Агенты RMON
Новейшим добавлением к функциональным возможностям SNMP является спецификация RMON, которая обеспечивает удаленное взаимодействие с базой MIB. До появления RMON протокол SNMP не мог использоваться удаленным образом, он допускал только локальное управление устройствами. База RMONMIB обладает улучшенным набором свойств для удаленного управления, так как содержит агрегированную информацию об устройстве, что не требует передачи по сети больших объемов информации. Объекты RMONMIB включают дополнительные счетчики ошибок в пакетах, более гибкие средства анализа графических трендов и статистики, более мощные средства фильтрации для захвата и анализа отдельных пакетов, а также более сложные условия установления сигналов предупреждения. Агенты RMONMIB более интеллектуальны по сравнению с агентами MIB-I или MIB-II и выполняют значительную часть работы по обработке информации об устройстве, которую раньше выполняли менеджеры. Эти агенты могут располагаться внутри различных коммуникационных устройств, а также быть выполнены в виде отдельных программных модулей, работающих на универсальных ПК и ноутбуках (примером может служить LANalyzerNovell).
Объекту RMON присвоен номер 16 в наборе объектов MIB, а сам объект RMON объединяет 10 групп следующих объектов:
Statistics - текущие накопленные статистические данные о характеристиках пакетов, количестве коллизий и т.п. History - статистические данные, сохраненные через определенные промежутки времени для последующего анализа тенденций их изменений. Alarms - пороговые значения статистических показателей, при превышении которых агент RMON посылает сообщение менеджеру. Host - данных о хостах сети, в том числе и об их MAC-адресах. HostTopN - таблица наиболее загруженных хостов сети. TrafficMatrix - статистика об интенсивности трафика между каждой парой хостов сети, упорядоченная в виде матрицы. Filter - условия фильтрации пакетов. PacketCapture - условия захвата пакетов. Event - условия регистрации и генерации событий.
Данные группы пронумерованы в указанном порядке, поэтому, например, группа Hosts имеет числовое имя 1.3.6.1.2.1.16.4.
Десятую группу составляют специальные объекты протокола TokenRing.
Всего стандарт RMONMIB определяет около 200 объектов в 10 группах, зафиксированных в двух документах - RFC 1271 для сетей Ethernet и RFC 1513 для сетей TokenRing.
Отличительной чертой стандарта RMONMIB является его независимость от протокола сетевого уровня (в отличие от стандартов MIB-I и MIB-II, ориентированных на протоколы TCP/IP). Поэтому, его удобно использовать в гетерогенных средах, использующих различные протоколы сетевого уровня.
Агенты SNMP
На сегодня существует несколько стандартов на базы данных управляющей информации. Основными являются стандарты MIB-I и MIB-II, а также версия базы данных для удаленного управления RMONMIB. Кроме этого, существуют стандарты для специальных MIB устройств конкретного типа (например, MIB для концентраторов или MIB для модемов), а также частные MIB конкретных фирм-производителей оборудования.
Первоначальная спецификация MIB-I определяла только операции чтения значений переменных. Операции изменения или установки значений объекта являются частью спецификаций MIB-II.
Версия MIB-I (RFC 1156) определяет до 114 объектов, которые подразделяются на 8 групп:
System - общие данные об устройстве (например, идентификатор поставщика, время последней инициализации системы). Interfaces - описываются параметры сетевых интерфейсов устройства (например, их количество, типы, скорости обмена, максимальный размер пакета). AddressTranslationTable - описывается соответствие между сетевыми и физическими адресами (например, по протоколу ARP). InternetProtocol - данные, относящиеся к протоколу IP (адреса IP-шлюзов, хостов, статистика об IP-пакетах). ICMP - данные, относящиеся к протоколу обмена управляющими сообщениями ICMP. TCP - данные, относящиеся к протоколу TCP (например, о TCP-соединениях). UDP - данные, относящиеся к протоколу UDP (число переданных, принятых и ошибочных UPD-дейтаграмм). EGP - данные, относящиеся к протоколу обмена маршрутной информацией ExteriorGatewayProtocol, используемому в сети Internet (число принятых с ошибками и без ошибок сообщений).
Из этого перечня групп переменных видно, что стандарт MIB-I разрабатывался с жесткой ориентацией на управление маршрутизаторами, поддерживающими протоколы стека TCP/IP.
В версии MIB-II (RFC 1213), принятой в 1992 году, был существенно (до 185) расширен набор стандартных объектов, а число групп увеличилось до 10.
Анализ и управление производительностью на основе стандарта RMON
В состав Optivity входят приложения, поддерживающие передовой промышленный стандарт RMON, который обеспечивает для сетей Ethernet и TokenRing средства обнаружения отказов и сбоев, анализа производительности и потенциальных проблем.
DecodeMan - утилита, разработанная совместно BayNetworks и NetworkGeneral, позволяющая декодировать и анализировать трафик в удаленных локальных сетях. DecodeMan основан на продукте FoundationManager компании NetworkGeneral (одного из лидеров в производстве сетевых анализаторов) и позволяет полное декодирование пакетов на всех 7 уровнях для большинства основных протоколов (включая IP, IPX, AppleTalk, DECnet, VINES, OSI, SNA и NetBIOS). С помощью этой утилиты можно анализировать и разрешать проблемы, возникающие в удаленных сегментах, сидя за центральной консолью системы управления.
DecodeMan использует возможности "зонд-в-концентраторе", предоставляемые агентами типа AdvancedAnalyzer, встроенными в устройства BayNetworks. NodalView - средство для сбора детальной RMON-статистики об ошибках и производительности всех узлов сегмента Ethernet или кольца TokenRing. Конечные станции отображаются в компактном виде в форме списка, позволяя администратору быстро определить их статус и определить потенциальные проблемные узлы. Функции сортировки дают возможность упорядочить узлы по различным показателям - уровню трафика, интенсивности ошибок, IP-адресам и другим, позволяя быстро обнаружить узлы, создающие наибольший трафик, чаще генерирующие ошибочные пакеты, "дыры" в последовательности IP-адресов и другие проблемы. Информация о производительности сегмента или отдельного узла может быть представлена в виде графика, круговой или ступенчатой гистограммы.
Анализатор протоколов LANalyser компании Novell
LANalyser был разработан в 1984 году компанией Excelan, которая позже вошла в состав Novell. В настоящее время лицензией на технологию LANalyser обладаеткомпания Network Communications Corp. LANalyser является полнофункциональным высокопроизводительным анализатором протоколов, способным выполнить полное декодирование для большинства протоколов и сетевых технологий (в том числе Ethernet, TokenRing на 4 и 16 Мб/с).
LANalyser поставляется в виде сетевой платы и программного обеспечения, которые необходимо устанавливать на персональном компьютере, либо в виде ПК, с уже установленными платой и программным обеспечением.
LANalyser имеет развитый удобный интерфейс с пользователем, с помощью которого устанавливаются выбранный режим работы. Меню ApplicationLANalyser является основным средством настройки режима перехвата и содержит варианты выбора набора протоколов, фильтров, инициаторов, аварийных сигналов и т.д. Данный анализатор может работать с протоколами: NetBIOS, SMB, NCP, NCPBurst, TCP/IP, DECnet, BanyanVINES, AppleTalk, XNS, SunNFS, ISO, EGP, NIS, SNA и некоторыми другими. Из меню Application можно либо выбрать и сконфигурировать специальные тестовые комплекты приложений, либо выбрать один из заранее определенных тестовых комплектов приложений для TokenRing или Ethernet.
С помощью LANalyser могут быть определены до 9 каналов приема и до 6 каналов передачи. Канал приема - это в сущности фильтры для всей информации, которую пользователь желает получать в ходе сеанса анализа протокола. Каналы передачи позволяют сгенерировать в сети потоки данных заданной структуры.
Имеется возможность динамически модифицировать параметры тестового комплекта приложения. Используя удобный интерфейс вы можете, например, указать дисковый файл для регистрации основных статистических параметров собираемых данных или режим распечатки. LANalyser не располагает какими-либо средствами генерации отчетов, но файлы статистики можно импортировать в различные приложения.
В LANalyser предусмотрены следующие режимы отображения результатов анализа сети:
Режим глобального отображения предоставляет в распоряжение пользователя статистическую информацию о сети в целом - общее количество пакетов для каждого типа протоколов, процентное соотношение трафиков различного вида, в том числе широковещательного, трафика ошибочных пакетов и т.п. На этом же экране размещены диаграммы интенсивностей трафика различного вида. Режим раздельного отображения обеспечивает статистическую информацию по отдельным пакетам, захваченным по каналам приема. Режим отображения использования предоставляет в распоряжение пользователя универсальную картину использования всеми активными каналами полосы пропускания сети. Режим отображения станций выводит статистику по взаимодействию отдельных станций.
Функция DisplayPacketTrace позволяет просматривать перехваченные пакеты в общем хронологическом перечне или в детальном представлении пакетов. Находясь в этом режиме, можно просмотреть текущую трассировку или загрузить ранее выполненные трассировки с диска.
Функция TestNetworkCablingпозволяет выполнить серию сетевых тестов, в том числе базовый тест кабеля, тесты соединений и состояния кольца (для TokenRing).
Функция Utilities активизирует подменю, которое включает следующие утилиты, которые служат для адаптации того или иного прикладного тестового набора к потребностям пользователя:
Name - позволяет присваивать имена конкретным адресам Ethernet и TokenRing, Genname - автоматически генерирует файл наименований для ряда конкретных адресов узлов сети, Stats - позволяет просматривать сохраненный ранее файл, полученный в результате выполнения определенного теста в основных режимах отображения, Template - определяет шаблоны фильтров для задания каналов передачи и приема.
LANalyser обладает некоторыми возможностями, повышающими эффективность его работы в сетях Ethernet и TokenRing. В составе LANalyser поставляется тестовый комплект, называемый ERRMON, который настраивается таким образом, чтобы каналы приема могли автоматически фиксировать ту или иную типичную ошибку сети Ethernet или TokenRing.Другой тестовый набор, называемый SEGMENTS, предназначен для анализа сетей, построенных на основе мостов и коммутаторов.
В последнюю версию LANalyser включена также экспертная система, оказывающая пользователю помощь в поиске неисправностей.
Анализаторы протоколов
В ходе проектирования новой или модернизации старой сети часто возникает необходимость в количественном измерении некоторых характеристик сети таких, например, как интенсивности потоков данных по сетевым линиям связи, задержки, возникающие на различных этапах обработки пакетов, времена реакции на запросы того или иного вида, частота возникновения определенных событий и других характеристик.
Для этих целей могут быть использованы разные средства и прежде всего - средства мониторинга в системах управления сетью, которые уже обсуждались в предыдущих разделах. Некоторые измерения на сети могут быть выполнены и встроенными в операционную систему программными измерителями, примером тому служит компонента ОС WindowsNTPerformanceMonitor. Даже кабельные тестеры в их современном исполнении способны вести захват пакетов и анализ их содержимого.
Но наиболее совершенным средством исследования сети является анализатор протоколов. Процесс анализа протоколов включает захват циркулирующих в сети пакетов, реализующих тот или иной сетевой протокол, и изучение содержимого этих пакетов. Основываясь на результатах анализа, можно осуществлять обоснованное и взвешенное изменение каких-либо компонент сети, оптимизацию ее производительности, поиск и устранение неполадок. Очевидно, что для того, чтобы можно было сделать какие-либо выводы о влиянии некоторого изменения на сеть, необходимо выполнить анализ протоколов и до, и после внесения изменения.
Анализатор протоколов представляет собой либо самостоятельное специализированное устройство, либо персональный компьютер, обычно переносной, класса Notebook, оснащенный специальной сетевой картой и соответствующим программным обеспечением. Применяемые сетевая карта и программное обеспечение должны соответствовать топологии сети (кольцо, шина, звезда). Анализатор подключается к сети точно также, как и обычный узел. Отличие состоит в том, что анализатор может принимать все пакеты данных, передаваемые по сети, в то время как обычная станция - только адресованные ей.
Программное обеспечение анализатора состоит из ядра, поддерживающего работу сетевого адаптера и декодирующего получаемые данные, и дополнительного программного кода, зависящего от типа топологии исследуемой сети. Кроме того, поставляется ряд процедур декодирования, ориентированных на определенный протокол, например, IPX. В состав некоторых анализаторов может входить также экспертная система, которая может выдавать пользователю рекомендации о том, какие эксперименты следует проводить в данной ситуации, что могут означать те или иные результаты измерений, как устранить некоторые виды неисправности сети.
Несмотря на относительное многообразие анализаторов протоколов, представленных на рынке, можно назвать некоторые черты, в той или иной мере присущие всем им:
Пользовательский интерфейс. Большинство анализаторов имеют развитый дружественный интерфейс, базирующийся, как правило, на Windows или Motif. Этот интерфейс позволяет пользователю: выводить результаты анализа интенсивности трафика; получать мгновенную и усредненную статистическую оценку производительности сети; задавать определенные события и критические ситуации для отслеживания их возникновения; производить декодирование протоколов разного уровня и представлять в понятной форме содержимое пакетов. Буфер захвата. Буферы различных анализаторов отличаются по объему. Буфер может располагаться на устанавливаемой сетевой карте, либо для него может быть отведено место в оперативной памяти одного из компьютеров сети. Если буфер расположен на сетевой карте, то управление им осуществляется аппаратно, и за счет этого скорость ввода повышается. Однако это приводит к удорожанию анализатора. В случае недостаточной производительности процедуры захвата, часть информации будет теряться, и анализ будет невозможен. Размер буфера определяет возможности анализа по более или менее представительным выборкам захватываемых данных. Но каким бы большим ни был буфер захвата, рано или поздно он заполнится. В этом случае либо прекращается захват, либо заполнение начинается с начала буфера. Фильтры. Фильтры позволяют управлять процессом захвата данных, и, тем самым, позволяют экономить пространство буфера.
В зависимости от значения определенных полей пакета, заданных в виде условия фильтрации, пакет либо игнорируется, либо записывается в буфер захвата. Использование фильтров значительно ускоряет и упрощает анализ, так как исключает просмотр ненужных в данный момент пакетов. Переключатели - это задаваемые оператором некоторые условия начала и прекращения процесса захвата данных из сети. Такими условиями могут быть выполнение ручных команд запуска и остановки процесса захвата, время суток, продолжительность процесса захвата, появление определенных значений в кадрах данных. Переключатели могут использоваться совместно с фильтрами, позволяя более детально и тонко проводить анализ, а также продуктивнее использовать ограниченный объем буфера захвата. Поиск. Некоторые анализаторы протоколов позволяют автоматизировать просмотр информации, находящейся в буфере, и находить в ней данные по заданным критериям. В то время, как фильтры проверяют входной поток на предмет соответствия условиям фильтрации, функции поиска применяются к уже накопленным в буфере данным.
Методология проведения анализа может быть представлена в виде следующих шести этапов:
Захват данных. Просмотр захваченных данных. Анализ данных. Поиск ошибок. (Большинство анализаторов облегчают эту работу, определяя типы ошибок и идентифицируя станцию, от которой пришел пакет с ошибкой.) Исследование производительности. Рассчитывается коэффициент использования пропускной способности сети или среднее время реакции на запрос. Подробное исследование отдельных участков сети. Содержание этого этапа конкретизируется по мере того, как проводится анализ.
Обычно процесс анализа протоколов занимает относительно немного времени - 1-2 рабочих дня.
COMNETPredictor
С 1 мая 1997 на рынке появилось новое средство компании CACIProducts - COMNETPredictor. COMNETPredictor предназначен для тех случаев, когда необходимо оценить последствия изменений в сети, но без детального ее моделирования.
COMNETPredictor работает следующим образом. Из системы управления или мониторинга сети загружаются данные о работе существующего варианта сети и делается предположение об изменении параметров сети: числа пользователей или приложений, пропускной способности каналов, алгоритмов маршрутизации, производитльности узлов и т.п. Затем COMNETPredictor производит оценку последствий предлагаемых изменений и выдает результаты в виде графиков и диаграмм, на которых отображаются задержки, коэффициенты использования и предполагаемые узкие места сети.
Благодаря оргининальной технологии Flow Decomposition анализ даже крупных глобальных сетей выполняется за несколько минут.
COMNETPredictor дополняет систему COMNETIII, которая может использоваться затем для более тщательного анализа наиболее важных вариантов сети.
COMNET Predictor работаетвсреде Windows 95, Windows NT и Unix.
Диагностика коллизий
Средняя интенсивность коллизий в нормально работающей сети должна быть меньше 5%. Большие всплески (более 20%) могут быть индикатором кабельных проблем.
Если интенсивность коллизий больше 10%, то уже нужно проводить исследование сети.
Рекомендуется следующий порядок исследования:
Если это возможно, разделите сеть на функционально независимые части и исследуйте каждую часть с помощью анализатора протоколов. С помощью генератора трафика создайте фоновый трафик небольшой интенсивности (100 кадров в секунду) и наблюдайте за результатами измерений. Плавно увеличивайте среднню интенсивность трафика и одновременно замеряйте уровень ошибок и коллизий.
Решение проблем, связанных с коллизиями является достаточно сложной задачей, так как результаты наблюдений зависят от точки подключения сетевого анализатора (с точностью до нескольких меторов). Поэтому необходимо делать много измерений в различных точках.
В сети Ethernet на основе коаксиального кабеля в качестве причин коллизий могут выступать:
Слишком большая длина сегментов (свыше 185 метров для тонкого коаксиала и свыше 500 метров для толстого); Слишком много подключений к сегменту (свыше 30 для тонкого коаксиала); Слишком много заглушек - необходимо проверить, чтобы сегмент завершался заглушкой в 50 Ом только в одном месте (многопортовые повторители для коаксиального кабеля обычно имеют внутренние заглушки, поэтому установка внешней заглушки является для них лишней); Неправильное заземление - каждый коаксиальный сегмент должен быть заземлен в одной и только в одной точке.
Причинами коллизий в сети Ethernet на витой паре могут быть:
Слишком большая длина сегментов (свыше 100 метров); Нарушение правила 4-х хабов; Неправильное соединение контактов пар кабеля; Некорректно работающие порты концентратора или сетевые адаптеры; Плохие соединения в кроссовых секциях.
Динамическое обнаружение конфигурации сети
В системе Optivity реализована запатентованная технология динамического обнаружения конфигурации сети, называемая Autotopology. Эта технология хорошо интегрируется с представлением сети платформой OpenView, в результате чего администратор может пользоваться серией вложенных представлений сети с возрастающей степенью детализации.
Сетевые менеджеры могут путешествовать по представлениям сети в целях сбора и сохранения таких данных, как диагностика на MAC-уровне, коэффициенты использования сегментов и портов, данные об ошибках и другие. Любые изменения конфигурации сети автоматически отражаются в представлениях сети, снабжая администратора точной информацией.
Плоское представление сети (flatnetworkview) показывает соединение между собой сегментов Ethernet или колец TokenRing, осуществленное с помощью мостов, коммутаторов или маршрутизаторов. Сегментное представление (segmentview) отображает физические соединения между концентраторами в сегментах Ethernet или TokenRing, связанных мостами или коммутаторами.
Дополнительные функции анализа стека TCP/IP
Fluke значительно улучшил поддержку сетей ТСР/IР. Протокол TCP/IP быстро стал наиболее важным сетевым протоколом для многих корпоративных и глобальных сетей. В прошлом сети с подобным протоколом поддерживались лишь небольшой группой экспертов. Сегодня многие организации создают специальные подразделения для поддержки и управления быстро расширяющимися сетями TCP/IP. EnterpriseLANMeter обладает встроенными функциями, позволяющими получить ключевую информацию о конфигурации, необходимой для диагностики и устранения неисправностей в IP сетях. Используя протокол SNMP, EnterpriseLANMeter может получать информацию от интеллектуальных устройств в локальных и удаленных сегментах сети, а также анализировать рабочие характеристики звеньев корпоративных сетей.
Автоматическая конфигурация IP (IPAutoConfiguration)
Функция позволяет автоматизировать IP конфигурирование EnterpriseLANMeter. Она осуществляет поиск IP-адреса, назначенного LANMeter, правильной сетевой маски (subnetmask), IP-адреса маршрутизатора по умолчанию и IP-адреса любого доступного DNS сервера. Функция может использоваться в режиме Assisted, а также использовать серверы протокола динамического конфигурирования DHCP или протокола загрузкиВООТР.
Исследование сегментов (SegmentDiscovery)
Прибор анализирует наиболее важные параметры IP-сети, к которой он подключен. Автоматически определяется наличие таких проблем, как некорректная сетевая маска, дублирование IP-адресов или отсутствие в сети заявленных серверов. Функция SegmentDiscovery осуществляет также поиск в сети IP-маршрутизаторов, DHCP- и ВООТР-серверов, DNS-серверов, агентов SNMP (SNMPagents) и хостов.
Сканирование хостов (ScanHost)
Функция позволяет проверять конфигурацию компьютеров сети, сообщая МАС-адрес и сетевую маску компьютера, а также IР-адрес используемого по умолчанию маршрутизатора. Если сервер DNS сконфигурирован, то сообщается также имя хоста.
Комплект средств проверки InternetToolkit
Этот комплект использует протокол SNMP для получения информации о состоянии узлов сети и позволяет:
Собирать информацию по интеллектуальным устройствам благодаря функции опроса переменных системной группы MIB - SystemGroupQuery; Проверять таблицы маршрутов, используя функцию запроса таблиц - Route ТableQuery; Проверять состояние интерфейса с помощью опроса переменных группы InterfaceStatistics; Выявлять проблемы, используя информацию об ошибках интерфейса - InterfaceError; Проверять данные с DNS-сервера, запрашивая у него IP-адрес или имя; Проверять возможность доступа к хосту с помощью функции PingTests и получать информацию по удаленным сегментам сети благодаря функции RMONStatisticsStudies.
Дополнительные продукты
Компания NetworkGeneral предлагает еще несколько продуктов, позволяющих решить те или иные задачи анализа сетей более эффективно.
Мощное средство, предназначенное для анализа систем с использованием баз данных типа клиент/сервер - SnifferNetworkAnalyzerDatabase МоdulеT (for Огасlе7T). Добавление этого продукта к стандартному интерпретатору протоколов позволяет анализировать пакеты протоколов SQL*Netv.2, выполняющих функции обмена между сервером баз данных Oracle7 и клиентом. Возможности продукта по глубине анализа аналогичны возможностям ProtocolInterpreter. Как видно из названия, данный продукт предназначен для работы в системах на базе Oracle7, причем пока поддерживается лишь нижний уровень SQL*Net - TransportNetworkSubstrate (TNS). Однако, даже существующая в настоящий момент версия позволяет измерять времена ответов на запросы, производить декодировку сетевых протоколов совместно с протоколом TNS, отображать файлы конфигурации Oracle7 и производить трассирование пакетов. Все эти возможности резко снижают времена локализации ошибок и узких мест в системах клиент-сервер. В ближайшее время ожидается выход версий для Sybase, MicrosoftSQLServer, InformixOnLine и IBMDB2, а также введение в систему экспертных возможностей в стиле ExpertAnaLyzer.
Администратору крупной сети также может быть полезен NGCSnifferReporter - специализированное средство составления отчетов на основе данных, собранных другими приложениями анализа данных. Данные, собранные в различных точках сети различными системами анализа (ESA, NSA, DSS, FoundationManager), с помощью SnifferReporter могут быть подвергнуты одновременному анализу, что позволяет выявить дополнительные закономерности функционирования сети. NGCSnifferReporter представляет собой программное обеспечение, функционирующее под MSWindows 3.1 или старше.
Дополнительные управляющие средства и утилиты
FindNodes - эта утилита помогает быстро найти пользователей сети по неполным данным, например, по его MAC-адресу или по псевдониму. FindNodes немедленно предоставляет информацию о том, к какому концентратору, слоту и порту подключен данный пользователь. AgentManager - автоматизирует процесс распространения и загрузки новых и обновленных версий программных агентов по корпоративной сети. Это приложение также проводит автоматическую инвентаризацию агентов, встроенных в концентраторы, снабжая администратора полным списком типов модулей управления, версий агентов и версий микропрограмм. AllowedNodes - обеспечивает средства защиты сети от несанкционированного доступа. Если станция с несанкционированным адресом пытается войти в сеть, то систему можно запрограммировать таким образом, что она пошлет сообщение на консоль администратора или же автоматически отключит порт.
Foundation Agent, Foundation Probe, Foundation Manager
Это семейство представляет собой законченную систему сетевого мониторинга на базе RMON и включает в себя два типа агентов-мониторов FoundationAgent, FoundationProbe и консоль оператора FoundationManager. Агент FoundationAgent представляет собой программный продукт, устанавливаемый на стандартный IBM-совместимый компьютер, и способный собирать информацию в сегментах Ethernet или TokenRing.
FoundationAgent поддерживает все возможности стандартного SNMP-агента, все 9 (или 10 для TokenRing) групп RMON, развитую систему сбора и фильтрации данных. Относительно недавно появился новый представитель этого класса агентов - FoundationAgentMulti-Port, позволяющий с помощью одного компьютера собирать информацию с четырех сегментов Ethernet либо трех сегментов TokenRing (правда, для этого необходим базовый компьютер класса Pentium, а не 486SX, как для однопортовой системы).
FoundationProbe - сертифицированный компьютер с сертифицированной сетевой платой и предустановленным программным обеспечением FoundationAgent соответствующего типа.
FoundationAgent и FoundationProbe обычно функционируют в безмониторном и безклавиатурном режиме, поскольку управляются программным обеспечением FoundationManager. В принципе, не исключена возможность выполнения на агентах RMON еще какой-либо деятельности, кроме анализа сегментов, однако делать это настоятельно не рекомендуется из-за необходимого агенту запаса вычислительной мощности.
Программное обеспечение консоли FoundationManager поставляется в двух вариантах - для Windows и для Unix. FoundationMangerforWindows может функционировать как отдельное приложение МSWindows 3.1 или старше, или же быть интегрированным в систему администрирования НР OpenViewforWindows, тогда как FoundationManagerforUnix обязательно интегрируется с одной из систем управления сетями - НР OpenViewforHP-UX, IBMNetViewforAIX или SunNetManagerforSunOS или Solaris. Кроме того, FoundationManager выполняет все функции FoundationAgent для того сегмента сети, в котором он установлен.
Консоль FoundationManager позволяет отображать в графическом виде статистику по всем контролируемым сегментам сети, автоматически определять усредненные параметры сети и реагировать на превышение допустимых пределов параметров (например, запускать программу-обработчик, инициировать SNMP-trap и SNA-alarm), строить по собранным данным RMON графическую динамическую карту трафика между станциями.
Средства анализа трендов и автоматической генерации отчетов позволяют значительно облегчить анализ тенденций роста сети за длительное время. Предоставляются и некоторые уникальные возможности, например, анализа использования сети различными протоколами и накопление статистики в агенте в течении месяца, позволяющее значительно повысить автономность агента. Прозрачная интеграция с другим программным обеспечением от NetworkGeneral позволяет передавать захваченные пакеты данных для более глубокого анализа подсистеме ExpertAnalysis или использовать развитые средства анализа протоколов подсистемы ProtocolInterpreter.
FoundationManager способен работать совместно с любым из RMON-агентов, однако при этом будут использованы только стандартные возможности агента. Некоторые из перечисленных выше возможностей являются специфическими и реализуются только при работе совместно с агентами от NetworkGeneral.
Функции проверки аппаратуры и кабелей
LANMeter сочетает наиболее часто используемые на практике функции анализаторов сетевых протоколов и кабельных сканеров с рядом совершенно новых возможностей тестирования:
Комплексная автоматическая проверка (Expert-TAutotest)
Этот комплексный тест позволяет последовательно подключить LANMeter между конечным узлом сети и концентратором. Этот тест позволяет автоматически определить местонахождение источника неисправности - кабель, концентратор, сетевой адаптер или программное обеспечение станции.
Автоматическая проверка сетевых интерфейсных плат (NICAutotest)
Проверяет правильность функционирования вновь установленных или "подозрительных" сетевых интерфейсных карт. Для сетей Ethernet по итогам проверки сообщаются: МАС-адрес, уровень напряжения сигналов (а также присутствие и полярность тестовых импульсов на 10BASE-T). Если сигнал не обнаружен на интерфейсной карте, то тест автоматически сканирует соединительный разъем и кабель для их диагностики.
Сканирование кабеля
Функция позволяет измерять длину кабеля, расстояние до самого серьезного дефекта и распределение импеданса по длине кабеля. При проверке неэкранированной витой пары могут быть выявлены следующие ошибки: расщепленная пара, обрывы, короткое замыкание и другие виды нарушения соединения.
Для сетей Ethernet на коаксиальном кабеле эти проверки могут быть осуществлены на работающей сети.
Функция определения распределения кабельных жил - Wire Мaр
Осуществляет проверку правильности подсоединения жил, наличие промежуточных разрывов и перемычек на витых парах. На дисплей выводится перечень связанных между собой контактных групп.
Функция определения типа кабеля
Используется для составления карты основных кабелей и кабелей, ответвляющихся от центрального помещения.
Автоматическая проверка кабеля - CableAutotest
В зависимости от конфигурации возможно определить длину, импеданс, схему подключения жил, затухание и параметр NEXT на частоте до 100 МГц. Различные индивидуальные тесты кабелей выполняются в зависимости от конфигурации сети.
Автоматическая проверка выполняется для:
коаксиальных кaбелей; экранированной витой пары с импедансом 150 Ом; неэкранированной витой пары с сопротивлением 100 Ом.
Целостность цепи при проверке постоянным током (DCContinuity)
Эта функция используется при проверке коаксиальных кабелей для верификации правильности используемых терминаторов и их установки.
Определение номинальной скорости распространения NVP (NominalVelocityofPropagation)
Функция вычисляет номинальную скорость распространения по кабелю известной длины и дополнительно сохраняет полученные результаты в файл для определяемом пользователем типа кабеля (UserDefinedcabletype) или стандартного кабеля.
Функциональные возможности
Как большинство наиболее дорогостоящих анализаторов сетевых протоколов, EnterpriseLANMeter позволяет провести анализ в режиме реального времени функционирования сети, выполняя специализированные тесты. Одновременно выполняется тестирование по двум группам испытаний: сбор статистики о трафике в сети в целом, сбор статистики о трафике отдельных узлов. В первую группу входят функции NetworkStatistics, ErrorStatistics и CollisionAnalysis (измеряющие, соответственно, общий трафик, трафик ошибочных кадров и интенсивность коллизий в сети), а во вторую группу - функции определения узлов, отправляющих наибольшее количество кадров (Тор Senders), получающих наибольшее количество кадров (TopReceivers) и генерирующих наибольшее количество широковещательных кадров (Тор Broadcasters).
Рассмотрим функциональные возможности EnterpriseLANMeter на примере анализа сетей Ethernet.
NetworkStatistics
Эта функция позволяет наблюдать общее состояние сети с помощью статистической обработки и представления результатов по основным показателям работоспособности сети. К ним относятся степень использования (Utilization), уровень коллизий (Collisions), уровень ошибок и широковещательного трафика. EnterpriseLANMeter представляет результаты измерений в числовой и графической форме.
ErrorStatistics
Эта функция позволяет отслеживать все типы и причины ошибок. Результаты представляются в числовой форме и в виде круговой диаграммы, показывающей относительное распределение типов отказов по общему их количеству. Типы отказов, которым предшествует маркер *, можно выделить подсветкой на дисплее, а затем клавишей с функцией "Zoomin" (увеличение) можно вызвать на дисплей список станций, являющихся источником этих сбоев.
Collisionanalysis
Обеспечивает информацию о количестве и видах коллизий, отмеченных на сегменте сети, позволяет определить наличие и местонахождение проблемы. В режиме анализа коллизий на дисплей выводятся все зарегистрированные коллизии, включая коллизии заголовков и энергетические "призраки" (energyghosts) - наводки в кабеле, которые занимают часть полосы пропускания, мешая узлам сети станциям передавать информацию.
Большинство анализаторов сетевых протоколов не обладают возможностью регистрировать кадры-призраки.
Распределение используемых сетевых протоколов (Protocol Мix)
На дисплее отображается список основных протоколов в убывающем порядке относительно процентного соотношения кадров, содержащих пакеты данного протокола к общему числу кадров в сети. Подсветив интересующий протокол и нажав клавишу "ZoomIn", можно получить перечень основных станций в убывающем порядке, использующих этот протокол. Перечень всех протоколов и использующих их станций можно распечатать или вызвать на экран.
Основные отправители (Тор Senders)
Функция позволяет отслеживать наиболее активные передающие узлы локальной сети. LANMeter можно настроить на фильтрацию по единственному адресу и выявить список основных отправителей кадров для данной станции. Данные отражаются на дисплее в виде круговой диаграммы вместе с перечнем основных отправителей кадров. Возможен вывод на печать или дисплей перечня всех вещавших в течение периода испытаний станций.
Основные получатели (Тор Receivers)
Функция позволяет следить за наиболее активными узлами-получателями сети. Информация отображается в виде, аналогичном приведенному выше.
Основные генераторы широковещательного трафика (TopBroadcasters)
Функция может использоваться для идентификации неправильно сконфигурированных станций. LANMeter анализирует и выявляет различия между широковещательными, групповыми (multi-cast) и уникальными (non-broadcast) адресами кадров в сети Ethernet.
Список всех станций, передающих широковещательные кадры, может быть распечатан или выведен на дисплей.
Генерирование трафика (TrafficGeneration)
LANMeter создает трафик для проверки компонентов сети при работе с повышенной нагрузкой. Дополнительный трафик выявляет проблемы, связанные со средой и другими проблемами на физическом уровне. Трафик может генерироваться в сетях Ethernet параллельно с активизированными функциями NetworkStatistics, ErrorStatistics и CollusionAnalysis.
Пользователь может задать параметры генерируемого трафика, такие как интенсивность и размер кадров. Для тестирования мостов и маршрутизаторов LANMeter автоматически создает заголовки пакетов IP и IPX: все что требуется от оператора - это внести адрес источника и получателя.
В ходе испытаний пользователь может увеличить на ходу размер и частоту следования кадров с помощью клавиш управления курсором. Это особенно ценно при поиске источника проблем производительности сети и условий возникновения отказов.
LANMeter обеспечивает анализ протоколов:
ТСР/IР, Novell NetWare, NetBIOS сетях: WindowsNT Windows95, Windows for Workgroups, IBM LAN Server иОS/2, ВаnуаnVINES.
Характеристика PerformanceMonitor
PerformanceMonitor - это утилита, разработанная для фиксации активности компьютера в реальном масштабе времени. С помощью этой утилиты можно определить большую часть узких мест, ухудшающих производительность. Эта утилита также включена в WindowsNTWorkstation.
PerformanceMonitor основан на ряде счетчиков, которые фиксируют такие характеристики, как число процессов, ожидающих завершения операции с диском, число сетевых пакетов, передаваемых в единицу времени, процент использования процессора и другие.
PerformanceMonitor генерирует полезную информацию за счет:
Наблюдения за производительностью в реальном времени и в исторической перспективе; Определения тенденций во времени; Определения узких мест; Отслеживания последствий изменения конфигурации системы; Наблюдения за локальным или удаленными компьютерами; Предупреждения администратора о событиях, заключающихся в превышении некоторыми характеристиками заданных порогов.
PerformanceMonitor работает с такими понятиями, как объекты (objects), счетчики (counters) и экземпляры (instances). Объекты описываются различными характеристиками, значения которых подсчитываются соответствующими счетчиками. Объект каждого типа может быть представлен в системе несколькими экземплярами. Например, процессор - это объект, процент процессорного времени - это счетчик, а процессор 0 - это экземпляр объекта процессор.
Счетчики генерируют числа, и на основании этих чисел PerformanceMonitor определяет статистику. Собираемая в течение определенного времени статистика счетчиков отражает тенденции производительности. Это может помочь администратору понять проблему и оптимизировать сеть. Кроме того, такие данные помогают правильно расширять сеть.
Счетчики обычно включают ссылку на объект, к которому они относятся, в форме ОБЪЕКТ:СЧЕТЧИК. Например, PROCESSOR:%PROCESSORTIME - это счетчик, учитывающий процент использования для данного процессора.
С каждым объектом связан набор счетчиков, которые генерируют данные о различных аспектах производительности объекта.
В таблице 2. 1 собраны наиболее влияющие на производительность счетчики.
Таблица 2.1
| Тип объекта | Счетчик | Возможные действия |
| Processor (процессор) | %ProcessorTime (время занятости процессора) | Если значение этого счетчика постоянно велико, а значения счетчика диска и сетевого адаптера невысоки, то нужно проверить процессор |
| PhysicalDisk (физический диск) | %DiskTime (время занятости диска) | Если значение этого счетчика постоянно велико, и значение счетчика DiskQueueLength (длина очереди к диску) больше 2, то нужно проверить диск |
| Memory (память) | Pages/sec (скорость обмена страниц) | Если этот счетчик постоянно больше 5, то нужно проверить память |
| Server (сервер) | BytesTotal/sec (скорость обмена с памятью) | Если сумма значений счетчиков BytesTotal/sec для всех серверов сети примерно равна максимальной пропускной способности сети, то сеть нужно сегментировать |
Данные, собранные PerformanceMonitor, можно экспортировать в другие программные продукты, такие как электронные таблицы и базы данных для дальнейшего анализа.
Интегрированное управление маршрутизаторами
Система Optivity включает интегрированное приложение RouterMan для контроля и управления маршрутизаторами BayNetworks, Cisco и другими, поддерживающими базу управляющей информации MIB-II. Данное приложение обладает простым графическим интерфейсом с цветным кодированием, что упрощает операции по стандартам SNMP и MIB. Автоматически отображаются все протоколы и интерфейсы, поддерживаемые маршрутизатором, в том числе IP, IPX, DECnetIV, XNS, AppleTalk, BanyanVINES, Ethernet, TokenRing, FDDI и WAN-протоколы на последовательных линиях.
Администратор может установить условия предупреждений и тревог для раннего оповещения о возникающих или потенциальных проблемах.
С помощью RouterMan можно конфигурировать маршрутизаторы BayNetworks и Cisco, а также отслеживать изменения конфигурации, сравнивать различные версии конфигурационных файлов и производить реконфигурацию по протоколу SNMP.
Использование моделирования для оптимизации производительности сети
Анализаторы протоколов незаменимы для исследования реальных сетей, но они не позволяют получать количественные оценки характеристик для еще не существующих сетей, находящихся в стадии проектирования. В этих случаях проектировщики могут использовать средства моделирования, с помощью которых разрабатываются модели, воссоздающие информационные процессы, протекающие в сетях.
Использование RAID-массивов для повышения производительности
Главными характеристиками дискового накопителя являются его емкость, быстродействие и надежность. Требуемая емкость диска (или дисков) определяется задачами пользователей сети и требованиями к развитию системы.
Показателями быстродействия диска являются две характеристики - среднее время доступа к диску, зависящее от времени перемещения головок между дорожками диска, и скорость передачи данных между диском и контроллером диска. Кроме того, для оценки производительности дисков, используемых для хранения баз данных, удобной характеристикой является скорость транзакций, обычно измеряемая в количестве вводов/выводов в секунду. Предлагаемые на рынке диски имеют в основном два типа интерфейса между диском и контроллером диска: IDE и SCSI (с его разновидностями - SCSI-2 и FastSCSI-2). Требуемую скорость передачи данных обеспечивает интерфейс SCSI, к тому же он позволяет подключить к одному контроллеру до 7 дисков, что не может интерфейс IDE. Поэтому для файл-серверов в сетях с количеством пользователей больше 10 желательно использовать диски с интерфейсом SCSI. Желательно, чтобы контроллер диска имел большую кэш-память, в этом случае обмен с дисками значительно ускоряется.
Для обеспечения надежного хранения данных на дисках в файл-серверах широко используются дисковые массивы - так называемые RAID-массивы (RedundantArrayofInexpensiveDisks - избыточные массивы недорогих дисков). Для компьютера дисковый массив представляется одним диском. Существуют различные схемы организации внешней памяти на основе набора дисков - RAID-уровни. Одни из них повышают только надежность, другие - только скорость доступа к данным, а некоторые - сочетают в себе оба эти достоинства. При этом, немаловажным обстоятельством является степень избыточности оборудования, требуемая для реализации того или иного уровня RAID, которая влияет на экономичность выбранного решения.
УровеньRAID-0 повышает скорость доступа к данным за счет их расщепления. Общий для дискового массива контроллер передает данные параллельно на все диски, при этом первый байт данных записывается на первый диск, второй - на второй и т.
д. Время доступа при выполнении одной операции ввода-вывода сокращается за счет одновременности операций записи/чтения по всем дискам массива. В параллельном дисковом массиве должен использоваться специальный контроллер, обеспечивающий синхронизацию дисководов. Понятно, что надежность этой схемы по сравнению с одиночным диском в общем случае не только не повышается, а становится ниже, действительно вероятность отказа возрастает, из-за увеличения числа дисков. Зато уровень RAID не создает избыточности данных в дисковом массиве.
УровеньRAID-1 реализует зеркальную запись на диски. Второй (или резервный) диск дублирует каждый основной диск. Если основной диск выходит из строя, зеркальный продолжает сохранять данные. Этот способ характеризуется высокой надежностью, сопровождаемой, однако, высокой избыточностью. Очевидно, что скорость доступа к данным не повышается.
Уровень RAID-2 используется в больших компьютерах и представляет собой способ побитного расслоения, который позволяет увеличить скорость доступа к данным за счет расспараллеливания запроса.
В реализацииRAID-3 используется массив из N дисков, запись на N-1 из них производится параллельно с побайтным (или блочным) расщеплением, как в методе RAID-0. N-ый диск используется для записи контрольной информации о четности. Диск четности является резервным. Если какой-либо диск выходит из строя, то данные остальных дисков плюс данные о четности резервного диска позволяют восстановить утраченную информацию. Уровень RAID-3 повышает как надежность, так и скорость обмена информацией, однако обладает избыточностью, хотя и меньшей, чем уровень RAID-1.
Уровень RAID-4 также использует один резервный диск для записи контрольной информации о четности, но расщепление происходит на уровне более крупных единиц данных - на уровне секторов. За счет этого может происходить независимый обмен с каждым диском. Скорость передачи данных не выше, чем у отдельного диска, однако, поскольку диски работают независимо, данные могут считываться одновременно со всех дисков.
Это делает возможным одновременное выполнение нескольких операций ввода-вывода. Основным недостатком уровня RAID-4 является низкая скорость записи. Информация о четности должна корректироваться каждый раз, когда выполняется операция записи. Старые данные и старая информация о четности сначала должны быть считаны, а затем объединены с новыми данными, чтобы получить новую информацию о четности. Затем она должна быть записана на диск четности. Причиной значительного уменьшения скорости в методе RAID-4 является то, что после чтения старых данных и старой информации о четности каждый диск должен повернуться на один полный оборот до того, как новые данные и информация о четности могут быть записаны. Кроме того, при параллельном выполнении нескольких операций ввода-вывода могут возникать очереди при обращении к диску с контрольной информацией.
В уровнеRAID-5 используется метод, аналогичный RAID-4, но данные о контроле четности распределяются по дискам массива. Каждая команда записи инициирует ту же последовательность считывание-модификация-запись в нескольких дисках, как и в методе RAID-4. Поскольку информация о четности может быть считана и записана на несколько дисков одновременно, вероятность возникновения очередей к дискам уменьшается, а, следовательно, скорость записи по сравнению с уровнем RAID-4 увеличивается. Однако она все еще гораздо ниже скорости отдельного диска, метода RAID-1 или RAID-3.
Существуют и другие способы использования RAID-массивов. Иногда могут встречаться комбинации разных схем, например, уровень RAID-10 представляет собой расслоение (RAID-0) в сочетании с зеркальным отображением (RAID-1). Наиболее часто в дисковых подсистемах файловых серверов используются уровни RAID-1, RAID-3 и RAID-5.
Кабельные сканеры
Данные приборы позволяют определить длину кабеля, NEXT, затухание, импеданс, схему разводки, уровень электрических шумов и провести оценку полученных результатов. Цена на эти приборы варьируется от $1'000 до $3'000. Существует достаточно много устройств данного класса, например, сканерыкомпаний MicrotestInc., FlukeCorp., DatacomTechnologiesInc., ScopeCommunicationInc. В отличие от сетевых анализаторов сканеры могут быть использованы не только специально обученным техническим персоналом, но даже администраторами-новичками.
Для определения местоположения неисправности кабельной системы (обрыва, короткого замыкания, неправильно установленного разъема и т.д.) используется метод "кабельного радара", или TimeDomainReflectometry (TDR). Суть этого метода состоит в том, что сканер излучает в кабель короткий электрический импульс и измеряет время задержки до прихода отраженного сигнала. По полярности отраженного импульса определяется характер повреждения кабеля (короткое замыкание или обрыв). В правильно установленном и подключенном кабеле отраженный импульс совсем отсутствует.
Точность измерения расстояния зависит от того, насколько точно известна скорость распространения электромагнитных волн в кабеле. В различных кабелях она будет разной. Скорость распространения электромагнитных волн в кабеле (NVP - nominalvelocityofpropagation) обычно задается в процентах к скорости света в вакууме. Современные сканеры содержат в себе электронную таблицу данных о NVP для всех основных типов кабелей и позволяют пользователю устанавливать эти параметры самостоятельно после предварительной калибровки.
Наиболее известными производителями компактных (их размеры обычно не превышают размеры видеокассеты стандарта VHS) кабельных сканеров являются компании MicrotestInc., WaveTekCorp., ScopeCommunicationInc.
Кабельные сканеры компании Microtest
Семейство моделей PentaScanner компании Microtest предназначено для проведения сертификации кабельных систем.
Модель кабельного сканера PentaScannerCableAdmin обеспечивает сертификацию кабельных систем категории 5 уровней точности I. Этот сканер предназначен для поиска неисправностей кабельной системы администраторами ЛВС и представляет собой сравнительно дешевый и простой в использовании прибор, позволяющий быстро определить неисправность кабельной системы.
Кабельный сканер PentaScanner+ предназначен, главным образом, для специалистов компаний сетевых интеграторов или сотрудников отделов автоматизаций предприятий, которым необходимо устанавливать и сертифицировать кабельные системы категории 5. Стандарт TSB-67 требует измерения NEXT с обоих концов линии. Используя PentaScanner+ совместно с двунаправленным инжектором - 2-WayInjector+, измерения NEXT можно производить с обоих концов линии одновременно. При использовании Penta-Scanner+ совместно со стандартным инжектором - SuperInjector+, необходимо менять местами PentaScanner+ и SuperInjector+ для проведения полной сертификации линии.
PentaScanner+ проводит все необходимые тесты для сертификации кабельных сетей, включая определение NEXT, затухания, отношения сигнал-шум, импеданса, емкости и активного сопротивления.
PentaScanner+ содержит несколько частотных генераторов и узкополосных приемников, графический дисплей на жидких кристаллах и флэш-память для записи результатов тестирования и новых версий программного обеспечения. В качестве элемента питания PentaScanner использует аккумуляторные батареи, работающие без подзарядки до 10 часов. Прибор содержит разъемы для прямого присоединения к кабелю без использования дополнительных адаптеров.
Для измерения перекрестных наводок между витыми парами (NEXT) источник сигналов - SuperInjector+, прибор поставляемый в комплекте с PentaScanner+ - подсоединяется к передающей паре и начинает передавать в нее сигналы различной частоты. Приемник сигналов подключается к приемной паре и измеряет сигнал, наведенный в ней, сравнивая его со стандартными величинами.
Преимуществом узкополосного приемника в PentaScanner+ является измерение "чистого" NEXT с отфильтровыванием всех наводок и электрического шума. Для измерения затухания PentaScanner+ использует SuperInjector+ в качестве удаленного источника сигналов, генерирующего серию сигналов различной частоты. PentaScanner+ в этот момент измеряет амплитуду этих сигналов на другом конце кабеля.
Последняя модель сканеров семейства PentaScanner - PentaScanner 350 - является сканером нового поколения, предназначенного для тестирования кабельных систем категории 5 на частоте до 350 Мгц. PentaScanner 350 представляет собой наиболее прецизионный на сегодняшний день кабельный сканер, полностью соответствующий Уровню точности II стандарта TSB-67. В памяти сканера PentaScanner 350 могут сохраняться результаты до 500 различных тестов.
Описаные выше устройства предназначены для тестирования кабельных систем на основе медного кабеля. Для диагностики волоконно-оптических кабелей компания Microtest предлагает комплект FiberSolutionKit, который состоит из двух приборов: измерителя оптической мощности FiberEye и калиброванного светового источника FiberLight.
Эти приборы позволяют тестировать сети стандартов Ethernet, TokenRing и FiberDistributedDataInterface (FDDI).
FiberEye измеряет мощность светового пучка, входящего или выходящего из волоконно-оптической линии. Точное измерение оптической мощности и потери оптического сигнала необходимы при инсталляции, техническом обслуживании и поиске неисправностей в волоконно-оптических сетях. С помощью FiberEye можно также проверить правильность работы различных волоконно-оптических компонентов, таких, как волоконно-оптические концентраторы, повторители и сетевые адаптеры. Данные о потере сигнала помогают определить дефектные участки кабеля, неисправные разъемы и коннекторы.
FiberLight - калиброванный световой источник, может быть использован вместе с FiberEye для обеспечения эффективности диагностики волоконно-оптической сети. FiberLight состоит из двух источников световых импульсов, каждый из которых имеет свой внешний разъем для подключения к кабелю.Один источник используется для сетей Ethernet и TokenRing, a другой для сетей FDDI.
Как интерпретировать результаты тестирования мостов, коммутаторов и маршрутизаторов
Часто в периодических изданиях, посвященных сетевой тематике, приводятся результаты тестирования производительности коммуникационного оборудования - мостов, коммутаторов и маршрутизаторов, выполненными в специальных тестовых лабораториях.
Результаты тестирования могут выглядеть, например, следующим образом:
| Модель коммутатора | Производительность в кадрах/сек на один порт |
| 3Com Linkswitch 1000 | 3700 |
| 3Com LANplex 6012 | 4050 |
| Madge LANswitch | 4400 |
| DECswitch 900EF +GIGAswitch | 4400 |
| Cisco Catalyst 5000 | 4900 |
| Cisco Catalyst 2800 | 4500 |
| Bay Networks LattisSwitch 28115 | 3950 |
Тестированиепроводилосьлабораториейжурнала Data Communication International совместнослабораторией European Network Labs.
Для того, чтобы правильно интерпретировать результаты тестирования и принять обоснованное решение о том, какой из коммутаторов можно применить в вашей конкретной сети, нужно прежде всего выяснить, при каких условиях эти результаты были получены и насколько эти условия соответствуют тем, которые могут встретиться в вашей сети.
В приведенном примере два тестируемых коммутатора соединялись друг с другом высокоскоростными портами так, как это показано на рисунке 2.15.
Нагрузка на сеть создавалась двумя генераторами трафика SmartbitsAdvancedSMB100, которые посылали трафик на 20 портов Ethernet каждого из двух тестируемых образцов коммутатора. Трафик, посылаемый на каждый входной порт, направлялся через этот порт остальным 39 портам коммутаторов с равной степенью вероятности, так что каждый порт был загружен на 100%, то есть должен был передавать 14880 кадров в секунду. Использовались кадры минимального размера по 64 байта каждый.
Генераторы трафика подсчитывали количество кадров, которые дошли до порта назначения, и на основании этих данных подсчитывались количественные оценки качества передачи трафика коммутаторами.

