptivityLAN для управления локальными сетями, коммутаторами и концентраторами, OptivityInternetwork для управления сетями с применением маршрутизаторов, OptivityDesignandAnalysis поддерживает функции планирования и анализа сети, Кроме этих подсистем состав OptivityEnterprise может быть дополнен подсистемами ATMNetworkManagementApplication для управления сетями, построенными на основе ATM-коммутаторов. Эта подсистема располагается в среде SunNetManager вместе с другими компонентами Optivity и позволяет контролировать и управлять устройствами LattisCell и EtherCell, а также создавать виртуальные сети.
Версия OptivityCampus работает на персональных компьютерах с процессором Intel в средах HPOpenViewforWindows и NovellNetWareManagementSystem. Эта версия предназначена для управления сетями средних размеров (от 150 до 1000), состоящих из концентраторов, коммутаторов и маршрутизаторов.
Версия OptivityWorkgroup работает в среде MSWindows на персональных компьютерах с процессором Intel и предназначена для управления небольшими сетями (до 200 узлов), состоящими из концентраторов, коммутаторов и маршрутизаторов.
В своей работе система Optivity опирается на функциональные возможности агентов SNMP, встроенных в коммуникационные устройства.
Существует три версии агентов - Standard, Advanced и AdvancedAnalyzer.
Агенты AdvancedAnalyzerреализуют наиболее развитую на сегодняшний день промышленную технологию встроенных агентов, включая полную поддержку всех групп стандарта RMON, а также средства SuperRMON.
Средства SuperRMON расширяют возможности стандарта RMON на 1 уровень семиуровневой модели (для контроля портов) и на 3 уровень.
Агенты Advancedподдерживают развитые свойства встроенного управления - пороги, защиту доступа, автотопологию, а также четыре группы переменных RMON.
Агенты Standardобеспечивают только базовые средства управления и сбора статистики для концентраторов.
Рассмотрим подробнее свойства версии среднего класса - OptivityforHPOpenView/Windows.
Как и другие версии Optivity, данная версия предоставляет полный набор средств для управления транспортными функциями сети как единой, согласованной системой, а не набором несвязанных устройств. Система Optivity дает общую картину корпоративной сети за счет отражения и управления взаимосвязями между концентраторами, коммутаторами, маршрутизаторами, мостами и конечными станциями.
Optivity легко интегрируется с платформой HPOpenView. В этой системе объединены средства управления маршрутизаторами и поддержка стандарта RMON, что позволяет пользователям собирать детализированную информацию об отказах, ошибках, производительности и диагностике в любом месте сети. Динамическое отображение состояния сети позволяет легко получать точную информацию по каждому порту.
OptivityforOpenViewforWindows поддерживает всю линию продуктов BayNetworks: концентраторы System 800, System 2000, System 3000, Distributed 5000, System 5000, коммутаторы LattisSwitchSystem 28000 FastEthernet и маршрутизаторы AN, ANH, ASN, BLN и BCN.
Специализированные системы имитационного моделирования вычислительных сетей
Существуют специальные, ориентированные на моделирование вычислительных сетей программные системы, в которых процесс создания модели упрощен. Такие программные системы сами генерируют модель сети на основе исходных данных о ее топологии и используемых протоколах, об интенсивностях потоков запросов между компьютерами сети, протяженности линий связи, о типах используемого оборудования и приложений. Программные системы моделирования могут быть узко специализированными и достаточно универсальными, позволяющие имитировать сети самых различных типов. Качество результатов моделирования в значительной степени зависит от точности исходных данных о сети, переданных в систему имитационного моделирования.
Программные системы моделирования сетей - инструмент, который может пригодиться любому администратору корпоративной сети, особенно при проектировании новой сети или внесении кардинальных изменений в уже существующую. Продукты данной категории позволяют проверить последствия внедрения тех или иных решений еще до оплаты приобретаемого оборудования. Конечно, большинство из этих программных пакетов стоят достаточно дорого, но и возможная экономия может быть тоже весьма ощутимой.
Программы имитационного моделирования сети используют в своей работе информацию о пространственном расположении сети, числе узлов, конфигурации связей, скоростях передачи данных, используемых протоколах и типе оборудования, а также о выполняемых в сети приложениях.
Обычно имитационная модель строится не с нуля. Существуют готовые имитационные модели основных элементов сетей: наиболее распространенных типов маршрутизаторов, каналов связи, методов доступа, протоколов и т.п. Эти модели отдельных элементов сети создаются на основании различных данных: результатов тестовых испытаний реальных устройств, анализа принципов их работы, аналитических соотношений. В результате создается библиотека типовых элементов сети, которые можно настраивать с помощью заранее предусмотренных в моделях параметров.
Системы имитационного моделирования обычно включают также набор средств для подготовки исходных данных об исследуемой сети - предварительной обработки данных о топологии сети и измеренном трафике.
Эти средства могут быть полезны, если моделируемая сеть представляет собой вариант существующей сети и имеется возможность провести в ней измерения трафика и других параметров, нужных для моделирования. Кроме того, система снабжается средствами для статистической обработки полученных результатов моделирования.
В следующей таблице приведены характеристики нескольких популярных систем имитационного моделирования различного класса - от простых программ, предназначенных для установки на персональном компьютере, до мощных систем, включающих библиотеки большинства имеющихся на рынке коммуникационных устройств и позволяющих в значительной степени автоматизировать исследование изучаемой сети.
| Компания и продукт | Стоимость(долл) | Тип сети | Требуемые ресурсы | Примечания |
| American HYTech, Prophesy | 1495 | ЛС | 8МбОП, 6 Мбдиск, DOS, Windows, OS/2 | Оценивание производительности при работе с текстовыми и графическими данными по отдельным сегментам и сети в целом |
| CACI Product, COMNET III | 34500-39500 | ЛС, ГС | 32 МбОП, 100 Мбдиск, Windows, Windows NT, OS/2, Unix | Моделируетсети X.25, ATM, Frame Relay, связи LAN-WAN, SNA, DECnet, протоколы OSPF, RIP. Доступ CSMA/CD и токенный доступ, FDDI и др. Встроенная библиотека марщрутизаторов 3COM, Cisco, DEC, HP, Wellfleat, ... |
| Make System, NetMaker XA | 6995-14995 | ЛС, ГС | 128 МбОП, 2000 Мбдиск, AIX, Sun OS, Sun Solaris | Проверка данных о топологии сети; импорт информации о трафике, получаемой в реальном времени |
| NetMagic System,StressMagik | 2995 | ЛС | 2 МбОП, 8 МБдиск, Windows | Поддержка стандартных тестов измерения производительности; имитация пиковой нагрузки на файл-сервер |
| Network Analysis Center, MIND | 9400-70000 | ГС | 8 MбОП, 65 Мбдиск, DOS, Windows | Средство проектирования, оптимизации сети, содержит данные о стоимости типичных конфигураций с возможностью точного оценивания производительности |
| Network Design and Analysis Group, AutoNet/ Designer | 25000 | ГС | 8 MбОП, 40 Мбдиск, Windows, OS/2 | Определение оптимального расположения концентратора в ГС, возможность оценки экономии средств за счет снижения тарифной платы, смены поставщика услуг и обновления оборудования; сравнение вариантов связи через ближайшую и оптимальную точку доступа, а также через мост и местную телефонную сеть |
| Network Design and Analysis Group, AutoNet/ MeshNET | 30000 | ГС | 8 MбОП, 40 Мбдиск, Windows, OS/2 | Моделирование полосы пропускания и оптимизация расходов на организацию ГС путем имитации поврежденных линий, поддержка тарифной сетки компаний AT & T, Sprint, WiTel, Bell |
| Network Design and Analysis Group, AutoNet/ Performance-1 | 4000 | ГС | 8 MбОП, 1 Мбдиск, Windows, OS/2 | Моделирование производительности иерархических сетей путем анализа чувствительности к длительности задержки, времени ответа, а также узких мест в структуре сети |
| Network Design and Analysis Group, AutoNet/ Performance-3 | 6000 | ГС | 8 MбОП, 3 Мбдиск, Windows, OS/2 | Моделирование производительности многопротокольных объединений локальных и глобальных сетей; оценивание задержек в очередях, прогнозирование времени ответа, а также узких мест в структуре сети; учет реальных данных о трафике, поступающих от сетевых анализаторов |
| System& Networks, BONES | 20000-40000 | ЛС, ГС | 32 MбОП, 80 Мбдиск, Sun OS, Sun Solaris, HP-UX | Анализ воздействия приложений клиент-сервер и новых технологий на работу сети |
| MIL3,Opnet | 16000-40000 | 16 МбОП, 100 Мбдиск, DEC AXP, Sun OS, Sun Solaris, HP-UX | Имеет библиотеку различных сетевых устройств, поддерживает анимацию, генерирует карту сети, моделирует полосу пропускания. |
Сравнение протоколов IP, IPX и NetBIOS по производительности
Пропускная способность протоколов сетевого и транспортного уровней (протокол NetBIOS и его модификация NetBEUI в строгом смысле не относятся к сетевому уровню, так как не оперируют с понятием "номер сети", эти протоколы скорее можно отнести к транспортному и представительному уровням) во многом зависит от протокола канального уровня, над которым работают эти протоколы. Поэтому сравнивать протоколы сетевого и транспортного уровней нужно в предположении, что они используют один и тот же протокол канального уровня, например, Ethernet или FDDI.