Рис. 2.15. Схема тестирования коммутаторов
Очевидно, что на основании этих результатов можно выбирать коммутаторы для тех реальных сетей, в которых распределение нагрузки между портами коммутатора близко к равномерному. Такие случаи нередки для одноранговых сетей или же для сетей, где коммутаторы работают на верхних уровнях иерархии, объединяя трафики крупных сегментов. Однако, если коммутатор используется в сети с выделенным сервером, где наблюдается явный перекос трафика в сторону порта, к которому подключен сервер, то необходимо искать результаты тестирования в соответствующих условиях, с несимметричным распределением трафика.
Каналы связи и глобальные сети
Каналы связи моделируются путем задания их типа, а также двух параметров - попускной способности и вносимой задержки распространения. Единицей передаваемых по каналу данных является кадр. Пакеты при передаче по каналам сегментируются на кадры. Каждый канал характеризуется: минимальным и максимальным размером кадра, накладными расходами на кадр и интенсивностью ошибок в кадрах.
В системе COMNETIII можно моделировать все распространенные методы доступа к передающей среде, в том числе ALOHA. CSMA/CD, TokenRing, FDDI и т.п. Каналы "точка-точка" могут также использоваться для моделирования каналов ISDN и SONET/SDH.
COMNETIII включает средства для моделирования глобальных сетей на самом верхнем уровне абстракции. Такое представление глобальных сетей целесообразно, когда задание точных сведений о топологии физических связей и о полном трафике глобальной сети невозмодно или нецелесообразно. Например, нет смысла точно моделировать работу Internet при исследовании передачи трафика между двумя локальными сетями, подключенными к Internet.
COMNETIII позволяет укрупненно моделировать сети FrameRelay, сети с коммутацией ячеек (например, АТМ), сети с коммутацией пакетов (например, Х.25).
При моделировании глобальных сетей имитируется разбиение пакетов на кадры, причем каждый тип глобального сервиса характеризуется минимальным и максимальным размерами кадра и накладными расходами на служебную информацию.
Связь с глобальной сетью имитируется с помощью канала дрступа, который имеет определенные задержку распространения и пропускную способность. Сама глобальная сеть характеризуется задержкой доставки информации от одного канала доступа до другого, вероятностью потери кадра или его принудительного удаления из сети (при нарушении соглашения о параметрах трафика типа CIR). Эти параметры зависят от степени загруженности глобальной сети, которая может быть задана как нормальная, умеренная и высокая. Имеется возможность моделировать виртуальные каналы в сети.
Классификация средств мониторинга и анализа
Все многообразие средств, применяемых для мониторинга и анализа вычислительных сетей, можно разделить на несколько крупных классов:
Системы управления сетью (NetworkManagementSystems) - централизованные программные системы, которые собирают данные о состоянии узлов и коммуникационных устройств сети, а также данные о трафике, циркулирующем в сети. Эти системы не только осуществляют мониторинг и анализ сети, но и выполняют в автоматическом или полуавтоматическом режиме действия по управлению сетью - включение и отключение портов устройств, изменение параметров мостов адресных таблиц мостов, коммутаторов и маршрутизаторов и т.п. Примерами систем управления могут служить популярные системы HPOpenView, SunNetManager, IBMNetView.
Средства управления системой (SystemManagement). Средства управления системой часто выполняют функции, аналогичные функциям систем управления, но по отношению к другим объектам. В первом случае объектом управления является программное и аппаратное обеспечение компьютеров сети, а во втором - коммуникационное оборудование. Вместе с тем, некоторые функции этих двух видов систем управления могут дублироваться, например, средства управления системой могут выполнять простейший анализ сетевого трафика.
Встроенные системы диагностики и управления (Embeddedsystems). Эти системы выполняются в виде программно-аппаратных модулей, устанавливаемых в коммуникационное оборудование, а также в виде программных модулей, встроенных в операционные системы. Они выполняют функции диагностики и управления только одним устройством, и в этом их основное отличие от централизованных систем управления. Примером средств этого класса может служить модуль управления концентратором Distrebuted 5000, реализующий функции автосегментации портов при обнаружении неисправностей, приписывания портов внутренним сегментам концентратора и некоторые другие. Как правило, встроенные модули управления "по совместительству" выполняют роль SNMP-агентов, поставляющих данные о состоянии устройства для систем управления.
Простейшим вариантом экспертной системы является контекстно-зависимая help-система. Более сложные экспертные системы представляют собой так называемые базы знаний, обладающие элементами искусственного интеллекта. Примером такой системы является экспертная система, встроенная в систему управления Spectrum компании Cabletron.
Многофункциональные устройства анализа и диагностики. В последние годы, в связи с повсеместным распространением локальных сетей возникла необходимость разработки недорогих портативных приборов, совмещающих функции нескольких устройств: анализаторов протоколов, кабельных сканеров и, даже, некоторых возможностей ПО сетевого управления. В качестве примера такого рода устройств можно привести Compas компании MicrotestInc. или 675 LANMeterкомпании FlukeCorp.
3.1.1. Системы управления
В соответствии с рекомендациями ISO можно выделить следующие функции средств управления сетью:
Управление конфигурацией сети и именованием - состоит в конфигурировании компонентов сети, включая их местоположение, сетевые адреса и идентификаторы, управление параметрами сетевых операционных систем, поддержание схемы сети: также эти функции используются для именования объектов. Обработка ошибок - это выявление, определение и устранение последствий сбоев и отказов в работе сети. Анализ производительности - помогает на основе накопленной статистической информации оценивать время ответа системы и величину трафика, а также планировать развитие сети. Управление безопасностью - включает в себя контроль доступа и сохранение целостности данных. В функции входит процедура аутентификации, проверки привилегий, поддержка ключей шифрования, управления полномочиями. К этой же группе можно отнести важные механизмы управления паролями, внешним доступом, соединения с другими сетями. Учет работы сети - включает регистрацию и управление используемыми ресурсами и устройствами. Эта функция оперирует такими понятиями как время использования и плата за ресурсы.
Из приведенного списка видно, что системы управления выполняют не только функции мониторинга и анализа работы сети, необходимые для получения исходных данных для настройки сети, но и включают функции активного воздействия на сеть - управления конфигурацией и безопасностью, которые нужны для отработки выработанного плана настройки и оптимизации сети.
Сам этап создания плана настройки сети обычно остается за пределами функций системы управления, хотя некоторые системы управления имеют в своем составе экспертные подсистемы, помогающие администратору или интегратору определить необходимые меры по настройке сети.
Средства управления сетью (NetworkManagement), не следует путать со средствами управления компьютерами и их операционными системами (SystemManagement).
Средства управления системой обычно выполняют следующие функции:
Учет используемых аппаратных и программных средств. Система автоматически собирает информацию об обследованных компьютерах и создает записи в базе данных об аппаратных и программных ресурсах. После этого администратор может быстро выяснить, чем он располагает и где это находится. Например, узнать о том, на каких компьютерах нужно обновить драйверы принтеров, какие ПК обладают достаточным количеством памяти и дискового пространства и т. п. Распределение и установка программного обеспечения. После завершения обследования администратор может создать пакеты рассылки программного обеспечения - очень эффективный способ для уменьшения стоимости такой процедуры. Система может также позволять централизованно устанавливать и администрировать приложения, которые запускаются с файловых серверов, а также дать возможность конечным пользователям запускать такие приложения с любой рабочей станции сети. Удаленный анализ производительности и возникающих проблем. Администратор может удаленно управлять мышью, клавиатурой и видеть экран любого ПК, работающего в сети под управлением той или иной сетевой операционной системы. База данных системы управления обычно хранит детальную информацию о конфигурации всех компьютеров в сети для того, чтобы можно было выполнять удаленный анализ возникающих проблем.
Примерами средств управления системой являются такие продукты, как SystemManagementServer компании Microsoft или LANDeskManager фирмы Intel, а типичными представителями средств управления сетями являются системы HPOpenView, SunNetManager и IBMNetView.
В последнее время в области систем управления наблюдаются две достаточно четко выраженные тенденции:
интеграция в одном продукте функций управления сетями и системами, распределенность системы управления, при которой в системе существует несколько консолей, собирающих информацию о состоянии устройств и систем и выдающих управляющие действия.
Создание систем управления сетями немыслимо без ориентации на определенные стандарты, так как управляющее программное обеспечение и сетевое оборудование, а, значит, и агентов для него, разрабатывают сотни компаний. Поскольку корпоративная сеть наверняка неоднородна, управляющие инструменты не могут отражать специфики одной системы или сети.
Наиболее распространенным протоколом управления сетями является протокол SNMP (SimpleNetworkManagementProtocol), его поддерживают сотни производителей. Главные достоинства протокола SNMP - простота, доступность, независимость от производителей. В значительной степени именно популярность SNMP задержала принятие CMIP, варианта управляющего протокола по версии OSI. Протокол SNMP разработан для управления маршрутизаторами в сети Internet и является частью стека TCP/IP.
SNMP - это протокол, используемый для получения от сетевых устройств информации об их статусе, производительности и характеристиках, которые хранятся в специальной базе данных сетевых устройств, называемой MIB (ManagementInformationBase). Существуют стандарты, определяющие структуру MIB, в том числе набор типов ее переменных (объектов в терминологии ISO), их имена и допустимые операции этими переменными (например, читать). В MIB, наряду с другой информацией, могут храниться сетевой и/или MAC-адреса устройств, значения счетчиков обработанных пакетов и ошибок, номера, приоритеты и информация о состоянии портов. Древовидная структура MIB содержит обязательные (стандартные) поддеревья, а также в ней могут находиться частные (private) поддеревья, позволяющие изготовителю интеллектуальных устройств реализовать какие-либо специфические функции на основе его специфических переменных.
Агент в протоколе SNMP - это обрабатывающий элемент, который обеспечивает менеджерам, размещенным на управляющих станциях сети, доступ к значениям переменных MIB, и тем самым дает им возможностьреализовывать функции по управлению и наблюдению за устройством. Типичная структура системы управления изображена на рисунке 3.1.