Измерения, проведенные в реальных сетях, показывают, что наиболее медленным протоколом локальных сетей является протокол IP. Его сравнительно низкая пропускная способность является платой за его универсальность, то есть способность объединять практически все существующие сетевые технологии - Ethernet и X.25, ATM и FrameRelay и т.п. Универсальность протокола IP во многом обеспечивается независимой схемой адресации узлов, когда независимо от локального адреса узлу произвольным образом присваивается IP-адрес единого формата, никак не связанного с форматом локального адреса. Соответствие IP-адресов локальным адресам узлов устанавливает специальный протокол разрешения адресов ARP (AddressResolutionProtocol), который в локальных сетях использует для этой цели широковещательные запросы.
Протокол IPX использует в качестве номера узла тот же локальный адрес узла, что и протоколы канального уровня, а именно, его МАС-адрес. Поэтому протокол IPX не требует привлечения дополнительного протокола типа ARP при передаче пакетов. В результате пропускная способность сети при использовании протокола IPX обычно выше чем при использовании протокола IP. Кроме того, что использование ARP вводит новый этап обработки пакета, использование широковещательного трафика само по себе снижает пропускную способность сети, так как повышает степень загрузки сегментов сети. Вопрос влияния широковещательного трафика на производительность сети более подробно рассматривается в следующем разделе.
Протокол NetBIOS строго ориентирован на работу в локальных сетях, не разделяемых на части маршрутизаторами. Поэтому его разработчики не стали вводить такого понятия как "сеть" или "номер сети", ограничившись использованием для компьютеров МАС-адресов и символьных имен. Протокол NetBIOS может работать в двух режимах - дейтаграммном и с установлением соединения. В последнем случае он занимается восстановлением утерянных и искаженных кадров протокола канального уровня, что потенциально повышает пропускную способность сети, так как переносит процедуры востановления на более низкий уровень по сравнению с прикладным, как в случае применения стека NovellNetWare.
Протокол NetBIOS широко использует широковещательный трафик - в данном случае он используется для установления соответствия между символьными именами компьютеров и МАС-адресами. Поэтому производительность сети, использующей протокол NetBIOS, может снижаться из-за засорения разделяемого канала служебным широковещательным трафиком.
В целом, в сетях небольших размеров пропускная способность при использовании протоколов IPX и NetBIOS будет выше, чем при использовании протокола IP. Однако, при увеличении размеров сети и особенно количества компьютеров в сети, влияние широковещательного трафика может значительно снизить доступную для пользовательских данных полосу пропускания, и применение протокола IP будет предпочтительнее. Кроме того, необходимо учитывать тенденции развития протокола IP. В новой версии этого протокола - IPv6, процесс внедрения которой уже начался, протокол ARP перестанет применяться, так как в качестве IP-адреса узла будет использоваться локальный адрес, как это делается в протоколе IPX.
Сравнение сетевых технологий по
В этом разделе подводятся некоторые итоги рассмотрения влияния различных параметров протоколов канального уровня на пропускную способность сети, а также приводятся результаты одного экспериментального сравнения протоколов в незагруженной сети.
Необходимо отметить, что кроме такого критерия как пропускная способность, при выборе протокола обычно учитывается и ряд других соображений, иногда оказывающих на конечный выбор большее влияние, чем результирующая пропускная способность сети. Наиболее важными факторами, которые нужно принимать во внимание при выборе протокола, помимо его влияния на пропускную способность сети, являются:
Перспективность протокола. Желательно иметь уверенность, что выбранный вами протокол не постигнет судьба протокола ARCnet (или близкого к нему стандарта 802.4), который при неплохих технических показателях сошел на нет из-за отстутсвия поддержки со стороны большинства производителей коммуникационного оборудования. Перспективность протокола трудно прогнозировать, поэтому можно ориентироваться на фактор, рассматриваемый следующим. Количество компаний, поддерживающий данный протокол. Для примера сравним два новых высокоскоростных протокола - FastEthernet и 100VG-AnyLAN. Если первый поддерживают практически все производители оборудования для локальных сетей (более 100 известных компаний), то протокол 100VG-AnyLAN поддерживают только 30 производителей. Поэтому риск при переходе на протокол 100VG-AnyLAN более велик, чем при переходе на протокол FastEthernet. Отказоустойчивость протокола. Далеко не во все протоколы встроены процедуры тестирования корректности работы сети и автоматического восстановления работоспособности после отказов. Контроль доставки пакетов адресату и повторная передача искаженных и утраченных пакетов - это один из уровней отказоустойчивости, которым может обладать протокол. К сожалению, большая часть протоколов канального уровня локальных сетей не выполняет эти функции, а контролем работоспособности кабельной системы и аппаратуры, и автоматическим восстановлением работоспособности сети после отказов может похвастаться только протокол FDDI. Стоимость оборудования, реализующего данный протокол.
Этот фактор - один из главных, обеспечивших преобладание протокола Ethernet в локальных сетях и сдерживающих распространение технологии АТМ. Стоимость - немаловажный козырь в руках сторонников технологии FastEthernet, унаследовавшей от 10 Мб Ethernet'а простоту алгоритмов и, соответственно, минимальную стоимость среди всех протоколов локальных сетей. Поддержка трафика реального времени. В связи с необходимостью передачи по одной и той же сети традиционного компьютерного трафика, слабо чувствительного к задержкам, и мультимедийного трафика - голоса, видеоданных и т.п., плохо переносящего задержки пакетов даже в несколько миллисекунд, от протокола может потребоваться способность приоритизации чувствительного к задержкам трафика, который представляет собой трафик реального времени. В этом отношении протоколы Ethernet и FastEthernet уступают своим конкурентам, так как они не различают классы трафика. Протоколы FDDI и 100VG-AnyLAN различают трафик двух классов - обычный и высокоприоритетный и передают приоритетные кадры в первую очередь. Наиболее совершенным в отношении поддержки разных типов трафика является протокол АТМ, который сегодня различает 5 типов трафика - от компьютерного с неизвестной пропускной способностью до голосового трафика с постоянной средней битовой скоростью.
Если же вернуться к проблеме выбора протокола канального уровня по критерию максимизации пропускной способности сети, то наиболее влияющими параметрами протокола в этом отношении будут следующие:
номинальная пропускная способность протокола (битовая скорость передачи кадра); максимально допустимый размер поля данных кадра; номинальное время доступа к среде передачи данных.
Часто считается, что наиболее значимым фактором является номинальная пропускная способность и что протокол с большим ее значением всегда приводит к большей пропускной способности сети.
Однако это далеко не всегда верно. Результирующая пропускная способность сети складывается под влиянием многих параметров и часто наиболее значимым является размер поля данных кадра или же время доступа к среде.
Для подтверждения этого явления приведем результаты экспериментального сравнения пропускной способности сети при использовании в ней протоколов Ethernet, TokenRing и FDDI, отличающихся как номинальной пропускной способностью, так и максимальным размером поля данных и номинальным времени доступа к среде.
Экспериментальная сеть состояла всего из двух узлов - клиентского компьютера и сервера, поэтому фактор ожидания доступа к среде из-за ее загрузки здесь не исследовался.
Очевидно, что время выполнения запроса на клиентской и серверной машине не должно существенно превышать время передачи данных запроса по сети, иначе параметры протокола канального уровня будут малозначащими факторами эксперимента. В экспериментах времена выполнения запросов варьировались для оценки их влияния на результаты.
Исследовалось влияние на время реакции: номинальной пропускной способности, максимально допустимого размера поля данных кадра, номинального времени доступа к среде передачи данных.
Фактор номинальной пропускной способности
Увеличение пропускной способности повышает производительность сети, хотя часто и не в такой степени, как это ожидается. На рисунке 2.10а показано, как повышается производительность сети при переходе от номинальной пропускной способности 10 Мб/с протокола Ethernet к номинальной пропускной способности 16 Мб/с протокола TokenRing в зависимости от времени выполнения приложения. Из рисунка видно, что когда время выполнения приложения превышает 5 мс, то ожидаемый выигрыш в производительности будет меньше, чем 5%. Но даже тогда, когда время выполнения приложения пренебрежимо мало по сравнению со временем передачи запроса и ответа по сети, выигрыш в производительности составляет всего 30%, хотя номинальная пропускная способность возрастает на 60%. Для того, чтобы выяснить влияние на производительность только фактора пропускной способности, этот график был получен в предположении одинаковой длины пакетов и одинакового времени доступа к среде для обоих протоколов.
Фактор размера пакета
Разные протоколы характеризуются разными максимально допустимыми длинами пакетов. Например, Ethernet допускает в пакете поле данных, которое несет пользовательскую информацию длиной до 1024 байта, соответственно TokenRing 4 Мб/с - 4096 байт, TokenRing 16 Мб/с - 16384 байта, FDDI - 4096 байт.
На рисунке 2.10б показана зависимость повышения производительности сети при переходе от пакетов 1024 байта протокола Ethernet к пакетам 4096 протокола TokenRing 16 Мб/с. Ясно, что при этом действует и фактор повышения пропускной способности, но как видно из рисунка 2.10а, этот фактор действует гораздо слабее. Действительно, при нулевом времени выполнения приложения общий выигрыш от действия этих двух факторов составляет 190%, в то время как при увеличении только пропускной способности производительность увеличилась всего на 30%.

Рис. 2.10. Влияние различных факторов на производительность
Фактор номинального времени доступа к среде
Время доступа к среде - более значительный фактор, чем пропускная способность, хотя и менее важный, чем размер пакета. Рисунок 2.10в показывает, что прирост производительности при переходе от протокола Ethernet к протоколу TokenRing 16 Мб/с является отрицательным для всех точек кривой. Этот неожиданный результат означает, что в этих условиях Ethernet действительно превосходит по производительности TokenRing, хотя последний и превосходит его по пропускной способности в 1.6 раза. Для исключения влияния размера пакета данный анализ был сделан для пакетов в 1024 байта, которые могут передаваться обоими протоколами. Отношение времени доступа к среде протокола TokenRing к соответствующему времени протокола Ethernet было принято равным 5. Рисунок 2.10г показывает, что переход от протокола TokenRing к FDDI может привести не к ускорению, а к замедлению обмена при передаче больших файлов (из-за уменьшения поля данных пакета FDDI).
Средства анализа протокола NetBIOS
В настоящее время наблюдается постоянный рост числа сетей, использующих протокол NetBIOS, поскольку все большее применение находят операционные системы MicrosoftWindowsNT, Windows 95 и IBMOS/2 Warp. EnterpriseLANMeter диагностирует основные причины отказов в сетях NetBIOS: неправильно сконфигурированные узлы, дублирование имен NetBIOS, чрезмерно высокий уровень трафика NetBIOS.
Автоматическое конфигурирование стека IP (IР AutoConfiguration)
Функция предназначена для сетей, в которых используется протокол NetBIOSoverTCP/IP (NBT). Она осуществляет автоматическое IP-конфигурирование EnterpriseLANMeter.
Исследование сегмента (SegmentDiscovery)
Позволяет анализировать наиболее важные параметры сегмента NetBIOS, к которому подключен прибор. Автоматически выявляет проблемы типа дублирования имен, ошибок регистрации.
NetBIOSPing
Позволяет проверить достижимость узла по имени. Вызов NetBEUI является локальным по отношению к сегменту подключения и не может трассироваться. Вызов NetBIOS поверх IP или IPX/SPX может пересекать IP и IPX маршрутизаторы.
Основные отправители пакетов NetBIOS (Тор NetBIOSSenders)
Функция осуществляет слежение за наиболее активными передающими узлами NetBIOS в локальном сегменте. EnterpriseLANMeter может быть сконфигурирован для фильтрации информации по определенному адресу и индикации основных отправителей, обращающихся к конкретной станции сети.
Основные получатели пакетов NetBIOS (TopNetBIOSReceivers)
Функция отслеживает узлы, наиболее загруженные приемом пакетов NetBIOS в локальном сегменте.
Средства анализа протоколов стека NovellNetWare
Эта часть тестов проводит диагностику сетей с архитектурой Novell, проверяя правильность подключения клиентов и сервера через IPX-маршрутизаторы, а также регистрируя информацию об основных источниках трафика в сети.
Список серверов
Отражает перечень серверов, доступных конкретному участнику сети. Эта возможность подобна функции DisplayServers, встроенной в NovellServers. На результирующем экране отображаются присвоенное имя, сетевой адрес IPX и время отклика.
Опрос участников сети (NetWarePing)
Позволяет проверить правильность подключения клиента или сервера сети Novell. Присвоенное адресное имя целевой станции может быть выбрано из перечня станций или введено в шестнадцатиразрядном исчислении. На дисплей выводятся полученные IPX адрес, МАС-адрес, число и время отклика.
Пакетная статистика (PacketStatistics)
Эта функция основана на сборе статистических данных для оценки общего состояния трафика NetWare в локальном сегменте. Непрерывное наблюдение за трафиком включает регистрацию пакетов задержки (Delays), маршрутизированный трафик (Routed) и пакетный (Burstmode) трафик. Сетевые станции, генерирующие основной трафик в каждой категории, могут быть идентифицированы с помощью функции "Zooming" в желаемой категории.