Рис. 3.1. Типичная структура системы управления сетью.
Основные операции по управлению вынесены в управляющую станцию. При этом устройство работает с минимальными издержками на поддержание управляющего протокола. Оно использует почти всю свою вычислительную мощность для выполнения своих основных функций маршрутизатора, моста или концентратора, а агент занимается сбором статистики и значений переменных состояния устройства и передачей их менеджеру системы управления. SNMP - это протокол типа "запрос-ответ", то есть на каждый запрос, поступивший от менеджера, агент должен передать ответ. Особенностью протокола является его чрезвычайная простота - он включает в себя всего несколько команд.
Команда Get-request используется менеджером для получения от агента значения какого-либо объекта по его имени. Команда GetNext-requestиспользуется менеджером для извлечения значения следующего объекта (без указания его имени) при последовательном просмотре таблицы объектов. С помощью команды Get-response агент SNMP передает менеджеру ответ на одну из команд Get-request или GetNext-request. Команда Set используется менеджером для установления значения какого-либо объекта либо условия, при выполнении которого агент SNMP должен послать менеджеру соответствующее сообщение. Может быть определена реакция на такие события как инициализация агента, рестарт агента, обрыв связи, восстановление связи, неверная аутентификация и потеря ближайшего маршрутизатора. Если происходит любое из этих событий, то агент инициализирует прерывание. Команда Trap используется агентом для сообщения менеджеру о возникновении особой ситуации. Версия SNMPv.2 добавляет к этому набору команду GetBulk, которая позволяет менеджеру получить несколько значений переменных за один запрос.
Критерии эффективности работы сети
Все множество наиболее часто используемых критериев эффективности работы сети может быть разделено на две группы. Одна группа характеризует производительность работы сети, вторая - надежность.
Производительность сети измеряется с помощью показателей двух типов - временных, оценивающих задержку, вносимую сетью при выполнении обмена данными, и показателей пропускной способности, отражающих количество информации, переданной сетью в единицу времени. Эти два типа показателей являются взаимно обратными, и, зная один из них, можно вычислить другой.
1.2.1. Время реакции
Обычно в качестве временной характеристики производительности сети используется такой показатель как время реакции. Термин "время реакции" может использоваться в очень широком смыле, поэтому в каждом конкретном случае необходимо уточнить, что понимается под этим термином.
В общем случае, время реакции определяется как интервал времени между возникновением запроса пользователя к каму-либо сетевому сервису и получением ответа на этот запрос (рис. 1.1). Очевидно, что смысл и значение этого показателя зависят от типа сервиса, к которому обращается пользователь, от того, какой пользователь и к какому серверу обращается, а также от текущего состояния других элементов сети - загруженности сегментов, через которые проходит запрос, загруженности сервера и т.п.