Анализ маршрутизации (RoutingAnalysis)
LANMeter может помочь сбалансировать маршрутизацию IPX трафика. На дисплей выводится информация по категориям трафика, с распознаванием адресов сети назначения и сети-источика:
локальный - локальный; локальный - удаленный; удаленный - локальный.
Основные IPX отправители (Тор IPXSenders)
Функция помогает отслеживать узлы, наиболее интенсивно передающие IPX-пакеты. LANMeter может быть сконфигурирован таким образом, чтобы наблюдать за десятью основными отправителями информации конкретной сетевой станции. Данные выводятся на дисплей в виде круговой диаграммы вместе с перечнем основных отправителей, расположенных в порядке убывания. Адрес станции может быть указан в одном из трех форматов - присвоенное имя, МАС-адрес или IPX-сетевой номер.
Основные IPX получатели (TopIPXReceivers)
Функция позволяет вести непрерывное наблюдение за наиболее загруженными узлами-получателями на локальном сегменте. Информация выводится на дисплей в виде, аналогичном описанному выше.
Средства анализа протоколов стекаTCP/IP
Эта группа тестов обеспечивает диагностику причин отказов в сетях TCP/IP, проверяя правильность соединений и непрерывно отслеживая уровень трафика и ICMP-активность.
Мониторинг ICMP (ICPM Monitor)
Функция позволяет определить перегруженные устройства и неправильно сконфигурированные маршрутизаторы и центральные ЭВМ путем мониторинга ключевых ICMP-пакетов. В этом режиме LANMeter отслеживает и выводит на дисплей информацию о ряде основных IP- событий. К числу наблюдаемых относятся кадры: адресат недостижим (DestinationUnreachable), переадресовка (Redirect), обрыв источника сообщения SourceQuench), превышение времени (TimeExceeded) и отклонение параметра (Parameter Problem). Сетевые станции генерирующие основной трафик в каждой категории, могут быть идентифицированы с помощью функции "Zooming" в желаемой категории.
ICMPPing
Функция проверяет наличие связи с конкретной IP-станцией. Символьное имя, или IP-адрес станции, может быть выбрано из перечня или введено с клавиатуры в виде десятеричной разделенной точками записи. На дисплей выводится информация, содержащая IP-адрес, МАС-адрес, число откликов и время отклика.
Основные IP-отправители (Тор IPSenders)
Функция помогает отслеживать узлы, наиболее интенсивно передающие IP-пакеты в данном локальном сегменте. LANMeter может быть сконфигурирован таким образом, чтобы отфильтровать информацию по одному адресу и показать основных отправителей информации для конкретной сетевой станции. Данные выводятся на дисплей в виде круговой диаграммы вместе с перечнем основных отправителей, расположенным в порядке убывания интенсивностей генерируемых ими трафиков. Адрес станции отображается в виде присвоенного имени или IP-адреса.
Список всех станций, заявивших о себе как об отправителях в течение периода испытаний, может быть выведен на дисплей или распечатан.
Основные IP-получатели (Тор IPReceivers)
Функция позволяет вести непрерывное наблюдение за наиболее загруженными узлами - получателями в локальном сегменте. Информация выводится на дисплей в виде, аналогичном описанному выше.
Функция отслеживания маршрута (TraceRoute)
Функция TraceRoute сообщает о каждом маршрутизаторе, встреченном при посылке IP-пакета на конкретный узел. Если сервер DNS доступен, то в этом случае LANMeter отыскивает имя каждого встреченного устройства. В зависимости от конфигурации тестируемой сети функция TraceRoute покажет случаи использования множественных маршрутов, маршрут, по которому следует пакет при достижении им цели, и информацию о последнем маршрутизаторе, отправившем пакет, если он не достиг цели.
Средства мониторинга и анализа компании Fluke
Компания Fluke является одним из ведущих производителей средств диагностики и сертификации кабельных систем, а также средств мониторинга и анализа сетей.
Полный спектр портативных измерительных средств компании Fluke включает:
610 CableMapper - устройство для отображения кабельных соединений 620 CableMeter - устройство для тестирования кабельных систем DSP-100 DigitalCableMeter - устройство для сертификации кабелей категории 5 OneTouchNetworkAssistant - устройство для комплексной проверки кабельной проводки, концентраторов, сетевых адаптеров и мониторинга сетевого трафика 67XLANMeter - семейство приборов, совмещающих функции анализатора протокола, генератора трафика и кабельного тестера 68Х EnterpriseLANMeter - семейство приборов, предназначенное для анализа протоколов в корпоративной сети, включающее поддержку SNMP, RMON и анализ трафика в удаленных сетях.
Рассмотрим подробно серию портативных приборов EnterpriseLANMeter, обладающих наиболее широкими функциональными возможностями по исследованию сети.
Технические характеристики популярных анализаторов протоколов
В таблице приводятся характеристики нескольких анализаторов протоколов, среди которых лидирующие позиции занимает продукция компании NetworkGeneral.
| Компания | Продукт | Характеристики |
| Network General | Семейство Sniffer Analyzer | Семейство включает несколько вариантов автономного анализатора и сложную распределенную систему (DistributedSnifferSystem). Поддерживается весь диапазон сетевых технологий - Ethernet, TokenRing, ARCnet, SNA, FDDI, X.25 и др., все популярные стеки протоколов, сложные правила фильтрации, многооконный пользовательский интерфейс, графические средства представления результатов измерений и статистической обработки. Имеет встроенные средства генерации потока данных. |
| ProTools | Protolyzer | Работает в среде OS/2. Интерфейс в стиле Windows. Поддерживает TokenRing и Ethernet, стеки протоколов SMB/NetBIOS, IPX/SPX, TCP/IP, AppleTalk, BanyanVines,DECnet, XNS. Выполняет все основные функции фильтрации и отображения результатов анализа. Хорошие средства генерации отчетов. |
| IBM | Network Manager | Предназначен для анализа сетей TokenRing. Может работать в среде с несколькими кольцами. Имеет полный набор средств мониторинга и регистрации ошибок. |
| Telecommunications Techniques(Spider System) | Семейство NetLens (Spider Analyzer) | Включает автономные (NetLens300 - для TokenRing и Ethernet) и распределенные анализаторы (NetLensProbe для сложных составных сетей). Поддерживаются стеки SMB/NetBIOS, IPX/SPX, TCP/IP, AppleTalk, BanyanVines,DECnet, XNS, SNA, OSI. Реализован в виде нескольких задач, допускающих сбор статистики в фоновом режиме. Снабжен средствами обеспечения безопасности. |
| Azure Technologies | LAN-Pharaoh | Выпускается в виде специализированного аппаратно-программного комплекса: сетевая плата на основе RISC-процессора и 1 Мб ОЗУ. Для TokenRing и Ethernet выполняется полнофункциональный анализ всех возникающих ошибок. Поддерживаются стеки SMB/NetBIOS, IPX/SPX, TCP/IP, AppleTalk, BanyanVines, DECnet, XNS, SNA. Возможен ограниченный анализ составных сетей. |
| Hewlett-Packard | Network Advisor | Выполнен в виде специализированного устройства. Анализирует сети TokenRing и Ethernet. Имеет мощную экспертную систему. Средства отображения результатов измерений на экране имитируют шкалы измерительных приборов. Поддерживаются стеки SMB/NetBIOS, IPX/SPX, TCP/IP, DECnet, XNS, SNA |
| Network Communication | LANalyzer | Разработан в 1984 году, лицензирован у компании Novell. Дополнен устройством удаленного мониторинга NetworkProbe, работающим в комплексе с автономным LANalyzer . LANalyzer является полнофункциональным высокопроизводительным анализатором протоколов. Может поставляться в виде комплекта "сетевая карта и ПО". Поддерживает топологии Ethernet и TokenRing и стеки SMB/NetBIOS, IPX/SPX, TCP/IP, AppleTalk, BanyanVines,DECnet, XNS, SNA, OSI. |
Тестеры
Тестеры кабельных систем - наиболее простые и дешевые приборы для диагностики кабеля. Они позволяют определить непрерывность кабеля, однако, в отличие от кабельных сканеров, не дают ответа на вопрос о том, в каком месте произошел сбой.
Типичные ошибки при работе протоколов
Кроме явных ошибок в работе сети, проявляющихся в появлении кадров с некорректными значениями полей, существуют ошибочные ситуации, являющиеся следствием несогласованной установки параметров протоколов в разных узлах или портах сети. Ввиду большого количества протоколов, применяемых в локальных сетях на различных уровнях стека, а также большого количества их параметров, невозможно описать все встречающиеся на практике ситуации рассогласования. Ниже приводятся только некоторые из них.
Другой причиной некорректной работы протоколов может быть несогласованность протоколов разного уровня в одном и том же узле, например, протоколов FDDI и IPX, разработанные в расчете на различные интерфейсы межуровневого взаимодействия в стеке, FDDI - а интерфейс NDIS, а IPX - на интерфейс ODI. Необходимо отметить, что само по себе использование различных интерфейсов между аналогичными протоколами в разных узлах сети не препятствует их нормальному взаимодействию, так как обмениваются данными по сети соответствующие протоколы, а не интерфейсы (рис. 2.16).

Рис. 2.16. Использование различных интерфейсов между протоколами соседних уровней
Типичные ошибочные ситуации: влияние на производительность и диагностика
Ошибки в работе программного и аппаратного обеспечения сети обычно оказывают непосредственное и значительное влияние на производительность сети, так как время, затрачиваемое на ликвидацию последствий ошибок, является потерянным для выполнения нормальных операций.
2.4.1. Типичные ошибки в кадрах
Типы узлов
Система COMNETIII оперирует с узлами трех типов - процессорными узлами, узлами-маршрутизаторами и коммутаторами. Узлы могут присоединяться с помощью портов к коммуникационным каналам любого типа, от каналов локальных сетей до спутниковых линий связи. Узлы и каналы могут характеризоваться средним временем наработки на отказ и средним временем восстановления для моделирования надежности сети.
В COMNETIII моделируется не только взаимодействие компьютеров по сети, но и процесс разделения процессора каждого компьютера между его приложениями. Работа приложения моделируется с помощью команд нескольких типов, в том числе команд обработки данных, отправки и чтения сообщений, чтения и записи данных в файл, установления сессий и приостановки программы до получения сообщений. Для каждого приложения задается так называемый репертуар команд.
Узлы-маршрутизаторы могут моделировать работу маршрутизаторов, коммутаторов, мостов, концентраторов и любых устройств, которые имеют разделяемую внутреннюю шину, с помощью которой пакеты передаются между портами. Шина характеризуется пропускной способностью и количеством независимых каналов. Узел-маршутизатор обладает также всеми характеристиками процессорного узла, так что он может выполнять приложения, которые, например, обновляют таблицы маршрутизации или рассылают маршрутную информацию по сети. Неблокирующие коммутационные узлы могут моделироваться путем задания количества независимых каналов, равного числу модулей коммутатора. Библиотека COMNETIII включает большое количество описаний конкретных моделей маршрутизаторов с параметрами, основанными на результатах тестирования в Harvard NetworkDeviceTestLab.
Узел-коммутатор моделирует работу коммутаторов, а также маршрутизаторов, концентраторов и других устройств, которые передают пакеты с входного порта на выходной с незначительной задержкой.
Требования к пропускной способности моста
До сих пор мы предполагали, что при использовании моста для связи двух сегментов вместо повторителя общая производительность сети всегда повышается, так как уменьшается количество узлов в каждом сегменте и загрузка сегмента уменьшается на ту долю трафика, которая теперь является внутренним трафиком другого сегмента. Это дейсвительно так, но при условии, что мост передает межсегментный трафик без значительных задержек и без потерь кадров. Однако, анализ рассмотренного алгоритма работы моста говорит о том, что мост может и задерживать кадры, и, при определенных условиях, терять их. Задержка, вносимая мостом, равна по крайней мере времени записи кадра в буфер. Как правило, после записи кадра на обработку адресов также уходит некоторое время, особенно если размер адресной таблицы велик. Поэтому задержка увеличивается на время обработки кадра.
Время обработки кадра влияет не только на задержку, но и на вероятность потери кадров. Если время обработки кадра окажется меньше интервала до поступления следующего кадра, то следующий кадр будет помещен в буфер и будет ожидать там, пока процессор моста не освободится и не займется обработкой поступившего кадра. Если средняя интенсивность поступления кадров будет в течение длительного времени превышать производительность моста, то есть величину, обратную среднему времени обработки кадра, то буферная память, имеющаяся у моста для хранения необработанных кадров, может переполниться. В такой ситуации мосту некуда будет записывать поступающие кадры, и он начнет их терять, то есть просто отбрасывать.
Потеря кадра - ситуация очень нежелательная, так как ее последствия протоколами локальных сетей не ликвидируются. Потеря кадра будет исправлена только протоколами транспортного или прикладного уровней, которые заметят потерю части своих данных и организуют их повторную пересылку. Однако, при регулярных потерях кадров канального уровня производительность сети может уменьшиться в несколько раз, так как тайм-ауты, используемые в протоколах верхних уровней, существенно превышают времена передачи кадров на канальном уровне, и повторная передача кадра может состояться через десятки секунд.
Для предотвращения потерь кадров мост должен обладать производительностью, превышающей среднюю интенсивность межсегментного трафика, и большой буфер для хранения кадров, передаваемых в периоды пиковой нагрузки.
Для того, чтобы мост повышал, а не понижал пропускную спосбность сети, всегда должно выполняться следующее правило:
Скорость выполнения мостом операции передачи кадров между любыми двумя его портами (эта операция называется forwarding) должна быть всегда выше, чем средняя интенсивность трафика, существующего между соединяемыми этими портами сегментами сети.
В локальных сетях часто оказывается справедливым эмпирическое правило 80/20, говорящее о том, что при правильном разбиении сети на сегменты 80% трафика оказывается внутренним трафиком сегмента, и только 20% выходит за его пределы. Если считать, что это правило действует по отношению к конкретной сети, то мост должен обладать производительностью выполнения операции forwarding в 20 % от максимальной пропускной способности сегмента Ethernet, то есть производительностью 0.2х14880 = 3000 кадра в секунду. Обычно, локальные мосты обладают производительностью от 3000 кадров в секунду и выше.
Однако, гарантий на доставку кадров в любых ситуациях мост, в отличие от повторителя, не дает. Это его принципиальный недостаток, с которым приходится мириться.
Для того, чтобы выяснить возможность успешного применения моста в сети, необходимо предварительно замерить с помощью анализатора протоколов или же системы управления сетью матрицу трафика между узлами сети. Эта информация позволит понять уровень межсегментного трафика при разделении сети на сегменты и сравнить ее с производительностью моста.
Управление устройствами в реальном масштабе времени
Optivity включает также развитые средства для управления и контроля концентраторами на уровне портов в реальном масштабе времени. Запатентованный графический интерфейс ExpandedView обеспечивает точное текущее изображение выбранного концентратора, со всеми установленными в него модулями и активными светодиодами. Администратор может получить разнообразную информацию с помощью пунктов меню Fault, Performance или Configuration вплотьдоуровняпорта. Можно также разрешить или запретить соединения, или же временно изолировать порт для более точного сетевого управления.