Рис. 1.1. Время реакции - интервал между запросом и ответом
Рассмотрим несколько примеров определения показателя "время реакции", иллюстрируемых рисунком 1.2.

Рис. 1.2. Показатели производительности сети
В примере 1 под временем реакции понимается время, которое проходит с момента обращения пользователя к сервису FTP для передачи файла с сервера 1 на клиентский компьютер 1 до момента завершения этой передачи. Очевидно, что это время имеет несколько составляющих. Наиболее существенный вклад вносят такие составляющие времени реакции как: время обработки запросов на передачу файла на сервере, время обработки получаемых в пакетах IP частей файла на клиентском компьютере, время передачи пакетов между сервером и клиентским компьютером по протоколу Ethernet в пределах одного коаксиального сегмента.
Можно было бы выделить еще более мелкие этапы выполнения запроса, например, время обработки запроса каждым из протоколов стека TCP/IP на сервере и клиенте.
Для конечного пользователя таким образом определенное время реакции является понятным и наиболее естественным показателем производительности сети (размер файла, который вносит некоторую неопределенность в этот показатель, можно зафиксировать, оценивая время реакции при передаче, например, одного мегабайта данных). Однако, сетевого специалиста интересует в первую очередь производительность собственно сети, поэтому для более точной ее оценки целесообразно вычленить из времени реакции составляющие, соответствующие этапам несетевой обработки данных - поиску нужной информации на диске, записи ее на диск и т.п. Полученное в результате таких сокращений время можно считать другим определением времени реакции сети на прикладном уровне.
Вариантами этого критерия могут служить времена реакции, измеренные при различных, но фиксированных состояниях сети:
A) Полностью ненагруженная сеть. Время рекции измеряется в условиях, когда к серверу 1 обращается только клиент 1, то есть на сегменте сети, объединяющем сервер 1 с клиентом 1, нет никакой другой активности - на нем присутствуют только кадры сессии FTP, производительность которой измеряется. В других сегментах сети трафик может циркулировать, главное - чтобы его кадры не попадали в сегмент, в котором проводятся измерения. Так как ненагруженный сегмент в реальной сети - явление экзотическое, то данный вариант показателя производительности имеет ограниченную применимость - его хорошие значения говорят только о том, что программное обеспечение и аппаратура данных двух узлов и сегмента обладают необходимой производительностью для работы в облегченных условиях. Для работы в реальных условиях, когда будет иметь место борьба за разделяемые ресурсы сегмента с другими узлами сети, производительность тестируемых элементов сети может оказаться недостаточной.
B) Нагруженная сеть. Это более интересный случай проверки производительности сервиса FTP для конкрентных сервера и клиента.
Однако при измерении критерия производительности в условиях, когда в сети работают и другие узлы и сервисы, возникают свои сложности - в сети может существовать слишком большое количество вариантов нагрузки, поэтому главное при определении критериев такого сорта - проведение измерений при некоторых типовых условиях работы сети. Так как трафик в сети носит пульсирующий характер и харакетристики трафика существенно изменяются в засисимости от времени дня и дня недели, то определение типовой нагрузки - процедура сложная, требующая длительных измерений на сети. Если же сеть только проектируется, то определение типовой нагрузки еще больше усложняется.
В примере 2 критерием производительности сети является время задержки между передачей кадра Ethernet в сеть сетевым адаптером клиентского компьютера 1 и поступлением его на сетевой адаптер сервера 3. Этот критерий также относится к критериям типа "время реакции", но соответствует сервису нижнего - канального уровня. Так как протокол Ethernet - протокол дейтаграммного типа, то есть без установления соединений, для которого понятие "ответ" не определено, то под временем реакции в данном случае понимается время прохождения кадра от узла-источника до узла-получателя. Задержка передачи кадра включает в данном случае время распространения кадра по исходному сегменту, время передачи кадра коммутатором из сегмента А в сегмент В, время передачи кадра маршрутизатром из сегмента В в сегмент С и время передачи кадра из сегмента С в сегмент D повторителем. Критерии, относящиеся к нижнему уровню сети, хорошо хактеризуют качества транспортного сервиса сети и являются более информативными для сетевых интеграторов, так как не содержат избыточную для них информацию о работе протоколов верхних уровней.
При оценке производительности сети не по отношению к отдельным парам узлов, а ко всем узлам в целом используются критерии двух типов: средно-взвешенные и пороговые.
Средно-взвешенный критерий представляет собой сумму времен реакции всех или некоторых узлов при взаимодействии со всеми или некоторыми серверами сети по определенному сервису, то есть сумму вида

где Tij - время реакции i-го клиента при обращении к j-му серверу, n - число клиентов, m - число серверов. Если усреднение производится и по сервисам, то в приведеном выражении добавится еще одно суммирование - по количеству учитываемых сервисов. Оптимизация сети по данному критерию заключается в нахождении значений параметров, при которых критерий имеет минимальное значение или по крайней мере не превышает некоторое заданное число.
Пороговый критерий отражает наихудшее время реакции по всем возможным сочетаниям клиентов, серверов и сервисов:

где i и j имеют тот же смысл, что и в предыдущем случае, а k обозначает тип сервиса. Оптимизация также может выполняться с целью минимизации критерия, или же с целью достижения им некоторой заданной величины, признаваемой разумной с практической точки зрения.
Чаще применяются пороговые критерии оптимизации, так как они гарантируют всем пользователям некоторый удовлетворительный уровень реакции сети на их запросы. Средне-взвешенные критерии могут дискриминировать некоторых пользователей, для которых время реакции слишком велико при том, что при усреднении получен вполне приемлемый результат.
Можно применять и болеее дифференцированные по категориям пользователей и ситуациям критерии. Например, можно поставить перед собой цель гарантированть любому пользователю доступ к серверу, находящемуся в его сегменте, за время, не превышающее 5 секунд, к серверам, находящимся в его сети, но в сегментах, отделенных от его сегмента коммутаторами, за время, не превышающее 10 секунд, а к серверам других сетей - за время до 1 минуты.
Критерии оптимизации ОС
Наблюдение за производительностью сетевой операционной системы любого сервера производится обычно для того, чтобы определить - достигнут ли максимум производительности по обслуживанию сетевых клиентов или нет? Для достижения этой цели в ОС предусматривается ряд средств, которые могут помочь сетевому администратору отобразить и зарегистрировать картину сетевой активности сервера. Эти средства собирают и записывают в файл статистику о работе сервера, на основании которой администратор может найти и исключить причину любой из возникших проблем.
Во многих современных операционных системах разработчики идут по пути исключения многих непродуктивных параметров системы, с помощью которых администраторы могут влиять на производительность ОС. Вместо этого в операционную систему встраиваются адаптивные алгоритмы, которые определяют рациональные параметры системы во время ее работы. С помощью этих алгоритмов ОС может оптимизировать свои параметры в отношении многих известных сетевых проблем динамически, автоматически перераспределяя свои ресурсы, и не привлекая к решению администратора.
Существуют разные критерии оптимизации производительности операционной системы. К числу наиболее распространенных критериев относятся:
Наибольшая скорость выполнения определенного процесса. Максимальное число задач, выполняемых процессором в единицу времени. Эта харакетристика называется также пропускной способностью компьютера. Она характеризует качество разделения ресурсов между несколькими одновременно выполняемыми процессами. Освобождение наибольшего количества оперативной памяти для наиболее приоритетных процессов, например, процесса, выполняющего функции файлового сервера или же для увеличения размера файлового кэша. Освобождение наибольшего количества дисковой памяти.
Обычно при оптимизации производительности ОС администратор начинает этот процесс при заданном наборе ресурсов. В общем случае одновременно улучшить все критерии производительности невозможно. Например, если целью является увеличение доступной оперативной памяти, то администратор может увеличить размер страничного файла, но это приведет к уменьшению доступного дискового пространства.
Если же нужно улучшить одновременно все критерии производительности, то нужно привлекать дополнительные ресурсы, например, более мощный процессор, дополнительную память или более емкий диск.
Методы аналитического, имитационного и натурного моделирования
Моделирование представляет собой мощный метод научного познания, при использовании которого исследуемый объект заменяется более простым объектом, называемым моделью. Основными разновидностями процесса моделирования можно считать два его вида - математическое и физическое моделирование. При физическом (натурном) моделировании исследуемая система заменяется соответствующей ей другой материальной системой, которая воспроизводит свойства изучаемой системы с сохранением их физической природы. Примером этого вида моделирования может служить пилотная сеть, с помощью которой изучается принципиальная возможность построения сети на основе тех или иных компьютеров, коммуникационных устройств, операционных систем и приложений.
Возможности физического моделирования довольно ограничены. Оно позволяет решать отдельные задачи при задании небольшого количества сочетаний исследуемых параметров системы. Действительно, при натурном моделировании вычислительной сети практически невозможно проверить ее работу для вариантов с использованием различных типов коммуникационных устройств - маршрутизаторов, коммутаторов и т.п. Проверка на практике около десятка разных типов маршрутизатров связана не только с большими усилиями и временными затратами, но и с немалыми материальными затратами.
Но даже и в тех случаях, когда при оптимизации сети изменяются не типы устройств и операционных систем, а только их параметры, проведение экспериментов в реальном масштабе времени для огромного количества всевозможных сочетаний этих параметров практичеки невозможно за обозримое время. Даже простое изменение максимального размера пакета в каком-либо протоколе требует переконфигурирования операционной системы в сотнях компьютеров сети, что требует от администратора сети проведения очень большой работы.
Поэтому, при оптимизации сетей во многих случаях предпочтительным оказывается использование математического моделирования. Математическая модель представляет собой совокупность соотношений (формул, уравнений, неравенств, логических условий), определяющих процесс изменения состояния системы в зависимости от ее параметров, входных сигналов, начальных условий и времени.
Особым классом математических моделей являются имитационные модели. Такие модели представляют собой компьютерную программу, которая шаг за шагом воспроизводит события, происходящие в реальной системе. Применительно к вычислительным сетям их имитационные модели воспроизводят процессы генерации сообщений приложениями, разбиение сообщений на пакеты и кадры определенных протоколов, задержки, связанные с обработкой сообщений, пакетов и кадров внутри операционной системы, процесс получения доступа компьютером к разделяемой сетевой среде, процесс обработки поступающих пакетов маршрутизатором и т.д. При имитационном моделировании сети не требуется приобретать дорогостоящее оборудование - его работы имитируется программами, достаточно точно воспроизводящими все основные особенности и параметры такого оборудования.
Преимуществом имитационных моделей является возможность подмены процесса смены событий в исследуемой системе в реальном масштабе времени на ускоренный процесс смены событий в темпе работы программы. В результате за несколько минут можно воспроизвести работу сети в течение нескольких дней, что дает возможность оценить работу сети в широком диапазоне варьируемых параметров.
Результатом работы имитационной модели являются собранные в ходе наблюдения за протекающими событиями статистические данные о наиболее важных характеристиках сети: временах реакции, коэффициентах использования каналов и узлов, вероятности потерь пакетов и т.п.
Существуют специальные языки имитационного моделирования, которые облегчают процесс создания программной модели по сравнению с использованием универсальных языков программирования. Примерами языков имитационного моделирования могут служить такие языки, как SIMULA, GPSS, SIMDIS.
Существуют также системы имитационного моделирования, которые ориентируются на узкий класс изучаемых систем и позволяют строить модели без программирования. Подобные системы для вычислительных сетей рассматриваются ниже в разделе 4.3.
Многофункциональное устройство Compas компании Microtest
В отличие от кабельного сканера, устройство Compas позволяет быстро решить большинство проблем, возникающих перед администратором сети, например, не только обнаружить место и причину нарушения работы кабельной системы, но и определить участки сети с наиболее напряженным трафиком, степень загруженности процессора сервера и некоторые другие параметры.
Достаточно нажать одну кнопку "DIAGNOSE" и Compas проведет серию необходимых тестов, не только определит причину неисправности, но и укажет возможные способы ее устранения.
Compas можно подключать в любом месте сети. Он сам определяет место включения и запускает соответствующие тесты. С помощью уникальной функции NetTap можно подключить Compas между любыми двумя сетевыми устройствами, например, между рабочей станцией и концентратором или файл-сервером и концентратором и с помощью функции NetTap анализировать трафик между любым сетевым устройством и концентратором. Данная функция позволяет тестировать работу концентраторов, использующих технологию SwitchedEthernet.
В качестве анализатора протоколов Compas позволяет проводить мониторинг сетевого трафика и определять неисправности на уровне протоколов. Compas определяет трафик, количество ошибок, сетевые устройства, создающие основной трафик, источники ошибок и широковещательных пакетов. Можно просматривать пики загрузки и ошибок в течение длительного периода. Compas распознает все протоколы, используемые в данном сегменте, в том числе: NovellIPX, IP, DECLAVC, DECnet, AppleTalkII (APP2), XeroxXNS, BanianVINES, ISO и ARP и определяет совокупный процент утилизации для каждого протокола.
В качестве кабельного сканера Compas позволяет проводить диагностику кабельной сети. Compas измеряет следующие параметры кабелей: NEXT, импеданс, уровень электромагнитных шумов и схему разводки кабеля. Имея два разъема RJ-45, Compas может тестировать даже кроссировочные кабели, часто являющиеся причиной неисправности сетей.
Compas показывает детальную информацию о файл-серверах с операционной системой NetWare с использованием CompasNetWareLoadableModule (NLM). Данный тест позволяет просматривать значения утилизации процессора, переполнения кэш-буферов, утилизации сервера, используемый фрейм и др. Можно использовать Compas для эмуляции файл-сервера или рабочей станции. Compas также позволяет тестировать очереди печати и распечатывать результаты всех тестов на сетевом принтере. Compas имеет один BNC и два RJ-45 разъема. Прибор автоматически определяет, к какому разъему подключен кабель.
Модели теории массового обслуживания
Используемые в настоящее время в локальных сетях протоколы канального уровня используют методы доступа к среде, основанные на ее совместном использовании несколькими узлами за счет разделения во времени. В этом случае, как и во всех случаях разделения ресурсов со случайным потоком запросов, могут возникать очереди. Для описания этого процесса обычно используются модели теории массового обслуживания.
Механизм разделения среды протокола Ethernet упрощенно описывается простейшей моделью типа M/M/1 - одноканальной моделью с пуассоновским потоком заявок и показательным законом распределения времени обслуживания. Она хорошо описывает процесс обработки случайно поступающих заявок на обслуживание системами с одним обслуживающим прибором со случайным временем обслуживания и буфером для хранения поступающих заявок на время, пока обслуживающий прибор занят выполнением другой заявки (рисунок 4.1). Передающая среда Ethernet представлена в этой модели обслуживающим прибором, а пакеты соответствуют заявкам.
Введем обозначения: l - интенсивность поступления заявок, в данном случае это среднее число пакетов, претендующих на передачу в среде в единицу времени, b - среднее время обслуживания заявки (без учета времени ожидания обслуживания), то есть среднее время передачи пакета в среде с учетом паузы между пакетами в 9.6 мкс, r - коэффициент загрузки обслуживающего прибора, в данном случае это коэффициент использования среды, r = lb.
В теории массового обслуживания для данной модели получены следующие результаты: среднее время ожидания заявки в очереди (время ожидания пакетом доступа к среде) W равно:


Рис. 4.1. Применение модели теории массового обслуживания M/M/1 для анализа трафика в сети Ethernet
Наблюдение за потреблением ресурсов процессора, дисков и памяти
Процессор
Так как процессор всегда выполняет некоторые команды, то теоретически коэффициент его использования всегда равен 100%. Однако в системе имеются так называемые "нити простоя", которые просто выполняют цикл ожидания следующего события для низкоуровневого кода ядра. Время выполнения этих нитей не учитывается при вычислении коэффициента использования в утилите PerformanceMonitor.
PerformanceMonitor характеризует использование процессоров объектами двух типов:
System - характеризует общую загрузку всех процессоров системы; Processor - характеризует загрузку конкретного процессора.
В однопроцессорной системе эти значения совпадают.
Для этих объектов имеются три счетчика, связанные с коэффициентом использования:
% [Total] PrivilegedTime - доля времени, которое процессор проводит в привилегированном режиме. % [Total] UserTime - доля времени, которое процессор проводит в пользовательском режиме. % [Total] Processortime - доля времени, которое процессор проводит, занимаясь полезной работой, то есть не в нитях простоя.
Если значение счетчика % ProcessorTime превышает 80%, то это говорит о том, что процессор не справляется с работой, и он должен быть заменен на более мощный (или же должен быть добавлен еще один процессор, если система многопроцессорная).
Аналогичные счетчики существуют и для объекта Process. В этом случае они отражают коэффициент использования процессора только нитями одного конкретного процесса. Кроме того, имеются и другие счетчики для характеристики работы процессоров, из которых наиболее важными являются следующие:
ProcessorQueueLength - длина очереди к процессору, равна количеству нитей, готовых к выполнению и стоящих в очереди к процессору.
Если в течение длительного времени средняя длина очереди превышает значение 2, то это говорит о том, что процессор является узким местом. Обычно значение этого счетчика равно 0.
Interrupt/sec - количество прерываний в секунду, характеризует интенсивность запросов обслуживания от устройств ввода-вывода.
Резкое увеличение значения этого счетчика без увеличения активности системы говорит об аппаратных проблемах. Счетчик Process: % ProcessorTime нужно использовать для отслеживания коэффициента использования процессора для всех процессов. Если более чем два процесса претендуют на большую часть процессорного времени, то необходимо заменить или добавить процессор.
Диск
При наблюдении за диском нужно учитывать, что среднее время доступа к данным для большинства дисков находится в пределах от 8 до 18 миллисекунд.
Статистика о работе дисковой подсистемы может помочь в достижении баланса рабочей нагрузки сетевого сервера. Если дисковая подсистема достаточно производительна, то это создает меньшую нагрузку на подсистему виртуальной памяти и программы будут выполняться быстрее. PerformanceMonitor поддерживает два типа объектов, которые содержат счетчики дисковой подсистемы:
PhysicalDisk - счетчики физического диска полезны для обнаружения неисправностей и планирования емкости. LogicalDisk - счетчики, генерирующие статистику о свободном пространстве на диске и идентифицирующие любой источник активности на физическом томе.
С производительностью диска тесно связаны два счетчика: DiskQueueLength - средняя длина очереди запросов к диску, и AverageDisksec/Transfer - среднее время выполнения одного запроса к диску.
На основании значений этих счетчиков можно вычислить такой важный показатель, как среднее время ожидания в очереди, которое хорошо отражает производительность дисковой подсистемы.
Среднее время ожидания в очереди = DiskQueueLengthxAverageDisksec/Transfer.
Обычно дисковые счетчики в системе отключены, чтобы не снижать ее производительности.
Память
Оптимизация памяти состоит в определении следующих параметров:
корректного значения размера физической памяти; корректного значения размера страничного файла; корректного распределения страничного файла.
Для определения корректного значения физической памяти необходимо выполнить два шага. Во-первых, решить, нужна ли дополнительная память.
Во-вторых, определить количество требуемой дополнительной памяти.
Решение о том, что дополнительная память нужна, принимается на основании количества страничных обменов, которые выполняет система. Если страничный обмен ведется интенсивно, то производительность существенно снижается.
Для того, чтобы определить, что страничный обмен ведется слишком интенсивно, нужно вычислить произведение:
Memory: Pages/sec x Logical Disk: Avg. Disk sec/Transfer,
где LogicalDisk относится к диску, на котором находится страничный файл PAGEFILE.SYS.
Это произведение равно доле времени доступа к диску, которое тратится на страничные обмены. Если эта доля больше 10%, то система нуждается в дополнительной памяти.
Следующий шаг состоит в определении количества дополнительной памяти. Эта величина определяется на основании значения счетчика Process: WorkingSet для каждого активного процесса в системе. Нужно по очереди завершать процессы в системе (начиная с процесса с самым большим значением рабочего набора) и следить за интенсивностью страничного обмена. После того, как интенсивность страничного обмена уменьшится до приемлемой величины, нужно найти суммарный объем памяти, потребляемой завершенными процессами, сложив их рабочие наборы. Этот объем и будет величиной требуемой дополнительной памяти.
Настройка параметров аппаратных и программных средств конечных узлов
Конечными узлами сети являются компьютеры, и от их производительности и надежности во многом зависят характеристики всей сети в целом. Компьютеры представляют собой не только центры обработки информации, они наравне со специальными коммуникационными устройствами несут обязанности по организации сетевого взаимодействия. Именно компьютеры являются теми устройствами в сети, которые реализуют протоколы всех уровней, начиная от физического и канального (сетевой адаптер и драйвер) и кончая прикладным уровнем (приложения и сетевые службы операционной системы).
Отсюда следует, что оптимизация компьютера включает две достаточно независимые задачи:
Во-первых, выбор таких параметров конфигурации программного и аппаратного обеспечения, которые бы обеспечивали оптимальные показатели производительности и надежности этого компьютера как отдельного элемента сети. Такими параметрами являются, например, тип используемого сетевого адаптера, размер файлового кэша, влияющий на скорость доступа к данным на сервере, применение того или иного уровня RAID, производительность дисков и дискового контроллера, быстродействие центрального процессора и т.п. Во-вторых, выбор таких параметров протоколов, установленных в данном компьютере, которые бы гарантировали эффективную и надежную работу коммуникационных средств сети. Так как компьютеры порождают большую часть кадров и пакетов, циркулирующих в сети, то многие важные параметры протоколов формируются программным обеспечением компьютеров, например, начальное значение поля TTL протокола IP, размер окна неподтвержденных пакетов, размеры используемых кадров.
2.5.1. Оптимизация операционных систем
Настройка подсистемы ввода-вывода рабочих станций и серверов
При обмене данными между двумя узлами сети информация проходит по следующему пути:
диск компьютера 1- оперативная память компьютера 1 - сетевой адаптер компьютера 1 - сеть - сетевой адаптер компьютера 2 - оперативная память компьютера 2 - диск компьютера 2.
Каждый этап выполнения операции обмена непосредственно влияет на общее время ее выполнения, а, следовательно, на пропускную способность сети. Поэтому оптимизировать необходимо не только параметры коммуникационных протоколов операционной системы компьютера и сетевого адаптера, но и параметры подсистемы ввода-вывода, отвечающей за доступ к диску.
Назначение максимального размера кадра в гетерогенной сети
Производительность сети может резко упасть из-за несогласованности максимального размера кадра в различных частях составной гетерогенной сети (рис. 2.4).
Если в каждой из частей такой сети используется свой протокол канального уровня со своим значением MTU, то проблема согласования разных значений MTU может возникнуть при передаче кадров из сети с большим значением MTU в сеть с меньшим значением MTU. Например, при передаче кадра размером в 2048 байт из сети FDDI в сеть Ethernet поле данных кадра FDDI не помещается в поле данных кадра Ethernet, максимальный размер которого равен 1500 байт.
Все существующие протоколы канального уровня локальных сетей не предусматривают возможности динамической фрагментации кадров с последующей их сборкой в исходный кадр. Функции фрагментации пакетов реализованы только в протоклах сетевого уровня, и то не во всех - из наиболее распространенных протоколов сетевого уровня только протокол IP поддерживает функцию динамической фрагментации. Поэтому при передаче кадров между сетями с различными значениями MTU возникающую проблему можно решить двумя способами - либо путем применения IP-маршрутизатора, который будет фрагментировать IP-пакеты таким образом, чтобы они умещались в MTU канального протокола (рис.2.4б), либо путем ограничения MTU во всех составных сетях до значения, равного минимальному MTU по всему набору протоколов, применяемых в гетерогенной сети (рис. 2.4в). В приведенном примере для этого администратору необходимо установить во всех сетях максимальный размер MTU, равный MTU сетей Ethernet, то есть 1500 байт.