Упреждающий анализ ошибок и проблем
Система Optivity включает средства, позволяющие обнаруживать условия возникновения проблем, упреждая их отрицательное воздействие на производительность сети.
Пороговые значения позволяют администратору установить соответствующие уровни для специфических ошибок, загруженности и активности сегментов и узлов сетей Ethernet и TokenRing. При достижении порога система автоматически генерирует сообщение об этом событии для администратора. Эти RMON-события могут также инициировать определенные администратором действия, такие как изоляция порта, подача звукового сигнала тревоги, отправка сообщения по электронной почте или звонок по телефону.
Влияние маршрутизаторов на производительность сети
Маршрутизаторы, подобно мостам и коммутаторам, изолируют трафик одной части сети от другой и, тем самым, повышают пропускную способность сети в целом. При этом степень изоляции сетей более высокая, чем при использовании мостов и коммутаторов, так как маршрутизаторы не передают между сетями широковещательный трафик и кадры с неизвестными адресами назначения.
Как и в случае применения мостов/коммутаторов, использование маршрутизаторов может и уменьшить пропускную способность. Это может произойти в том случае, если производительность маршрутизатора окажется меньше средней интесивности межсетевого трафика. Обычно производительность маршрутизатора существенно меньше производительности коммутатора - средний маршрутизатор тратит на обработку одного пакета в 5 - 10 раз больше времени, чем средний коммутатор. Поэтому маршрутизаторы обычно применяют для соединения таких фрагментов сетей, которые являются достаточно обособленными и порождают не очень интенсивный межсетевой трафик.
Все соотношения, приведенные выше, которые были получены при обсуждении требований к производительности коммутаторов, справедливы и для маршрутизаторов.
Влияние на производительность алгоритма доступа к разделяемой среде и коэффициента использования
Время доступа к среде определяется как логикой самого протокола, так и степенью загруженности сети. В локальных сетях пока доминируют разделяемые среды передачи данных, требующие выполнения определенной процедуры для получения права передачи кадра. В протоколах Ethernet и FastEthernet используется алгоритм случайного доступа с обнаружением коллизий CSMA/CD, а в протоколах TokenRing и FDDI - алгоритм, основанный на детерминированной передаче токена доступа. Новый стандарт 100VG-AnyLAN использует алгоритм доступа DemandPriority, при котором решение о предоставлении доступа принимается центральным элементом - концентратором.
Время доступа к среде складывается из номинального времени доступа и времени ожидания доступа. Номинальное время доступа определяется как время доступа к незагруженной среде, когда узел не конкурирует с другими узлами. Номинальное время доступа к незанятой среде протоколов TokenRing и FDDI в 5 - 10 раз превышает соответствующее время протокола Ethernet, так как в незанятой сети Ethernet станция практически мгновенно получает доступ, а в сети TokenRing она должна дождаться прихода маркера доступа.
Другая составляющая времени доступа к среде - время ожидания - зависит от задержек, возникающих из-за разделения передающей среды между несколькими одновременно работающими станциями. Время ожидания зависит как от алгоритма доступа, так и от степени загруженности среды, причем зависимость времени ожидания от степени загрузки (коэффициента использования) сети для большинства протоколов носит экспоненциальный характер.
Наиболее чувствителен к загруженности среды метод доступа протокола Ethernet, для которого резкий рост времени ожидания начинается уже при величинах коэффициента использования в 30% - 50%. Поэтому для нормальной работы сети сегменты Ethernet не рекомендуется нагружать свыше 30% (рис. 2.2). Даже если среднее значение коэффициента использования находится в норме, но имеются пиковые значения, превышающие 60%, то это является свидетельством того, что сеть работает ненормально и требует проведения дополнительных исследований.

Рис. 2.2. Характеристики пропускной способности сети Ethernet
Сети TokenRing и FDDI можно эксплуатировать и при больших значениях коэффициента использования - до 60%, а иногда и до 80%. Компания Hewlett-Packard, продвигающая на рынок технологию 100VG-AnyLAN, считает, что эти сети могут нормально работать и при загрузке в 95%.
На рисунке 2.3 помещены графики зависимости среднего времени ожидания доступа к среде для протоколов Ethernet и TokenRing от коэффициента использования сети. Графики показывают, что при близком общем характере зависимости резкое возрастание времени ожидания наступает в сетях Ethernet гораздо раньше, чем в сетях TokenRing.
Рис. 2.3. Сравнение задержек доступа к среде в сетях Ethernet и TokenRing
Влияние на производительность сети типа коммуникационного протокола и его параметров
Задача выбора коммуникационных протоколов может решаться относительно независимо для канального уровня с одной стороны (Ethernet, TokenRing, FDDI, FastEthernet, ATM) и пары "сетевой - транспортный протокол" с другой стороны (IPX/SPX, TCP/IP, NetBIOS).
Каждый протокол имеет свои особенности, предпочтительные области применения и настраиваемые параметры, что и дает возможность за счет выбора и настройки протокола влиять на производительность и надежность сети. Настройка протокола может включать в себя изменение таких параметров как:
максимально допустимый размер кадра, величины тайм-аутов (в том числе время жизни пакета), для протоколов, работающих с установлением соединений - размер окна неподтвержденных пакетов, а также некоторых других.
2.1.1. Номинальная и эффективная пропускная способность протокола
При настройке сети необходимо различать номинальную и эффективную пропускные способности протокола. Под номинальной пропускной способностью обычно понимается битовая скорость передачи данных, поддерживаемая на интервале передачи одного пакета. Эффективная пропускная способность протокола - это средняя скорость передачи пользовательских данных, то есть данных, содержащихся в поле данных каждого пакета. В общем случае эффективная пропускная способность протокола будет ниже номинальной из-за наличия в пакете служебной информации, а также из-за пауз между передачей отдельных пакетов.
Рассмотрим подробнее разницу между номинальной и эффективной пропускными способностями на примере протокола Ethernet.
На рисунке 2.1 приведена временная диаграмма передачи кадров Ethernet минимальной длины. Номинальная пропускная способность протокола Ethernet составляет 10 Мб/с, что означает, что биты внутри кадра передаются с интервалом в 0.1 мкс. Кадр состоит из 8 байт преамбулы, 14 байт служебной информации - заголовка, 46 байт пользовательских данных и 4 байт контрольной суммы, всего - 72 байта или 576 бит. При номинальной пропускной способности 10 Мб/c время передачи одного кадра минимальной длины составляет 57.6 мкс.

Рис. 2.1. Временная диаграмма передачи кадров Ethernet
По стандарту между кадрами должна выдерживаться технологическая пауза в 9.6 мкс. Поэтому период повторения кадров составляет 57.6 + 9.6 = 67.2 мкс. Отсюда эффективная пропускная способность протокола Ethernet при использовании кадров минимальной длины составляет 46 х 8/67.2 = 5.48 Мб/c.
Реальная пропускная способность по пользовательским данным в сети может быть только меньше приведенного выше значения 5.48 Мб/с (для кадров данного размера). Отношение реальной пропускной способности сегмента, канала или устройства к его эффективной пропускной способности называется коэффициентом использования (utilization) сегмента, канала или устройства соответственно.
Эффективная пропускная способность существенно отличается от номинальной пропускной способности протокола, что говорит о необходимости ориентации именно на эффективную пропускную способность при выборе типа протокола для того или иного сегмента сети. Например, для протокола Ethernet эффективная пропускная способность составляет примерно 70% от номинальной, а для протокола FDDI - около 90%.