Рис. 2.4. Проблема согласования максимального размера кадров в гетерогенной сети
Выбор одного из этих вариантов не очевиден, даже если оптимизация ведется только по критерию производительности, а стоимость решения во внимание не принимается. Маршрутизатор вообще работает не очень быстро, а выполнение фрагментации приводит к дополнительному замедлению продвижения пакетов. Поэтому при использовании оригинальных значений MTU в отдельных частях составной сети выигрыш в пропускной способности, полученный за счет использования пакетов большой длины, может быть сведен на нет замедлением продвижения пакетов маршрутизаторами, выполняющими операцию фрагментации.
Если скорость работы гетерогенной сети очень важна, то для достижения максимальной производительности необходимо провести натурное или имитационное моделирование двух подходов - с фрагментацией и с ограничением MTU.
Многие приложения и протоколы прикладного уровня умеют динамически находить в составной гетерогенной сети такое значение MTU, которое позволяет выполнять обмен данными с требуемым сервером. Например, клиентская часть файлового сервиса сетей NovellNetWare первоначально пытается установить связь с сервером с использованием максимально возможного размера кадра протокола той сети, к которой подключен клиентский компьютер. Если в течение заданного тайм-аута клиент не получает ответа, то он начинает уменьшать размер кадра до тех пор, пока ответы не начнут поступать.
В сети Internet для уменьшения перегрузок администраторы также начали широко применять подобную технику. Вместо динамической фрагментации используется предварительная процедура выяснения минимального значения MTU вдоль маршрута следования пакетов к серверу назначения. Эта процедура состоит в следующем. Пакеты IP, используемые в процедуре определения MTU, отправляются с установленным значением признака DF (Don'tFragment), который запрещает маршрутизаторам фрагментировать данный пакет даже при невозможности инкапсулировать его в кадр канального уровня очередной сети. В таком случае маршрутизаторы возвращают узлу-отправителю сообщение по протоколу ICMP "Требуется фрагментация, а бит DF установлен". Узел-отправитель, получив такое сообщение должен уменьшить размер отправляемого пакета и вновь попытаться передать его узлу назначения с установленным битом DF, и так до тех пор, пока сообщения о невозможности доставки не перестанут приходить от маршрутизаторов, находящихся на пути следования. После этого узел-отправитель может начать передачу данных кадрами такого размера, который не требует фрагментации ни в одной из составных сетей. Такая техника, называемая PathMTUDiscovery (исследование MTU на пути следования), принята в качестве стандартной в новой версии протокола IP - IPv6, c целью освобождения маршрутизаторов от дополнительной работы по фрагментации.
При использовании протоколов, не умеющих фраментировать пакеты, таких как IPX, техника исследования MTU является единственно возможной для организации устойчивой работы в составных гетерогенных сетях.
Несоответствие форматов кадров Ethernet
Ethernet - одна из самых старых технологий локальных сетей, имеющая длительную историю развития, в которую внесли свой вклад различиные компании и организации. В результате этого существует несколько модификаций даже такого основополагающего строительного блока протокола, как формат кадра. Использование различных форматов кадров может привести к полному отсутствию взаимодействия между узлами.
Всего имеется четыре популярных стандарта формата кадра Ethernet:
Кадр Ethernet DIX (иликадр Ethernet II); Кадр стандарта 802.3(или кадр Novell 802.2); Кадр Novell 802.3 (или кадр Raw 802.3); Кадр Ethernet SNAP.
Кадр стандарта EthernetDIX, называемый также кадром EthernetII, разработан компаниями Digital, Xerox и Intel (первые буквы названия компаний и дали название этому варианту Ethernet) при создании первых сетей Ethernet. Всего было выпущено две версии фирменного стандарта Ethernet, поэтому последняя, вторая версия этого стандарта также иногда указывается при обозначении варианта протокола Ethernet и соответственно его формата кадра. Часто в литературе именно этот вариант формата кадра называют кадром Ethernet, оставляя для международного стандарта технологии EthernetIEEE 802.3 обозначение 802.3.
Кадр стандарта EthernetDIX имеет следующий формат:
| Preambule -Преамбула (8) | Destination -Адрес назначения (6) | Source - Адрес источника (6) | Type - Тип (2) | Data - Данные (46-1500) | Frame Check Sequence (FCS) - Контрольая сумма (4) |
Поля Destination и Source содержат 6-ти байтные МАС-адреса узла назначения и источника, а поле Type - двухбайтный идентификатор протокола верхнего уровня, который поместил свои данные в поле данных Data. Для поля Type существуют стандартные значения числовых идентификаторов для всех популярных протоколов, используемых в локальных сетях. Например, протокол IP имеет числовой идентификатор 0800 и т.п. Эти значения можно найти в постоянно обновляемом RFC ( например, в RFC 1700), в котором уазаны все конкретные числовые значения, применяемые в протоколах сети Internet.
В стандарте IEEEEthernet 802.3 определен формат кадра Ethernet, близкий к формату EthernetDIX, но имеющий некоторые отличия:
| Preambule -Преам- була (8) | Destination -Адрес назначения (6) | Source - Адрес источника (6) | Length - Длина (2) | DSAP - Точка входа сервиса назначения (1) | SSAP - Точка входа сервиса источника (1) | Control - Управ- ление (1) | Data - Данные (46-1497) | FrameCheck Sequence (FCS) - Контрольная сумма (4) |
Поле Type встандарте 802.3 замененодвумядополнительнымиполями - DSAP (Destination Service Access Point) и SSAP (Source Service Access Point). Поле DSAP указывает сервис (протокол), которому предназначаются данные, а поле SSAP обозначают сервис (протокол), который отправил эти данные. Назначение этих полей то же, что и поля Type, но наличие двух полей позволяет организовать передачу данных между протоколами разного типа (правда, на практике это свойство никогда не используется). Однобайтовый формат полей SAP не позволил использовать в них те же числовые обозначения идентификаторов протоколов, которые прижились для кадров EthernetDIX, поэтому каждый протокол верхнего уровня имеет сейчас два идентификатора - один используется при инкапсуляции пакета протокола в кадр EthernetDIX, а второй - при инкапсуляции в кадр Ethernet 802.3.
Еще одним отличием кадра IEEE 802.3 является однобайтовое поле Control (Управление), которое предназначено для реализации режима работы с установлением соединенения. В поле Control должны помещаться номера кадров квитанций подтверждения доставки данных, необходимые для отработки процедур восстановления утерянных или искаженных кадров. На практике большинство операционных систем не использует этих возможностей кадра 802.3, ограничиваясь работой в дейтаграммном режиме (при этом значение поля Control всегда равно 03).
Так как стандарт IEEE делит канальный уровень на два подуровня - MAC и LLC, то иногда кадр Ethernet 802.3 также представляют как композиции двух кадров.
Кадр МАС- уровня включает поля преамбулы, адресов назначения и источника, поле длины и поле контрольной суммы, а кадр LLC содержит поля DSAP, SSAP, Control и поле данных (которое из-за введения новых трех однобайтовых полей имеет максимальную длину на 3 байта меньше).
Кадр Novell 802.3, который также называют кадром Raw 802.3 (то есть "грубый" или "очищенный" вариант стандарта 802.3) представляет собой кадр МАС-уровня без полей уровня LLC:
| Preambule -Преамбула (8) | Destination -Адрес назначения (6) | Source - Адрес источника (6) | Length - Длина (2) | Data - Данные (46-1500) | Frame Check Sequence (FCS) - Контрольная сумма (4) |
Кадр EthernetSNAP (SubNetworkAccessProtocol) активно используется в сетях TCP/IP для достижения совместимости числовых идентификаторов протоколов с теми, которые используются в кадре EthernetDIX. Кадр EthernetSNAP определен в стандарте 802.2H и представляет собой расширение кадра IEEE 802.3 путем введения двух дополнительных полей: 3-х байтового поля OUI (OrganizationUnitIdentifier) и двухбайтового поля Type. Поле Type имеет тот же формат и то же назначение, что и поле Type кадра EthernetDIX. Поэтому числовые значения идентификаторов протоколов, помещаемые в это поле кадра EthernetSNAP, совпадают со значениями, используемыми в кадрах EthernetDIX, и в этом весь смысл введения дополнительных полей заголовка SNAP. В поле OUI указывается код организации, которая определеяет стандартные значения для поля Type. Для протокола Ethernet такой организацией является комитет IEEE 802.3, и его код равен 00 00 00.
Наличие поля OUI позволяет использовать заголовок SNAP не только для протокола Ethernet, но и для других протоколов, которые контролируются другими организациями.
Если оборудование или операционная система настроены на поддержку какого-то одного формата кадра Ethernet, то они могут не найти взаимопонимания с другим узлом, который в свою очередь поддерживает также один формат кадра Ethernet, но другого типа. Результатом попыток взаимодействия таких узлов будет отбрасывание поступающих кадров, так как неверная интерпретация формата приведет к неверной контрольной сумме кадра.
Многие современные операционные системы и коммуникационное оборудование умеют одновременно работать с различными типами кадров, распознавая их автоматически. Распознавание идет по значению 2-х байтового поля, расположенного за адресом источника. Это поле может быть полем Type или Length. Числовые идентификаторы протоколов выбраны так, что значение поля Type будет всегда больше 1500, в то время как поле Length всегда содержит значение меньше или равное 1500. Дальнейшее отделение кадров EthernetSNAP от IEEE 802.3 проводится на основании значения полей DSAP и SSAP. Если присутствует заголовок SNAP, то поля DSAP и SSAP всегда содержат вполне определенный числовой идентификатор, зарезервированный за протоколом SNAP.
Автоматическое распознавание типа кадра избавляет пользователей сети от неприятных проблем, однако та же ОС или маршрутизатор могут быть настроены на поддержку только одного типа протоколов, и в этом случае проблема несовместимости может проявляться.
Сетевые анализаторы и средства мониторинга умеют автоматически различать форматы кадров Ethernet. Для задания условий захвата кадров, содержащих пакеты определенных протоколов верхнего уровня, анализаторы позволяют пользоваться как числовыми идентификаторами этих протоколов для полей SAP (DSAP и SSAP), так и числовыми идентификаторами для поля Type (имеющим также название EtherType).
В сетях TokenRing и FDDI всегда используются кадры стандартного формата, поэтому в этих сетях не возникают проблемы, связанные с несовместимостью форматов кадров.
Несоответствие разных способов маршрутизации в составной сети
Маршрутные таблицы, используемые маршрутизаторами для продвижения пакетов определенного сетевого протокола, всегда имеют одинаковую структуру, однако способ их получения может быть разным - ручной, по протоколу RIP, по протоколу OSPF или же еще по какому-нибудь другому протоколу динамического обмена информацией. Если в разных частях составной сети используются различные протоколы обмена маршрутной информации, то это может приводить к несогласованной работе маршрутизаторов и, следовательно, к отсутствию достижимости некоторых сетей для пользователей.
Каждый протокол обмена маршрутной информации использует свой формат служебных сообщений для распространения своих знаний о топологии сети. Поэтому, если не предпринимать дополнительных мер, то части сети, использующие разные протоколы маршрутизации, вообще не смогут автоматически взаимодействовать.
Для обеспечения совместимости протоколов маршрутизации разработаны специальные протоколы, которые передают маршрутные данные между различными частями сети в унифицированном формате. К таким протоколам относятся протокол EGP (ExteriorgatewayProtocol) и его более поздняя модификация BGP (BorderGatewayProtocol), разработанные и применяемые в сети Internet. Они могут переносить знания о сетях между протоколами RIP, OSPF, NLSP, IS-IS и другими.
Однако, только применение протоколов типа EGP или BGP не решает проблем работы гетерогенной в отношении протоколов маршрутизации сети. Знания о какой-либо сети могут поступить от разных частей сети, и, соответственно, от разных протоколов. В таких случаях для устойчивой работы сети нужно отдавать приоритет более надежно работающим в условиях изменения топологии протоколам типа "состояние связей", таких как OSPF, NLSP и IS-IS. Многие маршрутизаторы позволяют задавать приоритеты одних протоколов маршрутизации перед другими.
Для того, чтобы администратор мог "подправлять" таблицы маршрутизации, полученные автоматическим способом, наивысший приоритет обычно отдается маршрутам, заданным вручную. Однако, такие маршруты могут быть и причиной недостижимости некоторых сетей, так как вероятность внесения человеком ошибки всегда существует, причем она быстро повышается при увеличении размера сети. Использовании в сети масок неравной длины - также типичная причина недостижимости подсетей в результате недостаточно всестороннего анализа возможных маршрутов в сети.
В сетях TCP/IP ошибочные ситуации, фиксируемые маршрутизатором при невозможности передать пакет в сеть назначения, сообщаются конечному узлу служебным протоколом ICMP, пакеты которого обязательно нужно анализировать в больших сетях, использующих маршрутизаторы.
Несуществующий адрес и дублирование адресов
Отправка пакета по несуществующему адресу естественно не может привести к нормальному взаимодействию узлов в сети. Несуществующие адреса могут появиться в сети только в том случае, когда они хранятся постоянно в базе данных стека протоколов (например, в базе службы DNS стека TCP/IP или службы NDS сетей NetWarе). При этом может наступить момент, когда хранящийся адрес устареет и не будет соответствовать действительности.
В случае, когда адреса изучаются динамически, путем анализа пакетов служебного протокола, подобного SAP, использование несществующего адреса практически исключается, так как информация об адресе только что поступила от узла, которому этот адрес присвоен.
Серьезные проблемы в сети создает дублирование адресов, то есть наличие в сети двух узлов с одним и тем же адресом. Такая ситуация чаще всего приводит к недостижимости обоих узлов с одинаковым адресом, или же к нарушению нормальной работы всей сети, если дублируются не адреса узлов, а адреса сетей (IP или IPX). Проблема дублирования адресов характерна в большей степени для адресов верхних уровней, начиная с сетевого, где адреса назначаются администратором и поэтому могут повторяться в результате человеческих ошибок. Адреса канального уровня (МАС-адреса) присваиваются сетевым адаптерам, портам маршрутизаторов и агентам SNMP-управления компаниями-производителями, поэтому их дублирование маловероятно (только в случае переназначения адреса, что возможно путем его программирования).
Для обнаружения повторяющихся адресов в сетях необходимо использовать анализатор протоколов, настроив его на захват пакетов с определеным адресом сети и/или узла. Некоторые протоколы локальных сетей используют специальную процедуру для проверки дублирования адресов на канальном уровне (например, TokenRing, FDDI).
Оборудование для диагностики и сертификации кабельных систем
К оборудованию данного класса относятся сетевые анализаторы, приборы для сертификации кабелей, кабельные сканеры и тестеры. Прежде, чем перейти к более подробному рассмотрению этих устройств, приведем некоторые необходимые сведения об основных электромагнитных характеристиках кабельных систем.
Общая характеристика
Система имитационного моделирования сетей COMNETIII позволяет точно предсказывать производительность локальных, глобальных и корпоративных сетей. Система COMNETIII работает в среде Windows 95, WindowsNT и Unix.
COMNETIII предлагает использовать простой и интуитивно понятный способ конструирования модели сети, основанный на применении готовых базовых блоков, соответствующих хорошо знакомым сетевым устройствам, таким как компьютеры, маршрутизаторы, коммутаторы, мультиплексоры и каналы связи.
Пользователь применяет технику drag-and-drop для графического изображения моделируемой сети из библиотечных элементов:
Затем система COMNETIII выполняет детальное моделирование полученной сети, отображая результаты динамически в виде наглядной мультипликации результирующего трафика.
Другим вариантом задания топологии моделируемой сети является импорт топологической информации из систем управления и мониторинга сетей.
После окончания моделирования пользователь получает в свое распоряжение следующие харакетристики производительности сети:
Прогнозируемые задержки между конечными и промежуточными узлами сети, пропускные способности каналов, коэффициенты использования сегментов, буферов и процессоров. Пики и спады трафика как функцию времени, а не как усредненные значения. Источники задержек и узких мест сети.
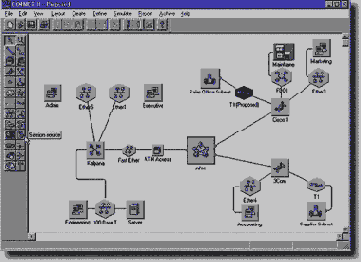
Рис. 4.1. Моделирование сети с помощью системы COMNETIII
Оценка необходимой общей производительности коммутатора
В идеальном случае коммутатор, установленный в сети, передает кадры между узлами, подключенными к его портам, с той скоростью, с которой узлы генерируют эти кадры, не внося дополнительных задержек и не теряя ни одного кадра. В реальной практике коммутатор всегда вносит некоторые задержки при передаче кадров, а также может некоторые кадры терять, то есть не доставлять их адресатам. Из-за различий во внутренней организации разных моделей коммутаторов, трудно предвидеть, как тот или иной коммутатор будет передавать кадры какого-то конкретного образца трафика. Лучшим критерием по прежнему остается практика, когда коммутатор ставится в реальную сеть и измеряеются вносимые им задержки и количество потерянных кадров. Однако, существуют несложные расчеты, которые могут дать представление о том, как коммутатор будет вести себя в реальной ситуации.

Рис. 2.13. Распределение трафика в сети, построенной на коммутаторе
Посмотрим, как можно оценить поведение коммутатора на примере сети, изображенной на рисунке 2.13.
Основой для оценки того, как будет справляться коммутатор со связью узлов или сегментов, подключенных к его портам, являются данные о средней интенсивности трафика между узлами сети. Для приведенного примера это означает, что нужно каким-то образом оценить, сколько в среднем кадров в секунду узел, поключенный к порту P1, генерирует узлам, подключенным к порту P2 (трафик P12), узлу, подключенному к порту P3 (трафик P13), и так далее, до узла, подключенного к порту P6. Затем эту процедуру нужно повторить для трафика, генерируемого узалми, подключенными к порту 2, 3, 4, 5 и 6. В общем случае, интенсивность трафика, генерируемого одним узлом другому, не совпадает с интесивностью трафика, генерируемого в обратном направлении.
Результатом исследования трафика будет построение матрицы трафика, приведенной на рисунке 2.14. Трафик можно измерять как в кадрах в секунду, так и в битах в секунду. Так как затем требуемые значения трафика будут сравниваться с показателями производительности коммутатора, то нужно их иметь в одних и тех же единицах.
Для определенности будем считать, что в рассматриваемом примере трафик и производительность коммутатора измеряются в битах в секунду.