Пропускная способность протокола часто измеряется и в количестве кадров, передаваемых в секунду. Нетрудно подсчитать, что для протокола Ethernet эта характеристика для кадров минимальной длины составляет 14880 К/с. Понятно, что при измерении пропускной способности в кадрах в секунду, нет смысла разграничивать номинальную и эффективную пропускную способности.
Почти все протоколы канального уровня локальных сетей подерживают одну фиксированную номинальную пропускную способность: Ethernet - 10 Мб/с, TokenRing - 16 Мб/c (4 Мб/c может поддерживаться для совместимости со старым оборудованием), FDDI, FastEthernet и 100VG-AnyLAN - 100 Мб/c. Только протокол АТМ может работать с различными номинальными битовыми скоростями - 25, 155 и 622 Мб/c, хотя переход от одной скорости к другой требует замены сетевых адаптеров или интерфейсов коммутаторов или маршрутизаторов.
Поэтому, если для улучшения работы сети мы хотим варьировать номинальной пропускной способностью протокола, то для этого нам потребуется заменять один протокол на другой - мера возможная, но требующая значительных материальных и физических затрат.
Влияние размера кадра и пакета на производительность сети
Размер пакета может существенным образом повлиять на эффективную пропускную способность протокола, а значит и на производительность сети. Выясним на примере, как изменится эффективная пропускная способность протокола Ethernet, если вместо кадров минимальной длины при обмене данными будут использоваться кадры максимальной длины с полем данных в 1500 байт, как это определено в стандарте.
Общая длина кадра вместе с преамбулой, заголовком и контрольной суммой составит в этом случае 8+14+1500+4 = 1526 байт или 12208 бит. Время передачи такого кадра составит 1220.8 мкс, а период повторения кадров - 1220.8 +9.6 = 1230.4 мкс.
Эффективная пропускная способность при этом равна (1500 х 8)/1230.4 = 9.75 Мб/c.
Полученный результат говорит о том, что при увеличении размера пакета эффективная пропускная способность протокола Ethernet существенно, почти в 2 раза, увеличилась - с 5.48 Мб/с до 9.75 Мб/с (рис. 2.2). Аналогичный рост характерен для всех протоколов и это говорит о том, что размер пакета - один из тех параметров, которые в наибольшей степени влияют на производительность сети.
Размер пакета конкретного протокола обычно ограничен максимальным значением поля данных (MaximumTransferUnit, MTU), определенным в стандарте на протокол.
Протоколы локальных сетей имеют следующие значения MTU:
Ethernet, Fast Ethernet - 1500 байт; TokenRing 16 - 16 Kбайт (обычно по умолчанию устанавливается значение 4K, но его можно увеличить); FDDI - 4Kбайта; 100VG-AnyLAN - 1500 байт при использовании кадров Ethernet и 16K при использовании кадров TokenRing; ATM - 48 байт.
Протоколы верхних уровней, начиная с сетевого, инкапсулируют свои пакеты в кадры протоколов канального уровня, поэтому ограничения, существующие на канальном уровне, являются общими ограничениями максимального размера пакета для протоколов всех уровней.
Необходимо отметить, что повышение размера кадра увеличивает пропускную способность сети только в том случае, когда данные в сети редко искажаются или теряются, то есть при устойчивой, надежной работе сети.
В противном случае увеличение размера пакета может привести не к увеличению, а к снижению пропускной способности, так как сеть будет повторно передавать большие порции информации. Для каждого уровня искажений данных можно подобрать рациональный размер пакета, для которого пропускная способность сети будет максимальной.
Максимальный размер пакета только создает предпосылки для повышения пропускной способности, так как в конечном счете от приложений зависит, будет ли использована данная максимальная величина поля данных или нет. Если, например, приложение ведет работы с базой данных и пересылает на сервер SQL-запросы, получая в ответ по одной короткой записи, то максимальный размер поля данных в 4 или 16 Кбайт никак не поможет повысить пропускную способность сети. При обращении же приложения к файловому серверу для пересылки мультимедийного файла размером в несколько мегабайт наличие возможности пересылать файл частями по 16К безусловно повысит пропускную способность сети по сравнению с вариантом пересылки файла частями по 1500 байт.
Настройка размера пересылаемых порций данных обычно происходит на транспортном уровне стека протоколов и, возможно, на прикладном, если разработчик приложения предусмотрел такую возможность.
Работа с пакетами больших размеров повышает производительность сети не только за счет уменьшения накладных расходов на служебную информацию заголовка. При использовании больших пакетов повышается производительность коммуникационного оборудования, работающего с кадрами и пакетами, то есть мостов, коммутаторов и маршрутизаторов. Это происходит из за того, что при передаче одного и того же объема информации число используемых больших пакетов существенно меньше, чем число маленьких, а так как коммуникационное оборудование тратит определенное время на обработку каждого пакета, то и временные потери продвижения пакетов мостами, коммутаторами и маршрутизаторами при использовании больших пакетов будут меньше.
Влияние широковещательного служебного трафика на производительность сети
2.2.1. Назначение широковещательного трафика
Пропускная способность любого канала локальной сети ограничивается максимальной эффективной пропускной способностью используемого канального протокола. Если же часть этой пропускной способности используется не для передачи пользовательских данных, а для передачи служебного трафика, то эффективная пропускная способность сети еще уменьшается. Обычно некоторую часть доступной пропускной способности сети отнимает у пользовательских данных широковещательный служебный трафик, который является неотъемлемой частью практически всех стеков протоколов, работающих в локальных сетях.
Широковещательная рассылка кадров и пакетов используется протоколами для того, чтобы в сети можно было бы находить ресурсы не с помощью запоминания их числовых адресов, а путем использования более удобных для пользователя символьных имен. Еще одним удобным способом поиска ресурсов в сети является их автоматическое сканирование и предоставление пользователю списка обнаруженных ресурсов с символьными именами. Пользователь может просмотреть список текущих ресурсов сети - файл-серверов, серверов баз данных или разделяемых принтеров - и выбрать любой из них для использования.
Оба приведенных способа работы пользователя с ресурсами обычно основываются на том или ином виде широковещательного трафика, когда узел, осуществляющий просмотр сети, отправляет в нее запросы с широковещательным адресом, опрашивающие наличие в сети тех или иных серверов. Получив такой запрос, сервер отвечает запрашивающему узлу направленным пакетом, в котором сообщает свой точный адрес и описывает предоставляемые сервером услуги.
Влияние топологии связей и производительности
Возможность изменения топологии связей между узлами сети предоставляет сетевому интегратору широкие возможности для повышения пропускной способности как сети в целом так и ее отдельных участков. Даже при фиксированных пропускных способностях каналов связей наличие двух альтернативных каналов между какими-либо узлами сразу же в два раза повышает пропускную способность сети при взаимодействии этих узлов.
Локальные сети, использующие только повторители/концентраторы, должны строиться по вполне определенной топологии - общей шины, кольца или звезды, которая определяется используемой базовой сетевой технологией (Ethernet, TokenRing и т.п.).
Однако при использовании мостов, коммутаторов или маршрутизаторов появляется возможность использовать более сложные топологии, отличающиеся от стандартных. Выбор подходящей топологии сети может решить многие проблемы узких (в отношении пропускной способности) мест сети. Это связано не только с наличием дополнительных каналов связи, но и с тем обстоятельством, что сеть образует в таком случае не одну общую среду, разделяемую между всеми узлами сети, а несколько таких сред, пропускная способность которых разделяется уже только между узлами данного сегмента сети.
Безусловно, большое влияние на пропускную способность сети имеет и производительность таких коммуникационных устройств как мосты, коммутаторы и маршрутизаторы. Эта производительность должна быть достаточной для передачи межсегментного или межсетевого трафика между частями сети, которые образуются в результате установки в сеть устройств данного типа. Потери кадров или пакетов мостами, коммутаторами или маршрутизаторами могут приводить к значительному снижению пропускной способности сети, особенно если восстановление утерянных пакетов осуществляется пртоколами с большими значениями тайм-аута ожидания квитанций, как это было показано в разделе2.1.6.
2.3.1. Разделяемая среда передачи как причина снижения производительности сети
Повторители и концентраторы локальных сетей реализуют базовые технологии, разработанные для разделяемых сред передачи данных.
Классическим представителем такой технологии является технология Ethernet на коаксиальном кабеле. В такой сети все компьютеры сети разделяют во времени единственный канал связи, образованный сегментом коаксиального кабеля.
При передаче каким-нибудь компьютером кадра данных все остальные компьютеры принимают его по общему коаксиальному кабелю, находясь с передатчиком в постоянном побитном синхронизме. На время передачи этого кадра никакие другие обмены информации в сети не разрешаются. Способ доступа к общему кабелю управляется несложным распределенным механизмом арбитража - каждый компьютер имеет право начать передачу кадра, если на кабеле отсутствуют информационные сигналы, а при одновременной передаче кадров несколькими компьютерами схемы приемников узлов умеют распознавать и обрабатывать эту ситуацию, называемую коллизией. Обработка коллизии также несложна - все передающие узлы прекращают выставлять биты своих кадров на кабель и повторяют попытку передачи кадра через случайный промежуток времени.
При подключении к общему каналу сети Ethernet каждый узел пользуется его пропускной способностью 10 Мб/с в течение только некоторой доли общего времени работы сети. Соответственно, на узел приходится эта же доля пропускной способности канала. Даже если упрощенно считать, что все узлы получают равные доли времени работы канала и непроизводительные потери времени отстутствуют, то при наличии в сети N узлов на один узел приходится только 10/N Мб/с пропускной способности. Очевидно, что при больших значениях N пропускная способность, выделяемая каждому узлу, оказывается настолько малой величиной, что нормальная работа приложений и пользователей становится невозможной - задержки доступа к сетевым ресурсам превышают тайм-ауты приложений, а пользователи просто отказываются так долго ждать отклика сети.
Случайный характер алгоритма доступа к среде передачи данных, принятый в технологии Ethernet, еще усугубляет ситуацию. Если запросы на доступ к среде генерируются узлами в случайные моменты времени, то при большой их интенсивности вероятность возникновения коллизий также возрастает и приводит к неэффективному использованию канала: время обнаружения коллизии и время ее обработки составляют непроизводительные затраты.
Доля времени, в течение которого канал предоставляется в распоряжение конкретному узлу, становится еще меньше.
До недавнего времени в локальных сетях редко использовались мультимедийные приложения, перекачивающие большие файлы данных, нередко состоящие из нескольких десятков мегабайт. Приложения же, работающие с алфивитно-цифровой информацией, не создавали значительного трафика. Поэтому долгое время для сегментов Ethernet было действительным эмпирическое правило - в разделяемом сегменте не должно быть больше 30 узлов. Теперь ситуация изменилась и нередко 3-4 компьютера полностью загружают сегмент Ethernet с его максимальной пропускной способностью в 10 Мб/с или же 14880 кадров в секунду.
Ограничения, связанные с возникающими коллизиями и большим временем ожидания доступа при значительной загрузке разделяемого сегмента, чаще всего оказываются более серьезными, чем ограничение на максимальное количество узлов, определенное в стандарте из соображений устойчивой передачи электрических сигналов в кабелях.
Техногия Ethernet была выбрана в качестве примера при демонстрации ограничений, присущих технологиям локальных сетей, так как в этой технологии ограничения проявляются наиболее ярко, а их причины достаточно очевидны. Однако подобные ограничения присущи и всем остальным технологям локальных сетей, так как они опираются на использование среды передачи данных как одного разделяемого ресурса. Кольца TokenRing и FDDI также могут использоваться узлами сети только в режиме разделяемого ресурса. Отличие от канала Ethernet здесь состоит только в том, что маркерный метод доступа определяет детерминированную очередность предоставления доступа к кольцу, но по-прежнему при предоставлении доступа одного узла к кольцу все остальные узлы не могут передавать свои кадры и должны ждать, пока владеющий правом доступа узел не завершит свою передачу.
Общее ограничение локальных сетей, построенных только с использованием повторителей и концентраторов, состоит в том, что общая производительность такой сети всегда фиксирована и равна максимальной производительности используемого протокола.И эту производительность можно повысить только перейдя к другой технологии, что связано с дорогостоящей заменой всего оборудования.
Рассмотренные ограничения являются платой за преимущества, которые дает использование разделяемых каналов в локальных сетях. Эти преимущества существенны, недаром технологии такого типа существуют уже около 20 лет.
К преимуществам нужно отнести в первую очередь:
простоту топологии сети; гарантию доставки кадра адресату при соблюдении ограничений стандарта и корректно работающей аппаратуре; простоту протоколов, обеспечившую низкую стоимость сетевых адаптеров, повторителей и концентраторов.
Однако начавшийся процесс вытеснения повторителей и концентраторов коммутаторами говорит о том, что приоритеты изменились, и за повышение общей пропускной способности сети пользователи готовы пойти на издержки, связанные с приобретением коммутаторов вместо концентраторов.
Время жизни пакета
Параметр, который определяет, как долго может путешествовать пакет по составной сети, имеется во многих протоколах сетевого уровня. В протоколе IP этот параметр называется Time-To-Live, TTL (Время жизни), а в протоколе IPX - Distance (Расстояние). Этот параметр используется для того, чтобы маршрутизаторы, обрабатывающие заголовки сетевого протокола, имели информацию о том, как долго перемещался пакет по сети до того, как прибыл в данный маршрутизатор. Если пакет путешествует по сети слишком долго, то имеется большая вероятность, что он по каким-то причинам "заблудился". Причинами некорректного перемещения пакетов по сети могут быть неверные значения таблиц маршрутизации в некоторых маршрутизаторах, которые в свою очередь являются следствием ошибок администраторов при ручном формировании таблиц, либо несовершенством протоколов обмена маршрутной информации. Например, протокол RIP иногда неустойчиво работает при изменениях состояния сети - отказе каналов связи, отказе, появлении или отключении других маршрутизаторов и т.п.
"Заблудившиеся" пакеты удаляются маршрутизаторами из сети для того, чтобы на них впустую не тратилась часть пропускной способности каналов и маршрутизаторов.
В протоколе IP поле TTL устанавливается узлом-отправителем в некоторое ненулевое значение, а маршрутизаторы при продвижении пакета уменьшают его, обычно на 1. Пакет удаляется из сети в том случае, если после уменьшения значение поля TTL становится равным 0.
В протоколе IPX поле Distance обрабатывается по-другому - узел-отправитель устанавливает его в 0, а каждый маршрутизатор наращивает его на 1. Пакет удаляется из сети при достижении этим полем значения 16.
Начальное значение поля времени жизни в сети, работающей по протоколу IP, является настраиваемым параметром, который влияет на производительность и надежность работы сети. При увеличении начального значения поля TTL пакеты могут пересекать большее число промежуточных сетей, следовательно, потенциально вероятность успешной доставки пакета любому абоненту большой сети возрастает, а, значит, производительность может повыситься за счет уменьшения доли "недошедших", отброшенных по дороге пакетов. Однако при этом в сети может существовать большое число "заблудившихся" пакетов, которые будут снижать производительность сети.
В результате простых рекомендаций по выбору начального значения поля TTL в протоколе IP не существует - это значение подлежит настройке путем натурного экспериментирования или моделирования.