Рис. 2.14. Матрица средних значений интенсивностей трафика
Подобную матрицу строят агенты RMONMIB (переменная TrafficMatrix), встроенные в сетевые адаптеры или другое коммуникационное оборудование.
Для того, чтобы коммутатор справился с поддержкой требуемой матрицы трафика, необходимо выполнение нескольких условий.
1. Общая производительность коммутатора должна быть больше или равна суммарной интенсивности передаваемого трафика:

где B - общая производительность коммутатора, Pij - средняя интенсивность трафика от i-го порта к j-му; сумма берется по всем портам коммутатора, от 1 до 6.
Если это неравенство не выполняется, то коммутатор заведомо не будет справляться с потоком поступающих в него кадров, и они будут теряться из-за переполнения внутренних буферов. Так как в формуле фигурируют средние значения интенсивностей трафика, то никакой, даже очень большой размер внутреннего буфера или буферов коммутатора не сможет компенсировать слишком медленную обработку кадров.
Суммарная производительность коммутатора обеспечивается достаточно высокой производительностью каждого его отдельного элемента - процессора порта, коммутационной матрицы, общей шины, соединяющей модули и т.п. Независимо от внутренней организации коммутатора и способов конвейеризации его операций, можно определить достаточно простые требования к производительности его элементов, которые являются необходимыми для поддержки заданной матрицы трафика. Перечислим некоторые из них.
2. Номинальная максимальная производительность протокола каждого порта коммутатора должна быть не меньше средней интенсивности суммарного трафика, проходящего через порт:

где Сk - номинальная максимальная производительность протокола k-го порта (например, если k-ый порт подддерживает Ethernet, то Сkравно 10 Мб/с), первая сумма равна интенсивности выходящего из порта трафика, а вторая - входящего.
Эта формула полагает, что порт коммутатора работает в стандартном полудуплексном режиме, для полнодуплексного режима величину Сkнужно удвоить.
3. Производительность процессора каждого порта должна быть не меньше средней интенсивности суммарного трафика, проходящего через порт. Условие аналогично предыдущему, но вместо номинальной производительности поддерживаемого протокола в ней должна использоваться производительность процессора порта.
4. Производительность внутренней шины коммутатора должна быть не меньше средней интенсивности суммарного трафика, передаваемого между портами, принадлежащими разным модулям коммутатора:

где Bbus - производительность общей шины коммутатора, а сумма

SijPij берется только по тем i и j, которые принадлежат разным модулям.
Эта проверка должны выполняться, очевидно, только для тех коммутаторов, которые имеют внутреннюю архитектуру модульного типа с использованием общей шины для межмодульного обмена. Для коммутаторов с другой внутренней организацией, например, с разделяемой памятью, несложно предложить аналогичные формулы для проверки достаточной производительности их внутренних элементов.
Приведенные условия являются необходимыми для того, чтобы коммутатор в среднем справлялся с поставленной задачей и не терял кадров постоянно. Если хотя бы одно из приведенных условий не будет выполнено, то потери кадров становятся не эпизодическим явлением при пиковых значениях трафика, а явлением постоянным, так как даже средние значения трафика превышают возможности коммутатора.
Условия 1 и 2 применимы для коммутаторов с любой внутренней организацией, а условия 3 и 4 приведены в качестве примера необходимости учета производительности отдельных.
Так как производители коммутаторов стараются сделать свои устройства как можно более быстродействующими, то общая внутренняя производительность коммутатора часто с некоторым запасом превышает среднюю интенсивность любого варианта трафика, который можно направить на порты коммутатора в соответствии с их протоколами.
Такие коммутаторы называются неблокирующими, что подчеркивает тот факт, что любой вариант трафика передается без снижения его интенсивности.
Однако, какой бы общей производительностью не обладал коммутатор, всегда можно указать для него такое распределение трафика между портами, с которым коммутатор не справится и начнет неизбежно терять кадры. Для этого достаточно, чтобы суммарный трафик, передаваемый через коммутатор для какого-нибудь его выходного порта, превысил максимальную пропускную способность протокола этого порта. В терминах условия 2 это будет означать, что второе слагаемое SiPik превышает пропускную способность протокола порта Сk. Например, если порты P4, Р5 и Р6 будут посылать на порт Р2 каждый по 5 Мб/c, то порт Р2 не сможет передавать в сеть трафик со средней интенсивностью 15 Мб/с, даже если процессор этого порта обладает такой производительностью. Буфер порта Р2 будет заполняться со скоростью 15 Мб/с, а опустошаться со скоростью максимум 10 Мб/с, поэтому количество необработанных данных будет расти со скоростью 5 Мб/с, неизбежно приводя к переполнению любого буфера конечного размера, а значит и к потере кадров.
Из приведенного примера видно, что коммутаторы могут полностью использовать свою высокую внутреннюю производительность только в случае хорошо сбалансированного трафика, когда вероятности передачи кадров от одного порта другим примерно равны. При "перекосах" трафика, когда несколько портов посылают свой трафик преимущественно одному порту, коммутатор может не справиться с поставленной задачей даже не из-за недостаточной производительности своих процессоров портов, а по причине ограничений протокола порта.
Коммутатор может терять большой процент кадров и в тех случаях, когда все приведенные условия соблюдаются, так как они являются необходимыми, но недостаточными для своевременного продвижения получаемых на приемниках портов кадров. Эти условия недостаточны потому, что они очень упрощают процессы передачи кадров через коммутатор.
Ориентация только на средние значения интенсивностей потоков не учитывает коллизий, возникающих между передатчиками порта и сетевого адаптера компьютера, потерь на время ожидания доступа к среде и других явлений, которые обусловлены случайными моментами генерации кадров, случайными размерами кадров и другими случайными факторами, значительно снижающими реальную производительность коммутатора. Тем не менее, использование приведенных оценок полезно, так как позволяет выявить случаи, когда применение конкретной модели коммутатора для конкретной сети заведомо неприемлемо.
Так как интенсивности потоков кадров между узлами сети оценить удается далеко не всегда, то в заключение этого раздела приведем соотношение, которое позволяет говорить о том, что коммутатор обладает достаточной внутренней производительностью для поддержки потоков кадров в том случае, если они проходят через все его порты с максимальной интенсивностью. Другими словами, получим условие того, что при данном наборе портов коммутатор является неблокирующим.
Очевидно, что коммутатор будет неблокирующим, если общая внутренняя производительность коммутатора B равна сумме максимальных пропускных способностей протоколов всех его портов Сk:
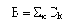
То есть, если у коммутатора имеется, например, 12 портов Ethernet и 2 порта FastEthernet, то внутренней производительности в 320 Мб/с будет достаточно для обработки любого распределения трафика, попавшего в коммутатор через его порты. Однако, такая внутренняя производительность является избыточной, так как коммутатор предназначен не только для приема кадров, но и для их передачи на порт назначения. Поэтому, все порты коммутатра не могут постоянно с максимальной скоростью только принимать информацию извне - средняя интенсивность уходящей через все порты коммутатора информации должна быть равна средней интенсивности принимаемой информации. Следовательно, максимальная скорость передаваемой через коммутатор информации в стабильном режиме равна половине суммарной пропускной способности всех портов - каждый входной кадр является для какого-либо порта выходным кадром.
В соответствии с этим утверждением, для нормальной работы коммутатора достаточно, чтобы его внутренняя общая производительность была равна половине суммы максимальных пропускных способностей протоколов всех его портов:

Поэтому, для коммутатора с 12 портами Ethernet и 2 портами FastEthernet вполне досточно иметь среднюю общую производительность в 160 Мб/с, для нормальной работы по передаче любых вариантов распределения трафика, которые могут быть переданы его портами в течение достаточно длительного периода времени.
Еще раз нужно подчеркнуть, что это условие гарантирует только то, что внутренние элементы коммутатора - процессоры портов, межмодульная шина, центральный процессор и т.п. - справятся с обработкой поступающего трафика. Несимметрия в распределении этого трафика по выходным портам всегда может привести к невозможности своевременной передачи трафика в сеть из-за ограничений протокола порта. Для предотвращения потерь кадров многие производители коммутаторов применяют фирменные решения, позволяющие "притормаживать" передатчики узлов, подключенных к коммутатору, то есть вводят элементы управления потоком не модифицируя протоколы портов конечных узлов.
Ограничение уровня широковещательного трафика в составных сетях с помощью техники спуфинга
Если уровень широковещательного трафика слишком высок, то уменьшить его можно двумя спсособами. Первый состоит в применении других протоколов, реже пользующихся широковещательностью, например, протоколов стека TCP/IP. Однако, это не всегда возможно, так как приложения или операционные системы могут уметь работать только с определенными протоколами. В этом случае можно воспользоваться другим способом - техника спуфинга.
Эта техника была развита производителями коммуникационного оборудования, объединяющего локальные сети по низкоскоростным глобальным каналам, а именно, производителями удаленных мостов и маршрутизаторов.
Техника спуфинга (spoofing - обман, надувательство) основана на снижении интенсивности передачи служебных сообщений по глобальному каналу, в то время как локальные сети получают эти сообщения с нужной периодичностью. Маршрутизаторы и удаленные мосты, поддерживающие спуфинг, генерируют служебные пакеты для подключенной к ним локальной сети с нужной интенсивностью сами, но от имени узлов, которые расположены в удаленной сети.
Например, пакеты SAP и RIP могут передаваться по низкоскоростному каналу только один раз - при установлении связи между центральным офисом и филиалом. В дальнейшем эти пакеты генерируются маршрутизатором локальной сети филиала, имитируя сообщения, которые должны были бы в исходном варианте исходить от реальных устройств центрального офиса. При изменениях в сетевой структуре в сеть передается обновленный пакет SAP/RIP, который снова начинает генерироваться маршрутизатором с тем периодом, который принят в данном протоколе, например, 60 секунд.
Существуют различные реализации спуфинга. Наиболее его простой вариант заключается в простом исключении некоторого количества циклов передачи служебных пакетов между сетями, когда, например, в другую сеть передается только каждый 5-й или 10-й пакет SAP, поступающий из исходной локальной сети.
Спуфинг можно применять и в локальной составной сети для уменьшения уровня широковещательного трафика.
Техника спуфинга может приводить не только к повышению, но и к снижению производительности сети. Это может произойти в том случае, когда пара взаимодействующих в режиме спуфинга маршрутизаторов или мостов имеют различные параметры настройки этого алгоритма. Так, если один маршрутизатор настрен на передачу каждого 10-го пакета SAP, а второй маршрутизатор ждет прихода нового пакета SAP через каждые 5 периодов его нормальной передачи, то второй маршрутизатор будет периодически считать связь с серверами первой сети утерянной и объявлять об этом во второй сети, что приведет к разрыву логических соединений между клиентами и серверами, находящимися в разных сетях, а, значит, и к потере производительности. К такому же результату приведет ситуация, когда один маршрутизатор поддерживает режим спуфинга, а второй - нет.
Оптимизация дискового кэша
Дисковый кэш - это область оперативной памяти, которая используется для временного буферного хранения блоков данных, хранящихся на диске. При обращении к данным на диске операционная система всегда сначала проверяет наличие этих данных в кэше оперативной памяти, а в случае их отсутствия выполняет реальную операцию обращения к диску. Поцент "попадания в кэш" при обращении к данным сервера существенно ускоряет работу сервера.
Операционные системы стараются хранить в кэше наиболее часто используемые в текущий момент времени данные. Для этого используются различные алгоритмы, основанные на запоминании частоты обращения к данным.
На эффективность работы дискового кэша влияют не только параметры алгоритма его заполнения и вытеснения, но и в первую очередь размер оперативной памяти, отводимой под кэш.
Для оптимизации размера дискового кэша используются различные средства мониторинга операционной системы, с помощью которых можно наблюдать процент попадания в кэш при выполнении обращений к данным сервера. Так как оперативная память - дефицитный ресурс компьютера, то необходимо найти ту границу размера кэша, при которой время доступа к дисковым данным становится меньше некоторой пороговой векличины, соизмеримой с временем выполнения других операций по обмену данными по сети - задержками, вносимыми сетевым адаптером и сетевой средой вместе с коммуникационным оборудованием.
Оптимизация режима работы протокола SMB
RAW - это "грубый" режим передачи данных протоколом SMB, с помощью которого можно уменьшить накладные расходы при передаче между клиентом и сервером больших массивов данных. В этом режиме минимизируется количество заголовков или кадров протокола SMB, передаваемых по сети.
В этом режиме редиректор создает и передает только один запрос SMB на каждый запрос приложения на ввод-вывод. Сервер принимает в режиме RAW запросы и отправляет данные либо непосредственно через файловый кэш, либо через специальные буферы размером в 64К, выделенные специально для режима RAW. Следовательно, при использовании режима RAW редиректор может подготовить и отослать один запрос на передачу данных объемом до 64 Кбайт.
Для поддержки режима RAW серверу необходимо иметь некоторое количество рабочих структур. Если при серьезной нагрузке набор таких структур оказывается исчерпанным, то некоторые клиентские запросы останутся невыполненными. Performance Monitor ведетподсчеттакихзапросоввсчетчиках Raw Reads Rejected/sec и Raw Writes Rejected/sec.
В базе Registry имеется переменная RAWWorkItems, которая определяет количество используемых сервером рабочих структур для хранения запросов и данных в режиме RAW. По умолчанию ее значение равно 4, но может быть увеличено до 512.
Редиректор использует режим передачи данных RAW при следующих условиях:
размер запрашиваемых приложением данных больше, чем 2 х (размер буфера сервера для операций чтения), либо 1.5 х (размер буфера сервера для операций записи); режим RAW не запрещен явным образом на сервере или клиенте; данные передаются по достаточно быстрому каналу; к одному серверу одновременно не обращается большое количество различных клиентских компьютеров; на сервере имеется достаточно оперативной памяти для размещения больших (до 64К) буферов режима RAW.
Во всех остальных случаях редиректор будет использовать режим передачи данных CORE.
В режиме CORE сервер использует в общем случае для выполнения одного запроса на проведение операции ввода-вывода несколько сообщений протокола SMB. Количество сообщений определяется размером буферов, используемых сервером для обслуживания запросов в этом режиме. По умолчанию размер буфера запроса равен 4356 байт. Следовательно, данные плюс служебная информация, пересылаемые одной операцией SMB, не должны превышать 4356 байтов. Служебная информация при операции чтения составляет 63 байта, а при операции записи - 64 байта. Оставшуюся часть буфера могут занимать данные, что дает 4293 байта при чтении с сервера и 4292 байта при записи на сервер.
Оптимизация сервера
Оптимизация WindowsNTServer подобна оптимизации WindowsNTWorkstation за несколькими исключениями:
Компоненты, поддерживающие пользовательский интерфейс, такие как мышь, клавиатура и видеоподсистема, меньше нуждаются в оптимизации, так как в большинстве случаев компьютер с WindowsNTServer не будет поддерживать интерактивный доступ пользователей. Серверные компоненты в данном случае более важны, чем редиректор. Если память является узким местом, то можно уменьшить память, выделенную для редиректора и увеличить для сервера. Если сервер выполняет приложения, написанные в модели клиент-сервер, такие как SQLServer, SNAServer или приложения, поддерживающие механизм RPC, то к диску будет обращаться меньше приложений, так что распределение файлов между несколькими дисками может оказаться весьма полезным.
Серверные компоненты WindowsNT можно сконфигурировать из панели Network утилиты ControlPanel. Имеется четыре общих установки:
MinimizeMemoryUsed - минимизация используемой памяти, изначально уменьшает до 10 максимальное число соединений с клиентами. Balance - баланс между потребляемой памятью и производительностью, поддерживается до 64 соединений. MaximizeThroughputForFileSharing - выделяется память для максимально поддерживаемого числа соединений (до 71 000 соединений). MaximizeThroughputForNetworkApplications - выделяется память для максимально поддерживаемого числа соединений, но для кэша выделяется меньше памяти, чем в предыдущем случае.
Процесс обработки сетевых запросов сервером можно наблюдать с помощью счетчика WorkItemShortage объекта Server, а влиять на этот процесс можно путем задания значений для двух переменных базы Registry - InitialWorkItems и MaximumWorkItems. WorkItem - это рабочая структура, которая используется сервером для постановки в очередь сетевых запросов от клиентов. Если сервер перегружен, то запрос от клиента может быть отклонен, так как в наличии нет свободной рабочей структуры для его фиксации. При возникновении такого события PerformanceMonitor наращивает значение счетчика WorkItemShortage. Администратор должен отслеживать этот счетчик и изменять значения переменных Registry, если это необходимо.
Два счетчика информируют администратора о том, что сервер достиг границы максимально доступной для него памяти:
PoolNonpagedFailures - количество попыток получения памяти из пула не охваченной страничным механизмом памяти, которые были неудачными из-за недостатка ресурсов. Эти события ясно указывают на то, что в компьютере не хватает физической памяти для работы сервера в данной конфигурации. PoolPagedFailures - количество попыток получения памяти из пула свободных страниц, которые были неудачными из-за недостатка ресурсов. Это говорит либо о недостатке физической памяти, либо о недостаточном размере страничного файла.
Оптимизация сервиса рабочей станции
Хотя редиректор WindowsNT (сервис Workstation) является самонастраивающимся, администратор должен следить за показаниями нескольких счетчиков:
Current Commands; Network Errors/sec; Remote Server Bottlenecks.
CurrentCommands - это количество команд, которые находятся в очереди к редиректору. Если это число больше, чем одна команда на один сетевой адаптер, то редиректор может быть узким местом в системе. Это может происходить по трем причинам:
Сервер, с которым взаимодействует редиректор, работает медленней, чем редиректор; Сеть испытывает перегрузки; Редиректор более загружен, чем адаптер;
Если выявлена перегруженность сети, можно ее несколько разгрузить за счет сегментации сети.
NetworkErrors/sec - это интенсивность возникновения серьезных сетевых ошибок, обнаруженных редиректором. Наличие таких ошибок говорит о том, что нужны дополнительные исследования. Целесообразно использовать для этой цели регистратор событий EventLog.
Производительность редиректора может ограничиваться за счет низкой производительности удаленных серверов, с которыми взаимодействует редиректор. В PerformanceMonitor есть два счетчика - ReadsDenied/sec и WritesDenied/sec, ненулевые значения которых свидетельствуют о том, что удаленные серверы испытывают трудности с выделением оперативной памяти. Необходимо проверить серверы, с которыми данный редиректор обменивается большими файлами. Если на них нет возможности увеличить объем памяти, используемой для режима RAW протокола SMB (этот режим рассматривается ниже), то на рабочей станции нужно запретить использование этого режима. Это делается с помощью установки переменных UseRawReads и UseRawWrites в состояние False.
Оптимизация сетевого оборудования
Хотя имеется очень мало возможностей для непосредственной оптимизации сетевого адаптера, но сам выбор хорошего адаптера может удвоить производительность WindowsNTServer. Для выбора сетевого адаптера имеются некоторые соображения. Во-первых, нужно выбирать такой адаптер, который использует всю разрядность шины ввода-вывода компьютера. Если компьютер имеет шину EISA, то нужен адаптер для этой шины, а не 8- или 16-разрядный адаптер.
Во-вторых, выбор сетевого адаптера включает выбор драйвера адаптера. Для WindowsNT нужно выбирать адаптер, сертифицированный для работы по спецификации NDIS 3.x. Такую информацию можно найти в списке WindowsNTHardwareCompatibility.
С сетевой активностью связано большое количество счетчиков. Все сетевые компоненты WindowsNT - Server, Redirector, протоколы NetBIOS, NWLink, TCP/IP - генерируют набор статистических параметров. Ненормальное значение сетевого счетчика часто говорит о проблемах с памятью, процессором или диском сервера. Следовательно, наилучший способ наблюдения за сервером состоит в наблюдении за сетевыми счетчиками в сочетании с наблюдением за такими счетчиками, как %ProcessorTime, %DiskTime и Pages/sec.
Например, если сервер показывает резкое увеличение счетчика Pages/sec одновременно с падением счетчика Totalbytes/sec, то это может говорить о том, что компьютеру не хватает физической памяти для сетевых операций.
Ошибки кадров Ethernet, связанные с длиной и неправильной контрольной суммой
Укороченные кадры (Shortframes). Это кадры, имеющие длину, меньше допустимой, то есть меньше 64 байт. Иногда этот тип кадров дифференцируют на два класса - просто короткие кадры (short), у которых имеется корректная контрольная сумма, и "коротышки" (runts), не имеющие корректной контрольной суммы. Наиболее вероятными причинами появления укороченных кадров являются неисправные сетевые адаптеры и их драйверы. Удлиненные кадры (Jabbers). Это кадры, имеющие длину, превышающую допустимое значение в 1518 байт с хорошей или плохой контрольной суммой. Удлиненные кадры являются следствием затянувшейся передачи, которая появляется из-за неисправностей сетвых адаптеров. Кадры нормальных размеров, но с плохой контрольной суммой (BadFCS или BadCRC) и кадры с ошибками выравнивания (alignment). Кадры с неверной контрольной суммой являются следствием большого количества причин - плохих адаптеров, помех на кабелях, плохих контактов, некорректно работающих портов повторителей, мостов, коммутаторов и маршрутизаторов. Ошибка выравнивания проявляется в нецелом количестве байт в кадре. Ошибка выравнивания всегда сопровождается ошибкой по контрольной сумме, поэтому некоторые средства анализа трафика не делают между ними различий. Кадры-призраки (ghosts) - являются результатом электро-магнитных наводок на кабеле. Они воспринимаются сетевыми адаптерами как кадры, не имеющие нормального признака начала кадра - 10101011. Кадры-призраки имеют длину более 72 байт, в противном случае они классифицируются как удаленные коллизии. Количество обнаруженных кадров-призраков в большой степени зависит от точки подключения сетевого анализатора. Причинами их возникновения являются петли заземления и другие проблемы с кабельной системой.
Ошибки кадров Ethernet в стандарте RMON
Стандарт RMON определяет следующие типы ошибок кадров Ethernet:
etherStatsCRCAlignErrors - общее число полученных пакетов, которые имели длину (исключая преамбулу) между 64 и 1518 байтами, не содержали целое число байт (alignmenterror) или имели неверную контрольную сумму (FCSerror).
etherStatsUndersizePkts - общее число пакетов, которые имели длину, меньше, чем 64 байта, но были правильно сформированы.
etherStatsOversizePkts - общее число полученных пакетов, которые имели длину больше, чем 1518 байт, но были тем не менее правильно сформированы.
etherStatsFragments - общее число полученных пакетов, которые не состояли из целого числа байт или имели неверную контрольную сумму, и имели к тому же длину, меньшую, чем 64 байта.
etherStatsJabbers - общее число полученных пакетов, которые не состояли из целого числа байт или имели неверную контрольную сумму, и имели к тому же длину, большую, чем 1518 байт.
etherStatsCollisions - наилучщая оценка числа коллизий на данном сегменте Ethernet.
Ошибки в кадрах, связанные с коллизиями
Ниже приведены типичные ошибки, вызванные коллизиями, для кадров протокола Ethernet:
Локальная коллизия (LocalCollision). Является результатом одновременной передачи двух или более узлов, принадлежащих к тому сегменту, в котором производятся измерения. Если сетевой анализатор не генерирует кадры, то в сети 10Base-T (на витой паре) локальные коллизии не фиксируются. Слишком высокий уровень локальных коллизий является следствием проблем с кабельной системой. Удаленная коллизия (RemoteCollision). Эти коллизии происходят на другой стороне повторителя (по отношению к тому сегменту, в котором установлен измерительный прибор). Так как концентратор 10Base-T является многопортовым повторителем, у которого каждый сегмент закреплен за одним узлом, то все измеряемые коллизии в сети 10Base-T являются удаленными (кроме тех случаев, когда анализатор сам генерирует кадры и может быть виновником коллизии). Не все анализаторы протоколов и средства мониторинга одинаковым образом фиксируют удаленные коллизии. Это происходит из-за того, что некоторые измерительные средства и системы не фиксируют коллизии, происходящие при передаче преамбулы. Поздняяколлизия (Late Collision). Это коллизия, которая происходит после передачи первых 64 байт кадра (по протоколу Ethernet коллизия должна обнаруживаться при передаче первых 64 байт кадра). Результатом поздней коллизии будет пакет, который имеет длину более 64 байт и содержит неверное значение контрольной суммы. Этот пакет обязательно был сгенерирован в локальном сегменте. Чаще всего это указывает на то, что сетевой адаптер, являющийся источником конфликта, оказывается не в состоянии правильно прослушивать линию и поэтому не может вовремя остановить свою передачу.
Основные электромагнитные характеристики кабельных систем
Основными электрическими характеристиками, влияющими на работу кабеля, являются: затухание, импеданс (волновое сопротивление), перекрестные наводки двух витых пар и уровень внешнего электромагнитного излучения.
Перекрестные наводки между витыми парами или NearEndCrosstalk (NEXT) - представляют собой результат интерференции электромагнитных сигналов, возникающих в двух витых парах. Один из кабелей витой пары является передающим, а второй - приемным. При прохождении сигнала по одному из кабелей, например передающему, в приемном кабеле возникают перекрестные наводки. Величина NEXT зависит от частоты передаваемого сигнала - чем выше величина NEXT, тем лучше (для категории 5 NEXT должен быть не менее 27 Дб при частоте 100 Мгц, для кабеля категории 3 на частоте 10 МГц NEXT должен быть не менее 26 Дб). Затухание (Attenuation) - представляет собой потерю амплитуды электрического сигнала при его распространении по кабелю. Затухание имеет два основных источника: электрические характеристики кабеля и поверхностный эффект. Последний объясняет зависимость затухания от частоты. Затухание измеряется в децибелах на метр. Для кабеля категории 5 при частоте 100 Мгц затухание не должно превышать 23.6 Дб на 100 м, а для кабеля категории 3, применяемого по стандарту IEEE 802.3 10BASE-T, допустимая величина затухания на сегменте длиной 100 м не должна превышать 11,5 Дб при частоте переменного тока 10 МГц. Импеданс (волновое сопротивление) - это полное (активное и реактивное) сопротивление в электрической цепи. Импеданс измеряется в омах и является относительно постоянной величиной для кабельных систем. Для неэкранированной витой пары наиболее часто используемые значения импеданса - 100 и 120 Ом. Характерные значения импеданса для сетей стандарта Ethernet на коаксиальном кабеле составляют 50 Ом, а для сетей стандарта Arcnet - 93 Ом. Резкие изменения импеданса по длине кабеля могут вызвать процессы внутреннего отражения, приводящие к возникновению стоячих волн. Рабочая станция, подключенная к кабелю вблизи узла стоячей волны, не сможет получать адресованные ей сообщения. Активное сопротивление - это сопротивление постоянному току в электрической цепи.
В отличие от импеданса активное сопротивление не зависит от частоты и возрастает с увеличением длины кабеля. Для неэкранированной витой пары категории 5 активное сопротивление не должно превышать 9.4 Ом на 100 м. Емкость - это свойство металлических проводников накапливать энергию. Два электрических проводника в кабеле, разделенные диэлектриком, представляют собой конденсатор, способный накапливать заряд. Емкость является нежелательной величиной, поэтому ее следует делать как можно меньше. Высокое значение емкости в кабеле приводит к искажению сигнала и ограничивает полосу пропускания линии. Для кабельных систем категории 5 значение емкости не должно превышать 5.6нФ на 100 м. Уровень внешнего электромагнитного излучения, или электрический шум- это нежелательное переменное напряжение в проводнике. Электрический шум бывает двух типов: фоновый и импульсный. Электрический шум можно также разделить на низко-, средне- и высокочастотный. Источниками фонового электрического шума являются в диапазоне до 150 КГц линии электропередачи, телефоны и лампы дневного света; в диапазоне от 150 КГц до 20 Мгц компьютеры, принтеры, ксероксы; в диапазоне от 20 Мгц до 1 ГГц - телевизионные и радиопередатчики, микроволновые печи. Основными источниками импульсного электрического шума являются моторы, переключатели и сварочные агрегаты. Электрический шум измеряется в мВ. Кабельные системы на витой паре не сильно подвержены влиянию электрического шума (в отличие от влияния NEXT).
Основные задачи оптимизации локальных сетей
Если вы хотите, чтобы ваша сеть работала самым эффективным образом, то вам придется решить для себя следующие задачи:
1. Cформулировать критерии эффективности работы сети. Чаще всего такими критериями служат производительность и надежность, для которых в свою очередь требуется выбрать конкретные показатели оценки, например, время реакции и коэффициент готовности, соответственно.
2. Определить множество варьируемых параметров сети, прямо или косвенно влияющих на критерии эффективности. Эти параметры действительно должны быть варьируемыми, то есть нужно убедиться в том, что их можно изменять в некоторых пределах по вашему желанию. Так, если размер пакета какого-либо протокола в конкретной операционной системе устанавливается автоматически и не может быть изменен путем настройки, то этот параметр в данном случае не является варьируемым, хотя в другой операционной системе он может относится к изменяемым по желанию администратора, а значит и варьируемым. Другим примером может служить пропускная способность внутренней шины маршрутизатора - она может рассматриваться как параметр оптимизации только в том случае, если вы допускаете возможность замены маршрутизаторов в сети.
Все варьируемые параметры могут быть сгруппированы различным образом. Например, параметры отдельных конкретных протоколов (максимальный размер кадра протокола Ethernet или размер окна неподтвержденных пакетов протокола TCP) или параметры устройств (размер адресной таблицы или скорость фильтрации моста, пропускная способность внутренней шины маршрутизатора). Параметрами настройки могут быть и устройства, и протоколы в целом. Так, например, улучшить работу сети с медленными и зашумленными глобальными каналами связи можно, перейдя со стека протоколов IPX/SPX на протоколы TCP/IP. Также можно добиться значительных улучшений с помощью замены сетевых адаптеров неизвестного производителя на адаптеры BrandName.
3. Определить порог чувствительности для значений критерия эффективности. Так, производительность сети можно оценивать логическими значениями "Работает"/ "Не работает", и тогда оптимизация сводится к диагностике неисправностей и приведению сети в любое работоспособное состояние.
Грубая настройка во многом похожа на приведение сети в работоспособное состояние. Здесь также обычно задается некоторое пороговое значение показателя эффективности и требуется найти такой вариант сети, у которого это значение было бы не хуже порогового. Например, нужно настроить сеть так, чтобы время реакции сервера на запрос пользователя не превышало 5 секунд.
3. Тонкая настройка параметров сети (собственно оптимизация). Если сеть работает удовлетворительно, то дальнейшее повышение ее производительности или надежности вряд ли можно достичь изменением только какого-либо одного параметра, как это было в случае полностью неработоспособной сети или же в случае ее грубой настройки. В случае нормально работающей сети дальнейшее повышение ее качества обычно требует нахождения некоторого удачного сочетания значений большого количества параметров, поэтому этот процесс и получил название "тонкой настройки".
Даже при тонкой настройке сети оптимальное сочетание ее параметров (в строгом математическом понимании термина "оптимальность") получить невозможно, да и не нужно. Нет смысла затрачивать колоссальные усилия по нахождению строгого оптимума, отличающегося от близких к нему режимов работы на величины такого же порядка, что и точность измерений трафика в сети. Достаточно найти любое из близких к оптимальному решений, чтобы считать задачу оптимизации сети решенной. Такие близкие к оптимальному решения обычно называют рациональными вариантами, и именно их поиск интересует на практике администратора сети или сетевого интегратора.
Поиск неисправностей в сети - это сочетание анализа (измерения, диагностика и локализация ошибок) и синтеза (принятие решения о том, какие изменения надо внести в работу сети, чтобы исправить ее работу).
Анализ - определение значения критерия эффективности (или, что одно и то же, критерия оптимизации) системы для данного сочетания параметров сети. Иногда из этого этапа выделяют подэтап мониторинга, на котором выполняется более простая процедура - процедура сбора первичных данных о работе сети: статистики о количестве циркулирующих в сети кадров и пакетов различных протоколов, состоянии портов концентраторов, коммутаторов и маршрутизаторов и т.п.
Далее выполняется этап собственно анализа, под которым в этом случае понимается более сложный и интеллектуальный процесс осмысления собранной на этапе мониторинга информации, сопоставления ее с данными, полученными ранее, и выработки предположений о возможных причинах замедленнной или ненадежной работы сети. Задача мониторинга решается программными и аппаратными измерителями, тесторами, сетевыми анализаторами и встроенными средствами мониторинга систем управления сетями и системами. Задача анализа требует более активного участия человека, а также использования таких сложных средств как экспертные системы, аккумулирующие практический опыт многих сетевых специалистов. Синтез - выбор значений варьируемых параметров, при которых показатель эффективности имеет наилучшее значение. Если задано пороговое значение показателя эффективности, то результатом синтеза должен быть один из вариантов сети, превосходящий заданный порог. Приведение сети в работоспособное состояние - это также синтез, при котором находится любой вариант сети, для которого значение показателя эффективности отличается от состояния "не работает". Синтез рационального варианта сети - процедура чаще всего неформальная, так как она связана с выбором слишком большого и очень разнородного множества параметров сети - типов применяемого коммуникационного оборудования, моделей этого оборудования, числа серверов, типов компьютеров, используемых в качестве серверов, типов операционных систем, параметров этих опрационных систем, стеков коммуникационных протоколов, их параметров и т.д. и т.п. Очень часто мотивы, влияющие на выбор "в целом", то есть выбор типа или модели обрудования, стека протоколов или операционной системы, не носят технического характера, а принимаются из других соображений - коммерческих, "политических" и т.п. Поэтому формализовать постановку задачи оптимизации в таких случаях просто невозможно. В данной книге основное внимание уделяется этапам мониторинга и анализа сети, как более формальным и автоматизируемым процедурам.В тех случаях, когда это возможно, в книге даются рекомендации по выполнению некоторых последовательностей действий по нахождению рационального варианта сети или приводятся соображения, облегчающие его поиск.
Особенности X Enterprise LANMeter
Серия 68XEnterpriseLANMeter включает модель 680, поддерживающую технологию TokenRing, модель 682 для сетей Ethernet и модель 685, поддерживающую как Ethernet, так и TokenRing.
EnterpriseLANMeter представляет собой первое в мире портативное средство, поддерживающее протокол SNMP, что позволяет ему обнаруживать причины отказа в сети за пределами локального сегмента, к которому подключен этот прибор. Поддерживаются базы управляющей информации MIBI, MIBII и RMON.
Инструментальные средства EnterpriseLANMeter поддерживают стек протоколов TCP/IP, а также другие протоколы, используемые в сетевых операционных системах NovelNetWare, ВаnуаnVINES, WindowsNT, WindowsforWorkgroups, Windows 95, IBMLANServer и OS/2.
LANMeter сводит к минимуму возможные отказы вносимые новыми компонентами сети проверяя работоспособность сетевых интерфейсных карт, кабелей, концентраторов и устройств сетевого доступа (MAU - MediaAccessUnit) перед их установкой в сеть. Он позволяет также с помощью ряда специальных тестов убедиться в правильности соединений и наличии доступа к сетевым ресурсам через локальные и корпоративные подключения.
LANMeter быстро выявляет причины возникновения наиболее распространенных для сетей Ethernet и TokenRing видов неисправностей и определяет местонахождение повреждений кабельной проводки или некорректно работающих устройств.
LANMeter предоставляет пользователю удобный и интуитивно понятный интерфейс, основанный на системе меню. Графический интерфейс пользователя использует 10-строчный жидкокристаллический дисплей и индикаторы состояния на светодиодах, извещающие пользователя о наиболее общих проблемах наблюдаемых сетей. Имеется обширный файл подсказок оператору с уровневым доступом в соответствии с контекстом. Информация о состоянии сети представляется таким образом, что пользователи любой квалификации могут ее быстро понять.
